这是一篇讲解深度学习数学的系列文章的第一篇,但并非是初等数学,还涉及到了拓扑与测度论等内容。更规范的公式,请查看原文地址
http://elmos.scripts.mit.edu/mathofdeeplearning/2017/03/09/mathematics-of-deep-learning-lecture-1/。
本文转自数学公众号
机器之心(almosthuman2014)

该系列文章的目录(不完整版),本文为 Lecture 1 的内容。
深度前馈网络
我们从统计学出发,先很自然地定义一个函数 f,而数据样本由⟨Xi,f(Xi)⟩给出,其中 Xi 为典型的高维向量,f(Xi) 可取值为 {0,1} 或一个实数。我们的目标是找到一个最接近于描述给定数据的函数 f∗(不过拟合的情况下),因此其才能进行精准的预测。
在深度学习之中,总体上来说就是参数统计的一个子集,即有一族函数 f(X;θ),其中 X 为输入数据,θ为参数(典型的高阶矩阵)。而目标则是寻找一组最优参数θ∗,使得 f(X;θ∗) 最合适于描述给定的数据。
在前馈神经网络中,θ就是神经网络,而该网络由 d 个函数组成:
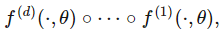
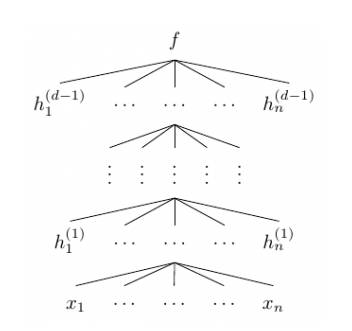
大部分神经网络都是高维的,因此其也可以通过以下结构图表达:
其中
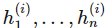 是向量值函数 f^(i) 的分量,也即第 i 层神经网络的分量,每一个
是向量值函数 f^(i) 的分量,也即第 i 层神经网络的分量,每一个
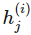 是
是
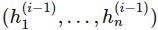 的函数。在上面的结构图中,每一层函数 f^(i) 的分量数也称为层级 i 的宽度,层级间的宽度可能是不一样的。我们称神经网络的层级数 d 为网络的深度。重要的是,第 d 层的神经网络和前面的网络是不一样的,其为输出层,在上面的结构图中,输出层的宽度为 1,即 f=f(d) 为一个标量值。通常统计学家最喜欢的是线性函数,但如果我们规定神经网络中的函数 f^(i) 为一个线性函数,那么总体的组合函数 f 也只能是一个线性函数,也样就完全不能拟合高维复杂数据。因此我们通常激活函数使用的是非线性函数。
的函数。在上面的结构图中,每一层函数 f^(i) 的分量数也称为层级 i 的宽度,层级间的宽度可能是不一样的。我们称神经网络的层级数 d 为网络的深度。重要的是,第 d 层的神经网络和前面的网络是不一样的,其为输出层,在上面的结构图中,输出层的宽度为 1,即 f=f(d) 为一个标量值。通常统计学家最喜欢的是线性函数,但如果我们规定神经网络中的函数 f^(i) 为一个线性函数,那么总体的组合函数 f 也只能是一个线性函数,也样就完全不能拟合高维复杂数据。因此我们通常激活函数使用的是非线性函数。
最常用的激活函数来自神经科学模型的启发,即每一个细胞接收到多种信号,但神经突触基于输入只能选择激活或不激活一个特定的电位。因为输入可以表征为
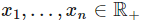 。
。
对于一些非线性函数 g,由样本激励的函数可以定义为:
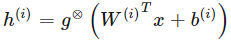
其中 g⊗ 定义了以线性函数为自变量的一个非线性函数。
通常我们希望函数 g 为非线性函数,并且还需要它能很方便地求导。因此我们一般使用 ReLU(线性整流单元)函数 g(z)=max(0,z)。其它类型的激活函数 g 还包括 logistic 函数:
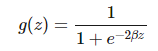 和双曲正切函数:
和双曲正切函数:
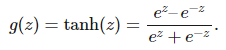 。
。
这两种激活函数相对 ReLU 的优点,即它们都是有界函数。
正如前面所说的,最后的输出层和前面的层级都不一样。首先它通常是标量值,其次它通常会有一些统计学解释:
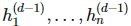 。
。
通常可以看作经典统计学模型的参数,且 d-1 层的输出构成了输出层激活函数的输入。输出层激活函数可以使用线性函数
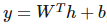 。
。
该线性函数将输出作为高斯分布的条件均值。其它也可以使用 σ(wTh+b),其中σ代表 Sigmoid 函数,即
该 Sigmoid 函数将输出视为 P(y)为 exp(yz) 的伯努利试验,其中
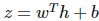 。
。
更广义的 soft-max 函数可以给定为:
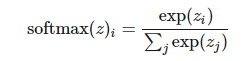
其中
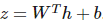 。
。
现在,z 的分量和可能的输出值相对应,softmax(z)i 代表输出值 i 的概率。例如输入图像到神经网络,而输出(softmax(z)1,softmax(z)2,softmax(z)1)则可以解释为不同类别(如猫、狗、狼)的概率。
卷积网络
卷积网络是一种带有线性算符的神经网络,即采用一些隐藏的几何矩阵作为局部卷积算符。例如,第 k 层神经网络可以用 m*m 阶矩阵表达:
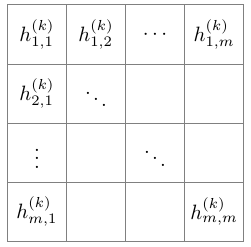
我们定义 k+1 层的函数
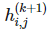 可以由 2*2 矩阵在前一层神经网络执行卷积而得出,然后再应用非线性函数 g:
可以由 2*2 矩阵在前一层神经网络执行卷积而得出,然后再应用非线性函数 g:
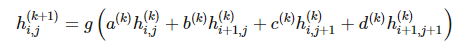 。
。
参数 a(k)、b(k)、c(k) 和 d(k) 只取决于不同层级滤波器的设定,而不取决于特定的元素 i,j。虽然该约束条件在广义定义下并不必要,但在一些如机器视觉之类的应用上还是很合理的。除了有利于参数的共享,这种类型的网络因为函数 h 的定义而自然呈现出一种稀疏的优良特征。
卷积神经网络中的另一个通用的部分是池化操作。在执行完卷积并在矩阵索引函数
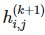 上应用了 g 之后,我们可以用周围函数的均值或最大值替代当前的函数。即设定:
上应用了 g 之后,我们可以用周围函数的均值或最大值替代当前的函数。即设定:
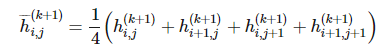
这一技术同时可以应用到降维操作中。
模型和优化
下面我们需要了解如何求得神经网络参数,即到底我们该采取什么样的 θ 和怎么样评估θ。对此,我们通常使用概率建模的方法。即神经网络的参数θ决定了一个概率分布 P(θ),而我们希望求得 θ 而使条件概率 Pθ(y|x) 达到极大值。即等价于极小化函数:
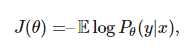
其中可以用期望取代对数似然函数。例如,如果我们将 y 拟合为一个高斯分布,其均值为 f(x;θ),且带有单位协方差矩阵。然后我们就能最小化平均误差:

那么现在我们该怎样最优化损失函数 J 以取得最优秀的性能。首先我们要知道最优化的困难主要有四个方面:
-
过高的数据和特征维度
-
数据集太大
-
损失函数 J 是非凸函数
-
参数的数量太多(过拟合)
面对这些挑战,自然的方案是采用梯度下降。而对于我们的深度神经网络,比较好的方法是采用基于链式求导法则的反向传播方法,该方法动态规划地求偏导数以降误差反向传播以更新权重。
另外还有一个十分重要的技术,即正则化。正则化能解决模型过拟合的问题,即通常我们对每一个特征采取一个罚项而防止模型过拟合。卷积神经网络通过参数共享提供了一个方案以解决过拟合问题。而正则化提供了另一个解决方案,我们不再最优化 J(θ),而是最优化 J(θ)=J(θ)+Ω(θ)。
其中Ω是「复杂度度量」。本质上Ω对「复杂特征」或「巨量参数」引入了罚项。一些Ω正则项可以使用 L2 或 L1,也可以使用为凸函数的 L0。在深度学习中,还有其他一些方法解决过拟合问题。其一是数据增强,即利用现有的数据生成更多的数据。例如给定一张相片,我们可以对这张相片进行剪裁、变形和旋转等操作生成更多的数据。另外就是噪声,即对数据或参数添加一些噪声而生成新的数据。
生成模型:深度玻尔兹曼机
深度学习应用了许多概率模型。我们第一个描述的是一种图模型。图模型是一种用加权的图表示概率分布的模型,每条边用概率度量结点间的相关性或因果性。因为这种深度网络是在每条边加权了概率的图,所以我们很自然地表达为图模型。深度玻尔兹曼机是一种联合分布用指数函数表达的图模型:
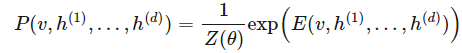
其中配置的能量 E 由以下表达式给出:
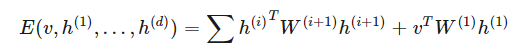
一般来说,中间层级为实数值向量,而顶部和底部层级为离散值或实数值。
波尔兹曼机的图模型是典型的二分图,对应于每一层的顶点只连接直接在其顶部和底部的层级。
这种马尔可夫性质意味着在 h1 条件下,v 分量的分布是和 h2,…,hd 还有 v 的其他分量相互独立的。如果 v 是离散的:
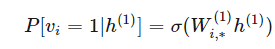
其他条件概率也是相同的道理。





