当拿到一个数据集时,你通常会怎么做?你脑子里好不容易蹦出的那个答案正确吗?这个问题或许能让不少人尴尬。我们循序渐进地来回答这个问题。我们将遵循这样的顺序:
数据源质量→数据类型→数据集质量→平均水平→数据分布→量变关系→多维交叉
。通过这个系列的5篇内容,我希望你拿到任何数据集的时候都不蒙圈,都能有条不紊地开始工作。
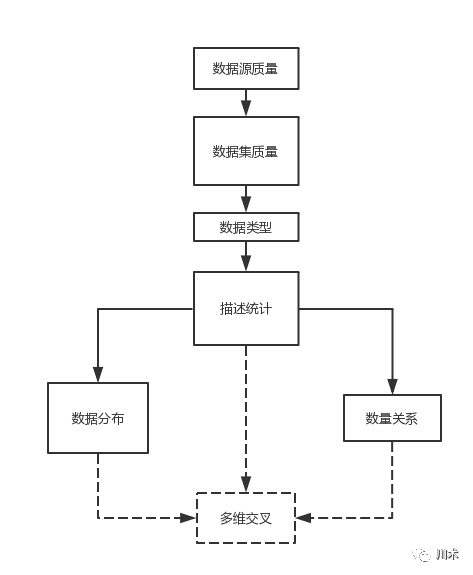
图
4- 14
:数据认知的一般流程
无数次血的教训告诉我,在拿到数据集后,花再多的精力去审核数据源的质量都不为过。数据源,分为两部分:一部分是数据库中的表,包括你自己取数的表和别人提供的数据的来源表;另一部分是取数代码,一般是SQL代码。
对于取数来源的表,我们一定要不厌其烦地明确如下几个问题:
1.表中的字段有没有在近期改动?做了什么样的改动?
2.表中的字段是不是名副其实的字段?
3.该表谁负责维护?有没有定期维护?
4.该表是否是中间表?它的字段内容是从哪里来的?
5.该表是以什么样的频率刷新数据?
我相信,为了保障数据源的质量,这5个问题是不够的,你一定还会碰到各种各样匪夷所思的错误。只是希望,我的提醒能都让大家少踩坑。尤其在互联网公司,数据质量真的是老大难的问题。
尤其需要警惕的是数据仓库中的中间表
,即由其他表合成而来的表。这类表的质量往往很难保证。一方面,这些表有可能是某个短期需求的产物,做完后没有人维护;另一方面,中间表之间往往存在多层的引用,即某张中间表中某个字段的来源是另一张中间表,甚至出现交叉引用,这样表里面字段的质量就极难保证了。如何解决这个问题?我暂时没有很好的办法。
对于取数代码,我犯过的错误有以下一些:
-
限制条件写错。限制条件的错误往往出现在多次使用的代码中。粗心写错的情况我羞于多说,我们讲一些可避免的系统性错误。有些高频使用的代码,我们总是需要根据不同的业务方需求,去临时地改一些限制条件,而有些限制条件是相互关联的,改了一个没改另一个,导致取得的数据不准确。还有更多的情况是我们偷懒,改动过的代码没有另行保存,而是覆盖了原来的代码,当下回要启用这原来的一段代码时,忘记了之前改过,导致取数的错误。
-
串表混乱。在跨多表查询时,我们没有清晰地思路,一会儿leftjoin,一会儿inner join,导致合成的宽表七零八落,由此汇总而出的数据自然问题百出。
-
取出多余的字段,造成计算时的准确度降低。许多伙伴在跨表取数时,都习惯于使用“select * from”,即把某个表的字段全部取出,然后从合并好的表中汇总数据。我不敢说这是个坏习惯,毕竟要记清楚每张表里的字段确实不容易,这样的方式写代码速度会快。但问题是,这样取数不仅使得运算负荷增加,更使得在数据汇总的时候容易混乱,也会增加其他成员的学习成本。另外,许多表的字段名也许长得非常像甚至是一样的,若你没有设置好别名,很容易出错。
-
计算方式错误。这往往出现在需要做一些汇总和计算的取数代码中。比如没有去重,漏加了某个字段,字段间的单位没有统一,多项式计算时括号位置出错,数据区间的首位开闭的关系出错等等。细细数来真的是非常非常多。所以,在审核别人的SQL代码时,尤其要注意这个方面。
-
对特殊值没有进行处理。这一部分理论上是该在“数据集”质量中讨论。但现在取数的量级越来越大,我们往往都在取数时就进行了简单的汇总操作。最典型的就是计算算术平均数。但若数据中有空值,或者有异常大(异常小)的值,算术平均数就会失真。因此我们习惯在sql中就对一些特殊情况进行
排除。若没有排除一些极端情况,你取出的数据质量或许就不会高。
无论如何,审核数据源的质量是绝对不能跳过的一个步骤。举个常见的类比,数据源的质量是1,其他后面的所有分析步骤都是0。
对数据源的审核就像做一个判断题,是0就需要返工重新取数,是1就可以继续。而对于数据集的质量,像做一个多项选择题,你需要逐步勾选:
-
处理数据集中的垃圾(乱码、格式混乱、特殊符号等)
-
处理空值
-
处理异常值
-
处理异常字段
-
统一数据类型和单位
以上5个步骤基本上涵盖了数据集质量提升的工作。有的伙伴会说,这个和数据认知有什么关系?当然有关系。比如给你一张照片,你当然要把照片表面的灰层去掉,将缺失的像素填上,将马赛克休掉,将色彩修正后,才能看清楚照片的全貌。
当你满怀期待的打开一个Excel表,却发现里面充满了乱码时,心情一定无比地纠结。如果见到大面积的乱码,那基本上是文本解码的问题。有三条路径去解决:
-
你要看看取数的工具里是否可以设置导出的文本格式,比如将utf-8改为gb2312。
-
你需要找到一些技术小伙伴,帮助解决文本编码的问题。
-
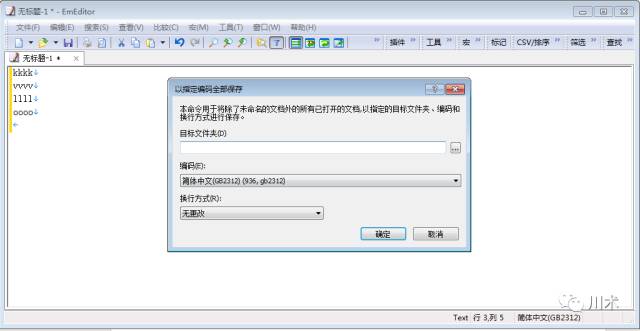
若谁都帮不了你,只能自己寻找工具解决。推荐一款文本处理工具EmEditor,它体积小功能强大,至少能满足我所有的文本处理需求。若遭遇乱码问题,你可以点击“文件”选项卡中的“以指定编码全部保存”按钮,将文本存为系统可识别的格式(utf-8或者gb2312)。这个工具不是免费的,但非常便宜,一年才40美金左右。在这种诱人的价格下,我还是会坚决地抵制盗版。
-
对于格式混乱,我并没有特别统一的解决办法。大家是不是会遇到这样的情况:某个从数据库中导出的表,里面的内容怎么看怎么别扭,需要鼠标双击以后,才能进行正常的编辑并修改格式;这种单元格的右上角有时会出现绿色的小标签;我一般采取的方法是选择这部分数据,复制后,在另一个空白的区域进行“选择性粘贴”,并选择“选择性粘贴”中的“加”运算方式,这样才能批量解决格式混乱的问题。也许大家有更好的解决方式,我这里就不多说了。对于特殊符号呢,我一般会采用“替换”功能,将某个特殊符号批量地替换为空。但如何特殊符号特别多,且五花八门时,我建议你就不要手动处理了,重新取数或者将它交给技术大牛来处理。
退一步说,如果发现数据集中的垃圾数据数量有限,直接将他们整行删除或许是最经济的办法。
虽然很多时候我们会删除空值,但千万小心,若空值存在的行数占到了总行数的1%以上,千万不要莽撞地删除了,需要仔细得处理它们。为什么是1%呢?这只是我的一个拍脑袋的决定,并不严谨。
空值处理的第一种思路是“
用最接近的数据来替换它
”。这并不是意味着拿它相邻的单元格来替换,而是你需要寻找除了空的这个单元格,哪一行数据在其他列上的内容与存在空值的这行数据是最接近的,然后用该行的数据进行替换。这种方式较为严谨,但也比较费事。
第二种思路是针对数值型的数据,若出现空值,我们可以用该列数值型数据的
平均值进行替换
。如果条件允许,我建议采用众数进行替换,即该列数据当中出现次数最多的那个数字。若不能寻找出众数,就用中位数。算术平均数是最不理想的一种选择。
第三种思路是
合理推断
。这一般会用在时间序列数据或者有某种演进关系的数据中。比如,用移动平均数替换空值,或者由其他变量与该变量的回归关系,用其他非空变量通过回归公式来计算出这个空值。
实在处理不了的空值,也可以先放着,不必着急删除。因为有时候会出现这样两种情况:
一是你的后续运算可以跳过空值进行;二是在异常值或者异常字段的处理中,空值所在的这行正好被删除了。
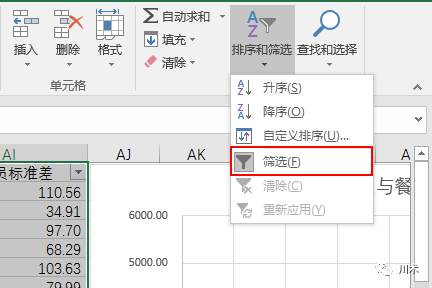
所谓异常值,其实是很主观的一种判断。我希望大家养成这样一个好习惯:拿到数据集,数据源检查通过且空值做了预处理后,对数据集启动“筛选”功能,点开每列的筛选项看一看,往往你就能发现那些异常数据,比如
数值特别夸张,文本特别长,NULL值,不匹配的数据类型
等等;选择这些异常内容后,看他们的行数是否很多,若不多,直接删除,若很多,需要检查这些异常值产生的原因。
对于数值型的数据,在统计学上,异常值的判断是有方法的。比如,该数字与序列均值的差大于3倍标准差,或者该数字减去四分位数的差大于3倍的四分卫极差。遇见如此拗口的表述,你应该头晕了吧。因此,我极少使用这类规则来处理异常值,因为当你向别人说明时,就像在噩梦中挣扎。以我的经验,在数据量不大的情况下,异常值的判断还是同上文所说,通过筛选功能来人工地处理比较靠谱。
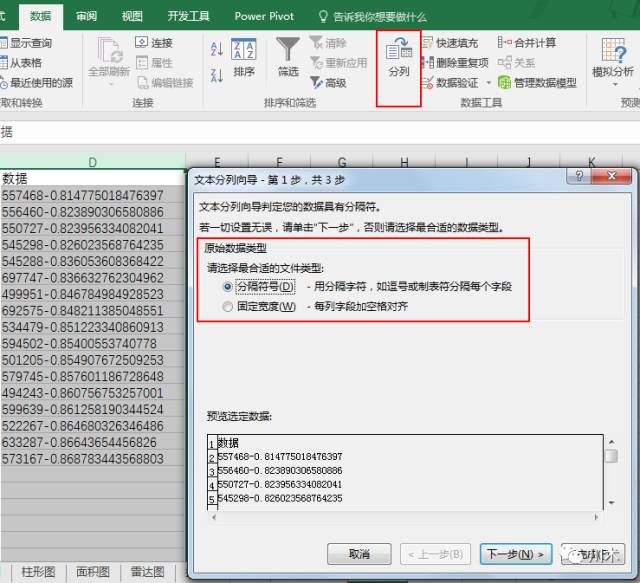
何为异常字段?我遇到的有很多,最典型的或许是多个字段不知为何并成了一个字段。这个时候往往需要使用Excel“数据”板块中的“分列”功能。如下图,在分列功能中,我们可以选择按分割符号或者按固定宽度进行分列。顾名思义,按分割符号就是按列中每个单元格里都存在的一个符号,将单元格分为符号前后两个部分,形成两列;而按固定宽度就是固定单元格的字符宽度,按这个宽度的前后将数据分开。当然,我们也可以选择将一列分成多列。分列的具体细节就不多说了,只要上手去使用,里面的各个参数设置都能马上理解。
你可别小看异常值的处理,往往在这个过程中我们不仅仅是让数据集更干净了,哪些被剔除的异常数据,有时也非常有价值。这个过程其实可以理解成一个数据挖掘过程。









