选自medium
作者:Sahil Singla
机器之心编译
参与:Panda
尽管卷积神经网络成就非凡,但卷积本身并不完美,卡内基梅隆大学计算机科学博士 Sahil Singla 近日在 Medium 上发文,介绍了他对「新一类卷积」的探索研究,相关实验代码也已在文中公开。机器之心对本文进行了编译介绍。另外要注意,阅读这篇文章需要预先有一些关于 CNN 的知识储备。
卷积有很多地方不讨人喜欢。其中最大的一个问题是,大多数权重(尤其是后面层的权重)相当接近于 0。这说明大多数权重都没有学习到任何东西,对网络处理任何新信息都没有任何帮助。
所以我想对卷积运算进行修改,以便解决这个问题。这篇文章给出了我在这个方向上做出的实验以及结果。
实验 1
究其根本,每个 2D 卷积运算其实就是一个矩阵乘法运算。假设卷积的维度是(核大小,核大小,输入通道,输出通道),那么其中矩阵的维度是(核大小×核大小×输入通道,输出通道)。为了简单起见,在本文中,我们将这种矩阵称为维度为(m,n)的卷积矩阵(convolution matrix)。
如果我们可以维持该卷积矩阵的列是正交的(以可微分的方式),那么我们可以确保输出特征图(output feature map)中的每个通道都能得到不存在于任何其它特征图中的信息。更重要的是,这能帮助我们创造权重更具可解释性的神经网络。
是的,有一些不同的方法能确保这能用上一些线性代数技巧(一种是豪斯霍尔德变换(Householder transformation),另一种是(吉文斯旋转(Givens rotation))。我使用了豪斯霍尔德变换,因为这在 GPU 上的速度要快很多。
、
其中的思想如下:
我们不再保持卷积过滤器中的 m×n 个变量和偏置中的 n 个变量是可训练的,而是以另一种方式从另一个可训练的变量集中生成过滤器和偏置。
更具体一点,对于一个维度为 (m, n) 的卷积矩阵,为 m 个维度的每一个创造 n 个向量。第一个向量(比如说 v1)将会有 m-n+1 个可训练的变量(在开始时用 n-1 个 0 填充),第二个向量(比如说 v2)有 m-n+2 个 可训练的变量(用 n-2 个 0 填充),第三个(v3)则有 m-n+3 个可训练的变量(用 n-3 个 0 填充),依此类推。接下来对所有这些向量进行归一化。使用这些向量创建 n 个豪斯霍尔德矩阵(Householder matrix),按 v1*v2*v3…*vn 的顺序将向量相乘。结果得到的矩阵有 m×m 的维度而且是正交的。取该矩阵的前 n 列,那么结果得到的矩阵的大小就是 (m, n)。然后将其用作卷积矩阵。
看起来这种运算似乎很耗时间,但实际上对于一个 3x3x64x128 的卷积,意味着 576x576 大小的矩阵进行 128 次矩阵乘法运算。当这种卷积在 256×256 大小的图像上执行时,这点运算其实算不了什么(意味着会有 (256x256)x(3x3x64x128) 次翻转)。
如果你必须沿该过滤器创建一个偏置,仍然可以执行上面的流程,只是其中用 m+1 代替 m,得到的矩阵的大小为 (m+1, n),取出最上面一行,并将其用作偏置,使用剩下的 (m, n) 矩阵作为过滤器。
如果你使用了批规范化(batch normalization),那么这个构想将没有效果,因为列正交的假设在这种情况下并不成立。
对于实验,我使用了 CIFAR-10 和类似 VGG 的架构。代码在同一个代码库中:https://github.com/singlasahil14/orthogonal-convolution/blob/master/cifar_deep.py
结果非常极其让人失望。
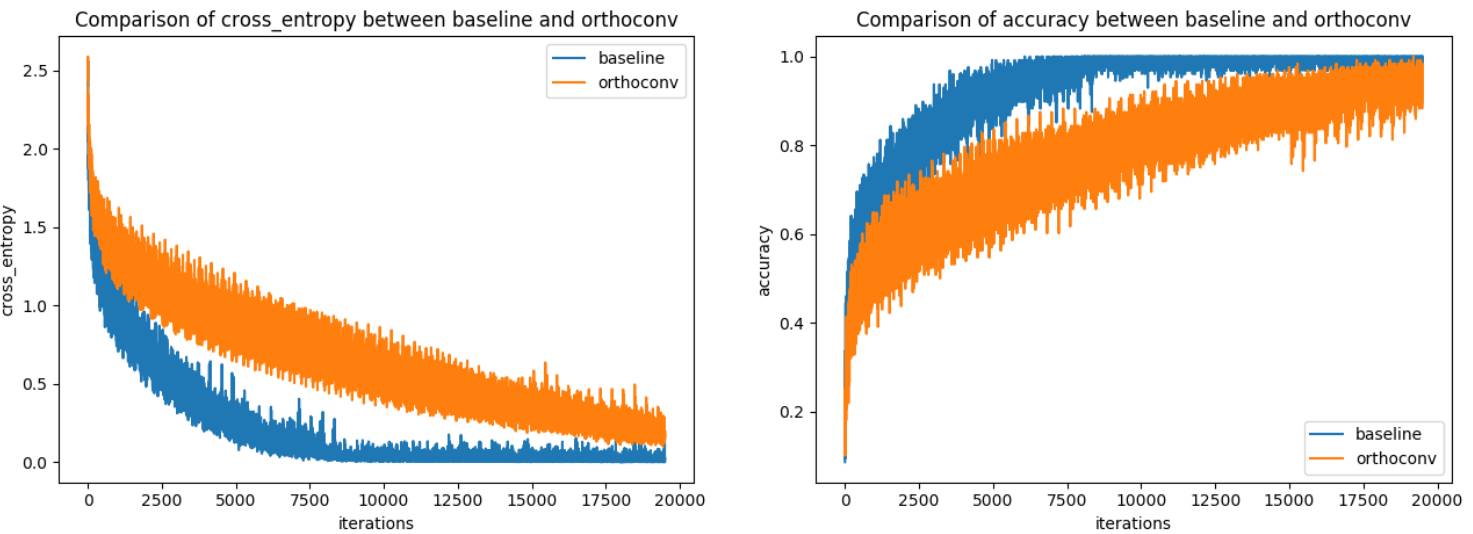
在训练数据上的交叉熵和准确度图表
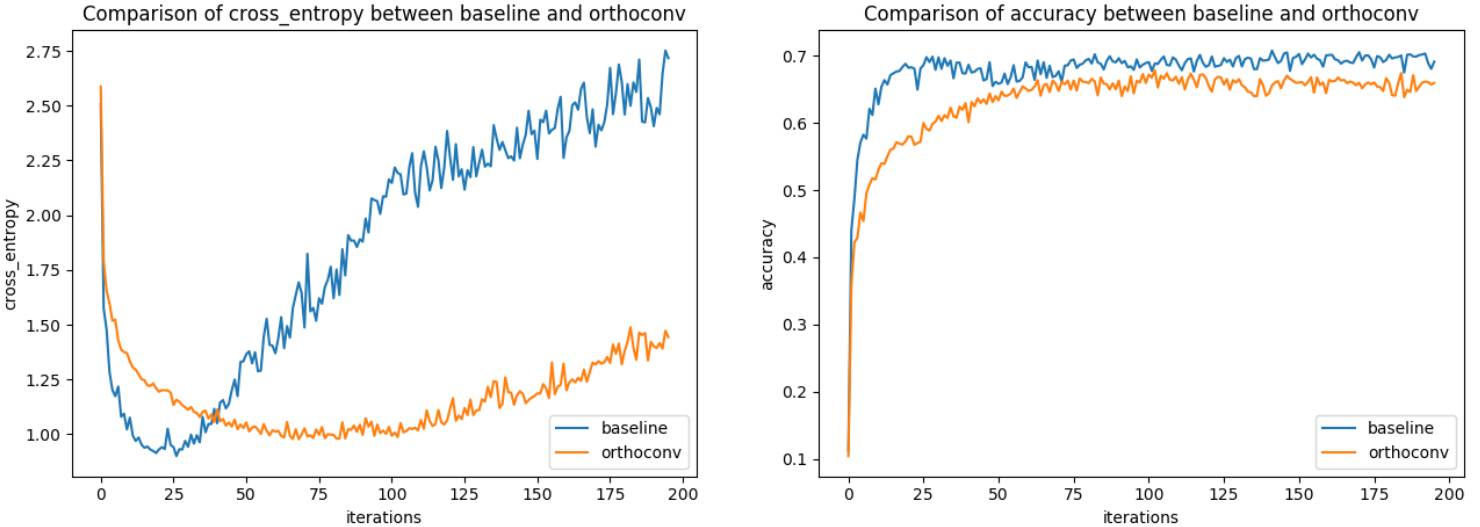
在验证数据上的交叉熵和准确度图表
可以看到,因为在基准和正交卷积之间的所有扭曲,所以结果很糟糕。更重要的是,正交卷积所用的训练时间显著更多。下图是每次迭代所用时间(time_per_iter)的图表:
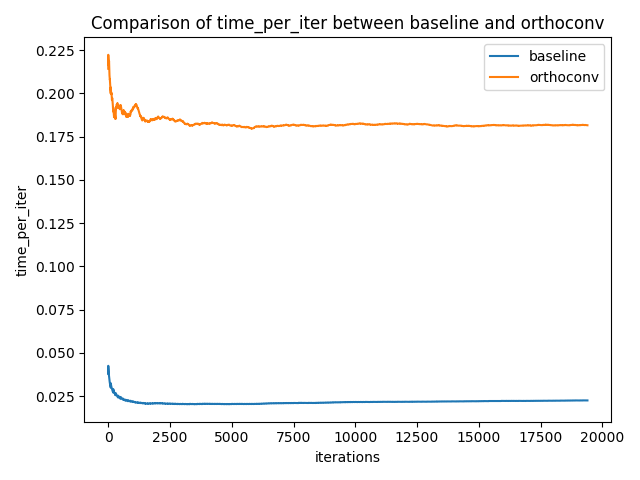
基准和正交卷积每次迭代所用时间的比较
从图中可以看到,正交卷积所用时间几乎超过 7 倍。加速这些代码的方法是存在的,但因为结果如此糟糕,我也就没有更进一步了。
我的直观感觉是,它没效果的原因是模型的优化格局遭到了严重的限制,而这又是由所有列向量必须正交的限制导致的。为了测试我的直觉,我做了下面的实验。
实验 2
对于接下来的实验,我不再使用豪斯霍尔德乘法生成的卷积权重和偏置,而是增加了另一个损失项,称为正交性损失(orthogonality loss)。正交性损失是按以下方式计算的:
使卷积矩阵的大小为 (m, n),偏置向量的大小为 (n),将这两个向量级联到一起,得到一个大小为 (m+1, n) 的矩阵。称这个矩阵为 M。计算这个矩阵的列式范数(column-wise norm),称之为 N(这是一个大小为 (1, n) 的矩阵)。
计算转置 (M)*M。计算转置 (N)*N。然后将两个矩阵相除。在得到的矩阵中,a(i,j) 包含了在矩阵 M 中索引 i 和 j 处的列向量之间的角的余弦。通过对该矩阵中的所有元素求平方而创造一个新矩阵。找到该矩阵中所有元素的和(除了该矩阵的迹)。为所有的卷积层进行这样的求和,我们将得到的结果值就称为正交性损失(或简称 ortho loss)。我将其与一个称为正交性权重(orthogonality weight)的超参数相乘,然后将其加入到了总体损失之中。
我使用不同的正交性权重值进行了实验:对应之前的实验中描述的卷积,我尝试了 0.1、1、10、100 和 inf。
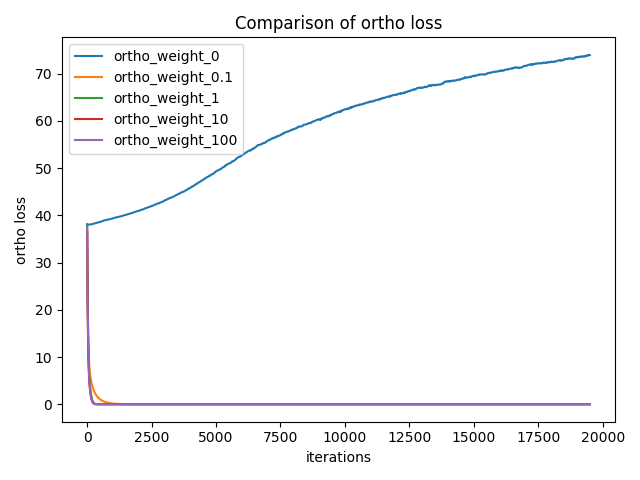
所有不同实验的正交性损失
起始的正交性损失(没有乘权重)大约为 40。这比交叉熵本身还大得多。然而网络学会了在几次迭代之内就使其接近于 0。
从上图中可以看到,该网络非常快地就学会了保持该卷积矩阵中的所有列向量正交。当正交性权重被设置为 0 时,正交性损失会不断增大;而在其它情况下(0.1、1、10、100),它会达到接近 0 的值。这意味着如果我们添加加权的正交损失,由该卷积矩阵学习到的权重确实是正交的。
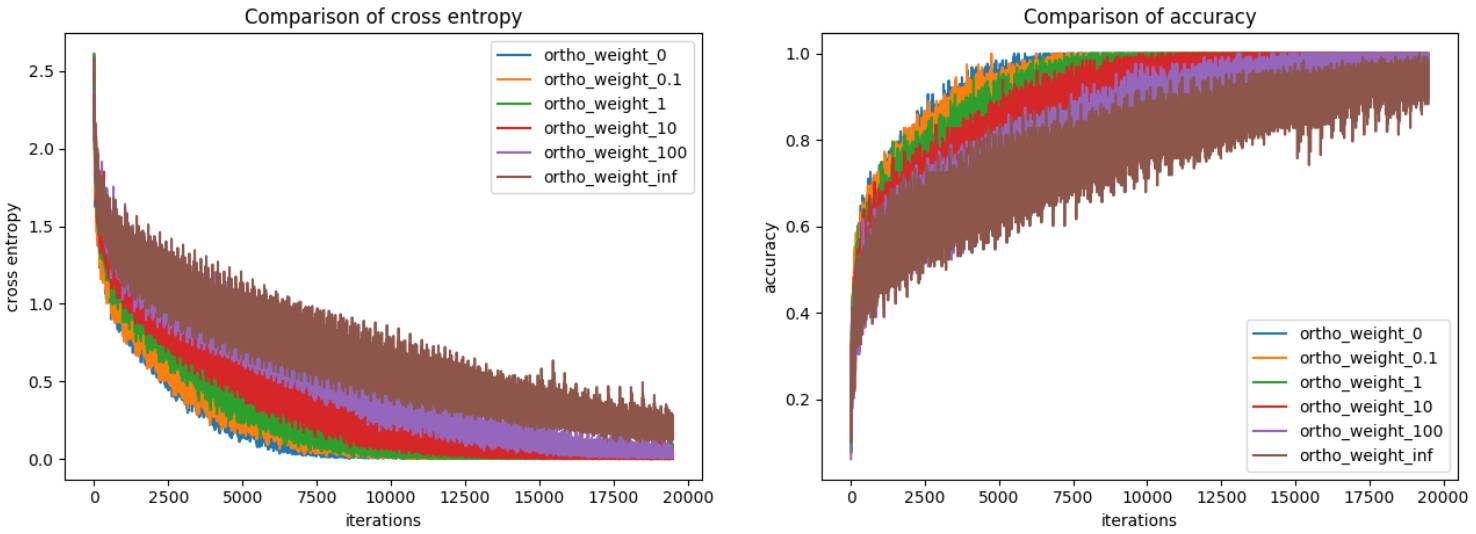
在训练数据上的交叉熵和准确度
如上图所示,随着正交性权重越来越大,网络训练的难度也越来越大。
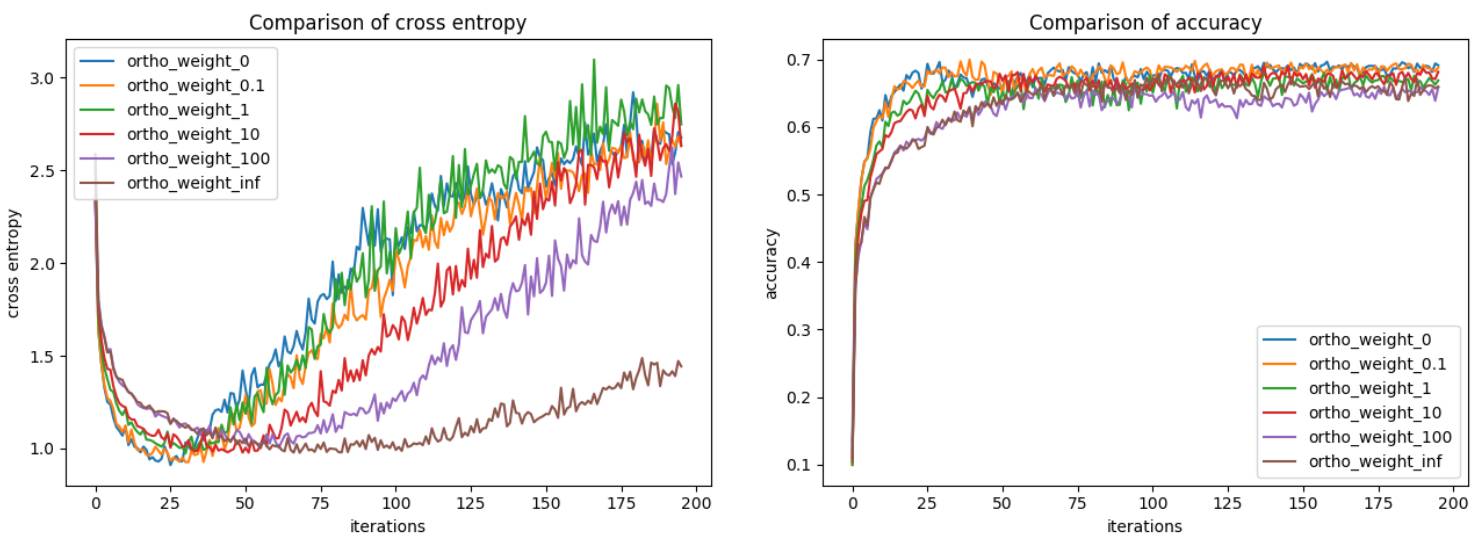
在验证数据上的交叉熵和准确度
但该网络得到的验证准确度/交叉熵却很接近正交性损失为 0 的情况。又再一次失望了,我还希望结果会更好呢。但至少比前面的结果好。
接下来,为了更进一步观察,我决定仅给出正交性权重为 0 和 0.1 的情况。
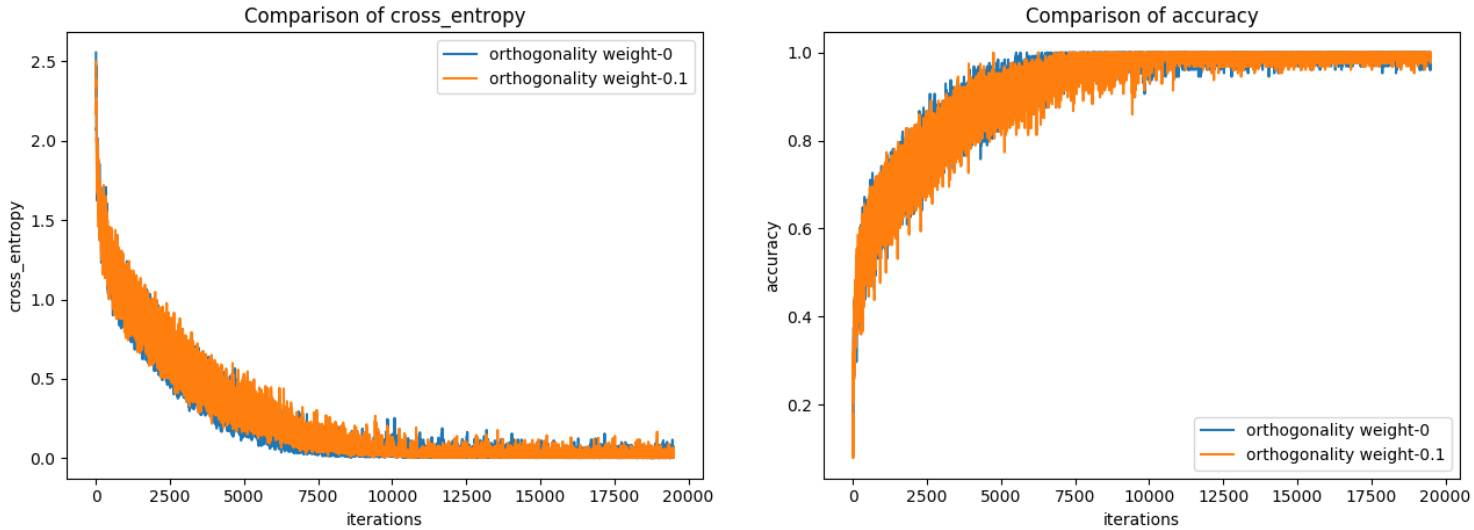
在训练数据上的交叉熵和准确度
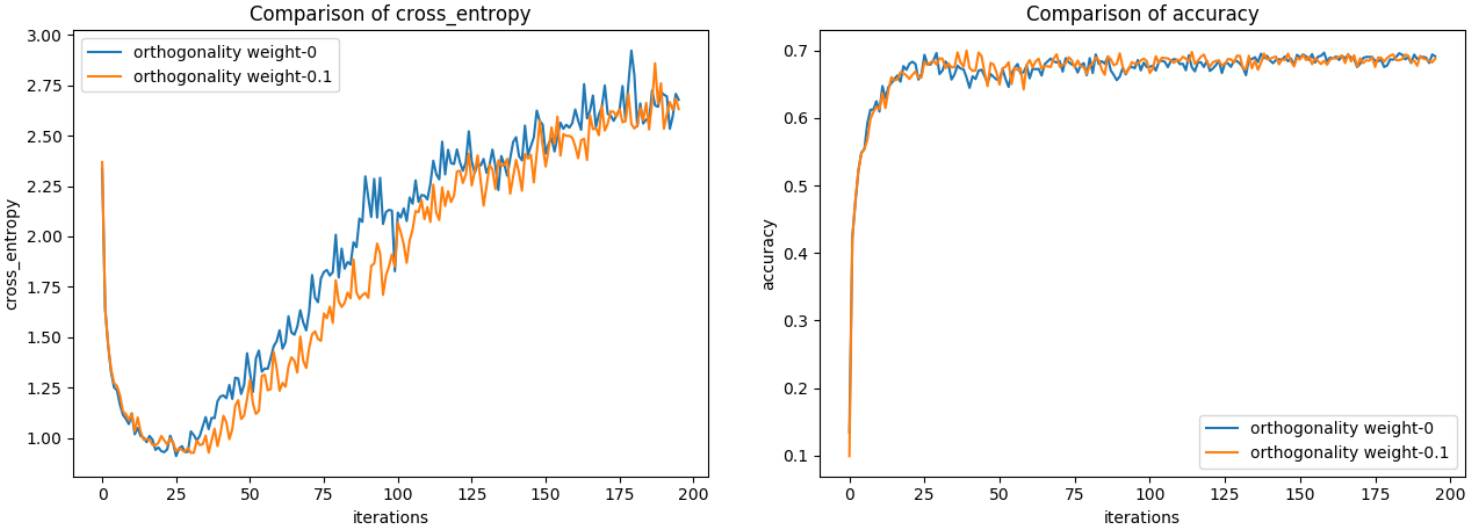
在验证数据上的交叉熵和准确度
可以看到,这两个网络都收敛到了同样的验证交叉熵和准确度。而且正交性权重为 0 时,网络的训练交叉熵要高一点。这差不多说明增加正交性权重可以让网络有更好的泛化能力(更高的训练损失,但同样的验证损失)。
接下来,为了测试这种泛化能力是否适用于其它数据集,我决定使用 CIFAR-100 进行同样的实验。
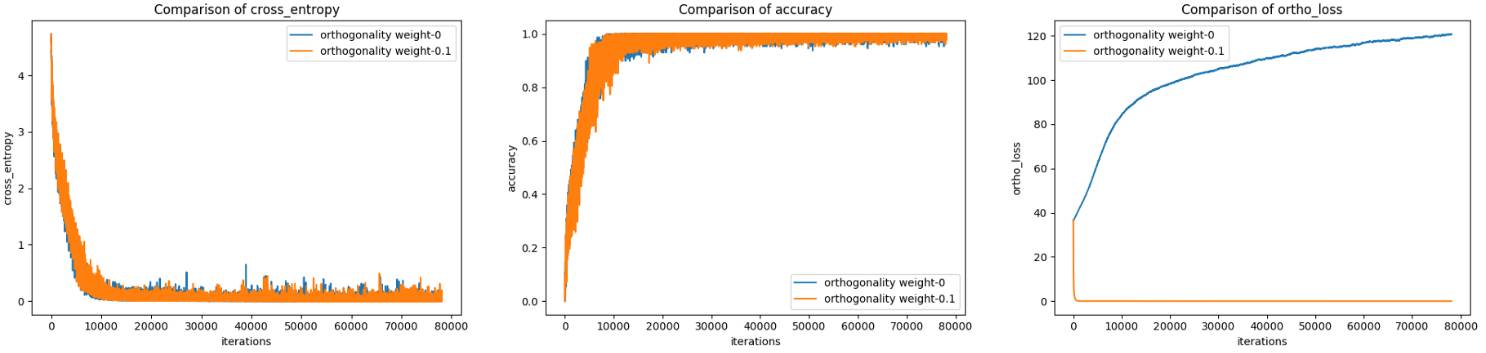
在训练数据上的交叉熵、准确度和正交性损失
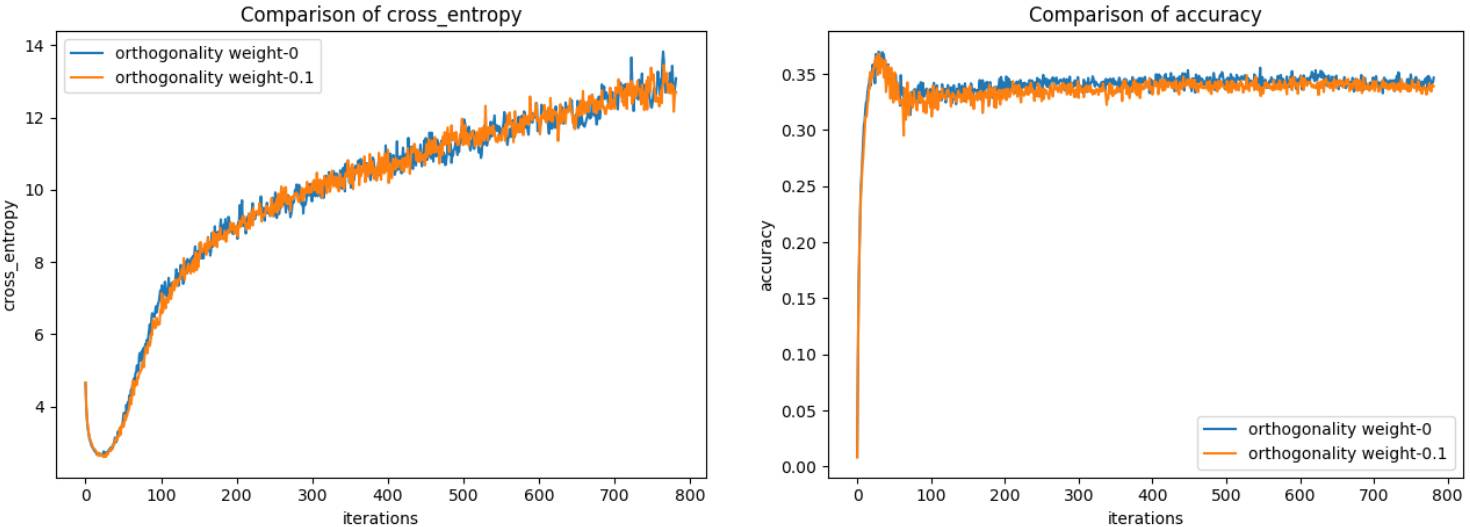
在验证数据上的交叉熵和准确度
这些结果确实也对 CIFAR-100 有效。更重要的是,我们可以看到使用 0.1 正交性权重的网络与使用 0 正交性权重的网络的验证准确度是一样的。而在正交性损失比较图中可以看到,使用 0.1 正交性权重的网络学习的是该卷积矩阵中的正交列。
实验 3
接下来,受这些结果的启发,我决定为循环神经网络也尝试一下同样的思想。使用这里的代码:https://github.com/singlasahil14/char-rnn,并且在未特别指出时都使用默认架构,我决定实验一下给 LSTM 加入正交归一性损失(orthonormality loss)会怎样。注意:正交归一性损失=sum_square(I-transpose(M)*M),其中 M 是 hidden to hidden 状态矩阵。而且它和正交性损失(orthogonality loss)不同——这种情况下我们并不关心所有列的范数是否都为 1。
下面是实验结果(我为正交归一性损失尝试了不同的权重:0.001、0.0001、0.00001、0.000001、0.0000001、0):
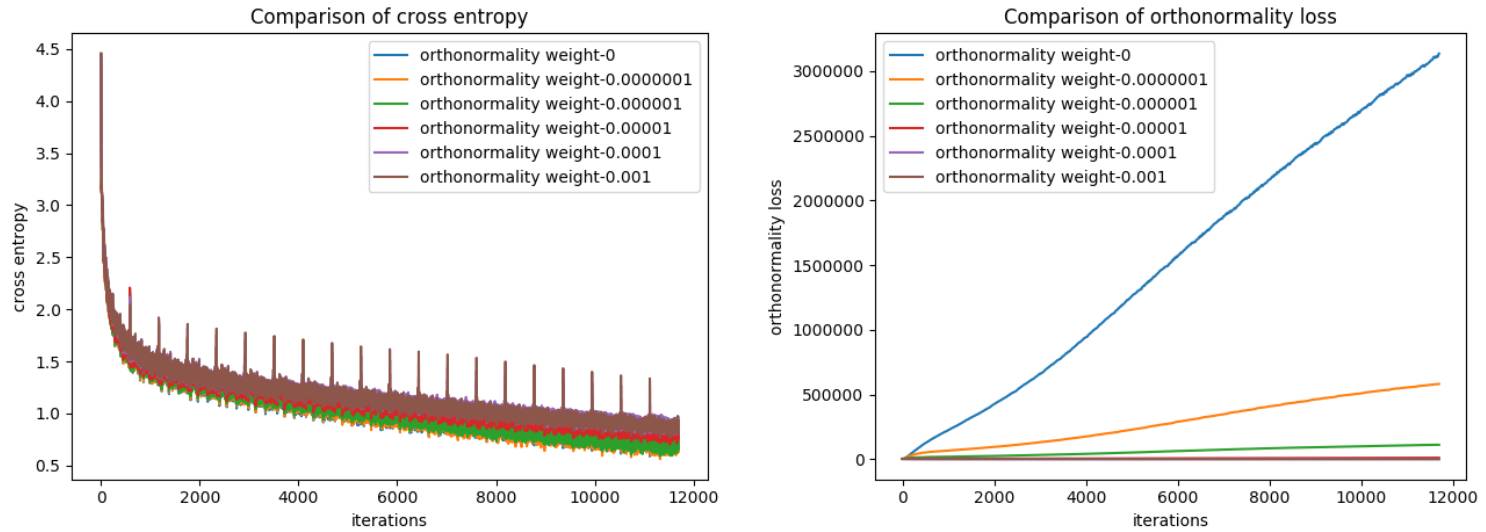
网络训练了 20 epoch 后的交叉熵和正交归一性损失
同样,在我们降低正交归一性权重时,交叉熵下降得更快。接下来,为了比较两个最佳模型的正交归一性权重,我决定拿出其中权重为 0 和 0.0000001 时的交叉熵和正交归一性损失值。
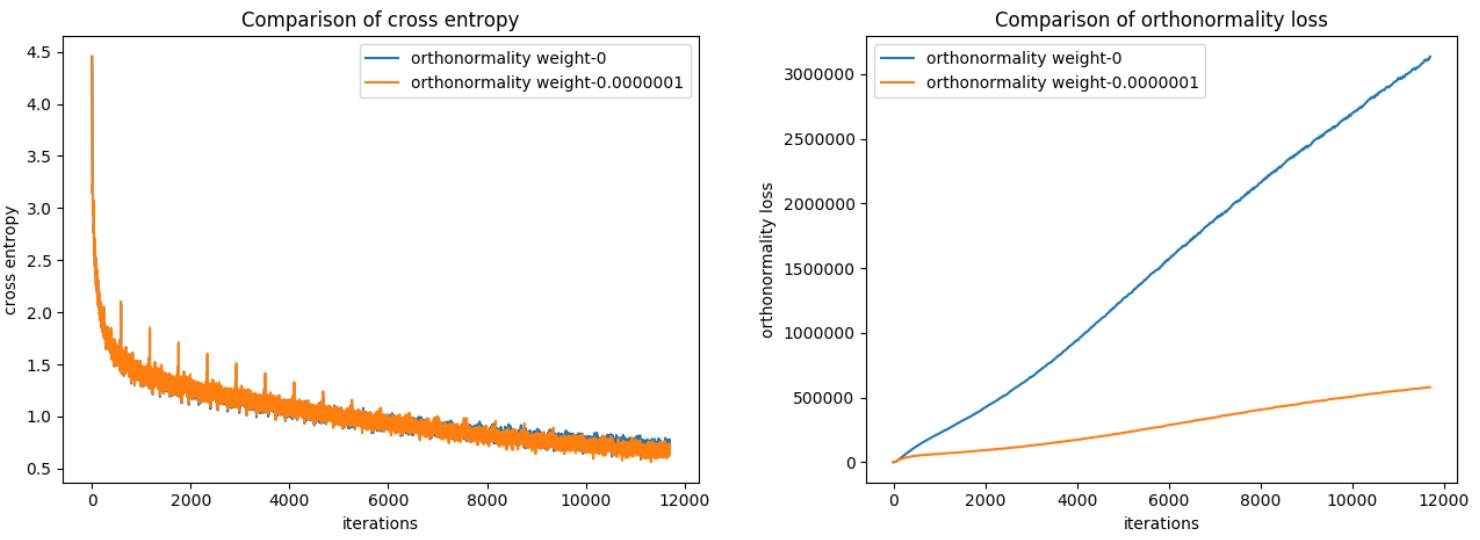
在两种权重(0 和 0.0000001)设置下,网络训练了 20 epoch 后的交叉熵和正交归一性损失
同样差别不大,但它和基准结果差不多。
结论
从这个小项目中,我学习到的最重要的一件事是神经网络是极其复杂的。即使看起来似乎很好的方法也可能会失败,因为当大多数人有一个想法时,他们只是想到了网络最终训练好的状态(就像我一样,我想要矩阵的列是正交的)。但如果你想到网络必须通过一个路径才能优化,那么大多数好想法就立马显得蠢笨了(就像我的这个例子,很显然,在实验 1 中,我严格限制了模型可以选择的路径)。
另外,我也尝试进行了一些非标准的(我自己发明的)调整,想让该网络的表现超过基准。但没有一种调整有效。实际上,能成功重现基准结果就已经让我很开心了,尽管我增加了一个比交叉熵本身更大的损失项。
我也为图像分割进行了同样的实验。结果也相似。这里就不过多提及了。
我也相信这项研究有助于更好地可视化卷积层中的权重。这是我接下来会探索的方向。
本博客中提及的所有实验都可以使用下面的代码库重现:
原文链接:https://medium.com/towards-data-science/experiments-with-a-new-kind-of-convolution-dfe603262e4c
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]








