高可用英文翻译为”High Availability”,从字面上理解就是要做到服务的full-time的持续可用,但老实说,要做到full-time是不现实的,因为能够影响系统服务可用性的因素实在是太多了,除了软件BUG、硬件故障外还包括系统所依赖的一些第三方服务(如运营商提供的带宽),甚至还包括天灾人祸等;因此我理解所谓的高可用意味着”更少的停服时间”,而工业界也有一套测量系统可用性的标准,即大家所熟知的SLA(Service Level Agrement),也就是几个9的可用性(如下表):
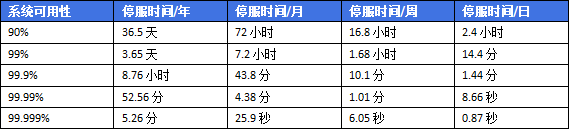
在工业应用场景中,如当下做在线服务的各大互联网公司,号称7*24小时的不间断服务,想想如果只是达到一个9的可用性将会是一种什么样的灾难;而要做到5个9的可用性就意味着全年只有一次服务宕机,而且得在5分钟左右就恢复,其中的难度也是不言而喻的,我想只是采用技术手段不足以做到,还需要通过一整套完备严谨的工程管理防范及配套工具、优秀工程运维人员等。
云计算号称互联网公司的水和电,高可用犹如云服务商的生命线,而云数据库作为该领域的一项重要服务更是接受着不同维度的考验,因为云端成千上万个用户数据库实例所面临的问题会更加五花八门;下面将先介绍Mysql领域几个典型的高可用解决方案,分析其中的关键技术及适用场景,并在此基础上介绍和分享UDB的高可用方案。
数据库服务和很多工业服务在高可用技术方案是相通的,为了实现高可用首先实现服务的”冗余”,即服务的集群化,如果服务有冗余备份,宕机后还有其它备份服务(热备和冷备)可以顶上,所以实现数据库服务的”冗余”也是高可用数据库的核心准则;而有了”冗余”备份后还不够,如果每次宕机都需要人工恢复切换至备份服务,恢复时间得不到保证,同时人为的故障恢复过程中可能会引入新的风险(人为事故),从而降低了服务的可用性,因此必须还具备”自动故障转移”功能。而数据库服务相比于其它系统的高可用,在以上两个关键技术点的实现上会更加的困难,因为传统RDMS对数据和事务的持久性和稳定性是要求非高的,从也提高了对冗余数据的一致性的要求和实现难度。
下图是Oracle官方对Mysql几种典型高可用方案及可用性的总结,由于时间相对较早并且随着近几年分布式一致性协议在工业界的实践和发展,Mysql高可用方案又有了全新的发展方向以及相对成熟的方案,下面将一并罗列和解析。
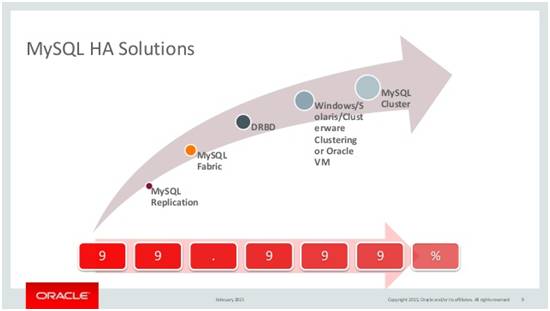
(1)Mysql Replication 就是通过Mysql原生的复制技术来实现数据的冗余,该方案也是最易实现和通用的方案,相关的原理介绍网上介绍很多,这里不再详细赘述,实现原理主要是通过2PC来实现本地BINLOG和本地数据的一致性,并再此基础上通过两个线程(IO线程和SQL线程)来实现远端数据和本地数据的同步,根据数据一致性程度不同复制技术又可以分为异步复制、半同步复制以及同步复制,另外在此冗余技术之上,一般会搭配使用MysqlProxy、keepalived、MHA等第三方软件来实现自动容灾,此技术方案如果不做一定优化,可用性一般不到2个9。
(2)Mysql Fabric 是Oracle官方提供的一种Mysql高可用方案,通过数据分片下的读写分离模式,该方案的可用性达到2个9。
(3)DRBD磁盘复制,分布式块设备复制(Distributed Relicated Block Deivce,DRBD),是一种基于软件、基于网络的块复制存储解决方案,主要用于对服务器之间的磁盘、分区、逻辑卷等进行数据镜像,当用户将数据写入本地磁盘时,还会将数据发送到网络中另一台主机的磁盘上,这样的本地主机(主节点)与远程主机(备节点)的数据就可以保证实时同步,当本地主机出现问题,远程主机上还保留着一份相同的数据,可以继续使用,保证了数据的安全,该方案缺点是IO性能影响严重,可用性不到3个9。
(4)Solaris Clustering,该方案代表这另一种技术方向,即以共享存储为基础,实现数据库服务器和存储设备的解耦,这样数据库服务器之间的冗余与数据无关,而数据的冗余则通过SAN共享储存或者分布式存储系统来实现,当然Solaris Clustering除此之外还提供了操作系统、硬件等各个层面的监控机制,该方案的可用性达到接近4个9,但是实现代价大,价格昂贵。
(5)Mysql Cluster是官方提供的一个开源方案,其将Mysql的集群分为SQL节点和数据节点,数据节点通过一种内存中的存储引擎来实现自动sharding和复制,虽然该方案号称接近5个9的可用性,但是缺点也是很多,如对内存消耗大,使用成本高,牺牲了过多的SQL语言特性,配置复杂等。
(6)基于PAXOS分布式一致性协议的方案,Paxos 协议主要多数派投票的方式,来就分布式系统中某个值达成一致,该算法被业界认为唯一的分布式一致性算法,包括其在内衍生出来的分布式一致性算法(如Raft等)也在很多肯多开源分布式系统得到应用。Paxos与MySQL相结合可以实现在分布式的MySQL数据库最终一致性从而保证高可用,而使用分布式算法用来解决MySQL数据库数据一致性的问题的方法,也越来越被人们所接受,一系列产品如PhxSQL、MariaDB Galera Cluster、Percona XtraDB Cluster等越来越多的被应用到生产环境,而最近Oracle官方所推出的MySQL Group Replication的GA,更使其在Mysql高可用领域成为了一种民用技术;因此使用分布式协议和多副本来解决数据库一致性问题已经成为了主流的方向。但是此类方案还出于初级阶段,不够成熟,同时分布式一致性协议由于网络开销的原因在性能上还有待提高和优化。
为了实现云数据库服务的高可用,UDB基于半同步复制技术采用双主的热备架构,为了实现故障自动转移,并在此基础上实现了Proxy模块,该模块不仅负责数据业务的转发,同时还监控后端DB的健康状况,双主数据一致性检测,并在后端DB宕机情况下,在不影响数据一致性的情况下,完成数据业务切换,整个架构及容灾过程如下图:
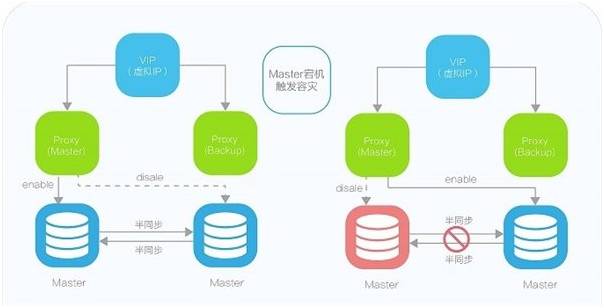
UDB宕机容灾
也许从架构上看很简单,一主一备的架构没有什么新意,但是深入到细节中会发现有很多问题和难点,或者说这些问题都围绕这一个目标,如何保证数据一致性。
普通的异步复制对数据库性能影响小,但是主从数据一致性难以保证;强同步复制虽然保证了主从强一致,但是可用性很差;因此udb选择了折中的方案即半同步复制,但只是简单的使用半同步复制还是不够,通过分析半同步复制的过程和原理,会发现半同步复制会存在以下一些缺陷,下面将分析缺陷的同时介绍下udb的解决方案和策略:
1、临界事务问题?
什么是临界事务,临界事务就是在宕机那个时间点主库正在提交的事务,这个事务可能已经提交,可能已经fsync到磁盘,但是确没有同步到从库中去,半同步复制对于临界事务是没法保证的,如下图是myql5.7无损复制一次事务commit流程(udb基于次复制技术做了优化):
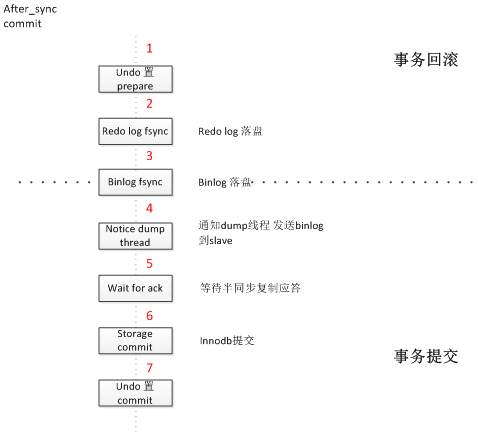
如上图,我们对5.7版本中的无损复制模式(默认模式下)的半同步复制的主机commit做了细分,拆成7个可能crash的阶段,考虑到双机切换后可能会导致的数据丢失和数据一致性异常,我们对每个阶段有如下分析:
在阶段1,2,3发生了crash,由于主库重启后事务会回滚,binlog未发送到从库,所以不会发生异常。
在阶段4发生异常,由于主库进入了commit阶段,但是binlog尚未发送到从库。在主库重启后仍然会将这个事务发送到从机。
在阶段5,6,7发生异常,由于从库已经收到了binlog,只要主库重启后即可达到主库和备库数据一致的效果。
通过以上分析,无损复制模式下只有在阶段4发生宕机会导致恢复后双主数据不一致,因为当在此阶段发生宕机,该事务并没有发送至从库,但是主库已提交至Binlog和Redolog,如果此时业务切至从库,主库恢复后会继续将事务commit并同步到从库,但是由于从库上已经有了新事务,很可能会和此事务产生冲突(如主键冲突),从而导致双主数据不一致;为了解决此宕机时临界事务问题,我们通过内核层面在主库重启recovery阶段作了如下调整:有选择性的commit并复制到从库部分事务,回滚掉没有同步到原从库的事务及Truncate掉binlog中相应的event,整个过程如下图:
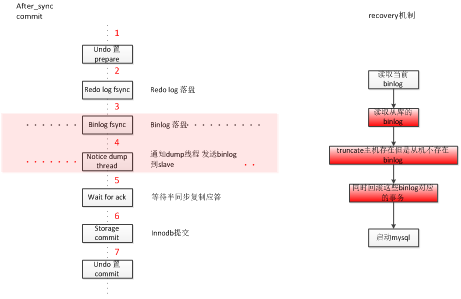
如上图所示,主库在恢复后,会向从库或者proxy询问从本库同步过去的最后一条事务的Binlog位置,并以此为基础回滚掉该Binlog位置之后的临界事务。
2、半同步退化问题?
由于网络抖动以及从库硬件故障等问题会导致半同步退化为异步,如果在此情况下主库发生宕机并发生切换,会导致数据丢失,对于很多数据敏感的业务(如金融)后果是非常严重的;因此当半同步复制退化,整个集群是不可以容灾切换业务的;但是如果主机宕机无法ssh登陆,我们又如何确定主从是否退化,从库数据是否和主库一致呢。
为了解决此问题,防止错误的切换导致数据丢失,UDB通过在proxy和mysql之间以及主从之间增加链接通道,proxy和myql会用专门的线程通过此链接通道同步事务信息,如果主库发生宕机,从库可以在本地缓存和远端proxy获取同步事务信息,并使用该事务信息作为从机是否可以切换的依据,如下图:
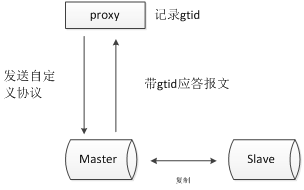
同时为了提高可用性,应对短时间网络抖动后造成双主长时间数据不一致,udb在网络恢复后,会额外启动一个复制链路来追补落后的数据,而原半同步复制链路继续用于复制实时事务,这样不仅可以加快复制数据效率,而且避免了由于从库负载过高永远恢复半同步的风险。
3、如何保证proxy的高可用
通过以上问题及UDB相应解决方案的分析,大家可以看出Proxy在整个架构中扮演着极其重要的角色,不仅负责数据转发,同时为数据一致性和可用性提高保障;因此大家一定会问如果Proxy宕机怎么办,为了解决Proxy高可用问题,UDB这边对Proxy模块也采用了一主一备模式,如下图:
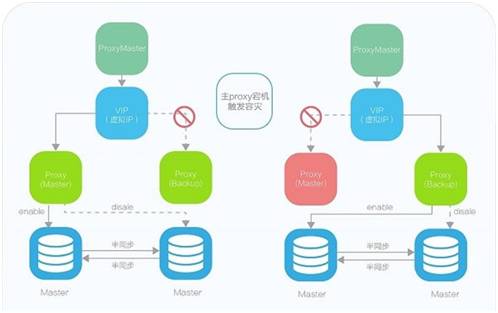
主Proxy宕机触发容灾
当图中左路主Proxy宕机后,ProxyMaster模块会触发容灾处理过程,此时ProxyMaster会将虚拟IP重新绑定至Proxy(backup)并自动启动,启动后Proxy(backup)会重新链路至原MasterDB,以保证业务不间断,而ProxyMaster模块通过ZK服务分布在多个服务器上,有效的保证了Proxy的可用性。
当然除了该双主技术架构外,为了保障服务的高可用,UDB在运维监控等层面也做了很多工作,通过对从硬件、操作系统、数据库以及网络等各个层面的不间断监控,从而最大程度的及时捕获和恢复数据库服务;同时UDB通过自研的大型数据库备份系统,能够应对各种级别的宕机故障后的数据恢复,从而保障了用户数据的安全可靠性,这里不做过多赘述,有兴趣的同学可以参考《从炉石传说数据库故障看云数据备份策略》这篇文章。
本文系UCloud投稿,已经授权InfoQ公众号转发传播。
作者介绍
孙研,UCloud云数据库UDB团队核心成员、高级研发工程师,带领团队对UDB底层架构进行重构,在内核方面对UDB性能和数据一致性等方面做了大量深入的工作。数年来深耕在云数据库领域,热衷于开源、分享。
「细说云计算」是InfoQ旗下关注云计算技术的垂直社群,投稿请发邮件到[email protected],注明“细说云计算投稿”即可。








