
本周六(7.15)举办了一次非常火爆的沙龙,对于这次沙龙的演讲主题,三位资深老炮:极客帮创始合伙人 & CSDN创始人蒋涛,CSDN副总裁孟岩,鲁朗软件(北京)有限公司联合创始人智亮跟现场众多程序员们聊了聊开发者转型的事儿:机会在哪,转型中会遇到的哪些问题,技术实操等。
为了方便大家学习,我们精心整理了本次沙龙的嘉宾演讲。另外,你也可以在微信公众号会话中回复“沙龙”,下载本次分享嘉宾(蒋涛、孟岩和智亮老师)的演讲PPT。
演讲 | 蒋涛,孟岩,智亮
整理 | 苏靖芝,鸽子

这几年我也在做投资,从一个比较宏观的角度给大家讲一下,就是说为什么人工智能这么重要。
上上周,百度开了一个开发者大会,叫Create大会,是由史以来中国最像开发者大会的开发者大会。

为什么像开发者大会?
因为有很多大会打着开发者大会的名义,其实都是在推销自己的东西,并没有真正提供给开发者实际的资源。
第二个也没有建立所谓的开发者生态,因为我们开发者生态都是建立在国外的公司的基础上。
百度这场会含义还是非常深的,也是陆奇去作为百度的二号人物,第一次大的亮相,他讲了一句话:未来属于创作者,AI的未来属于开发者,开发者成功才是百度真正的成功,这句话有一定的逻辑关系,我后面给大家解读一下,为什么开发者变得这么的重要,然后AI为什么成为百度的一个重要的基石。
PC时代回顾
首先让我们来回顾一下历史。
历史上,最大的开发者大会是微软1992年开的,为什么?
因为这是PC时代,PC时代最核心的是入口就是操作系统,或者是Windows的桌面,它是建立在X86因特尔的芯片技术上。围绕着这个,我们才有了PC时代,也诞生了开发者的时代。
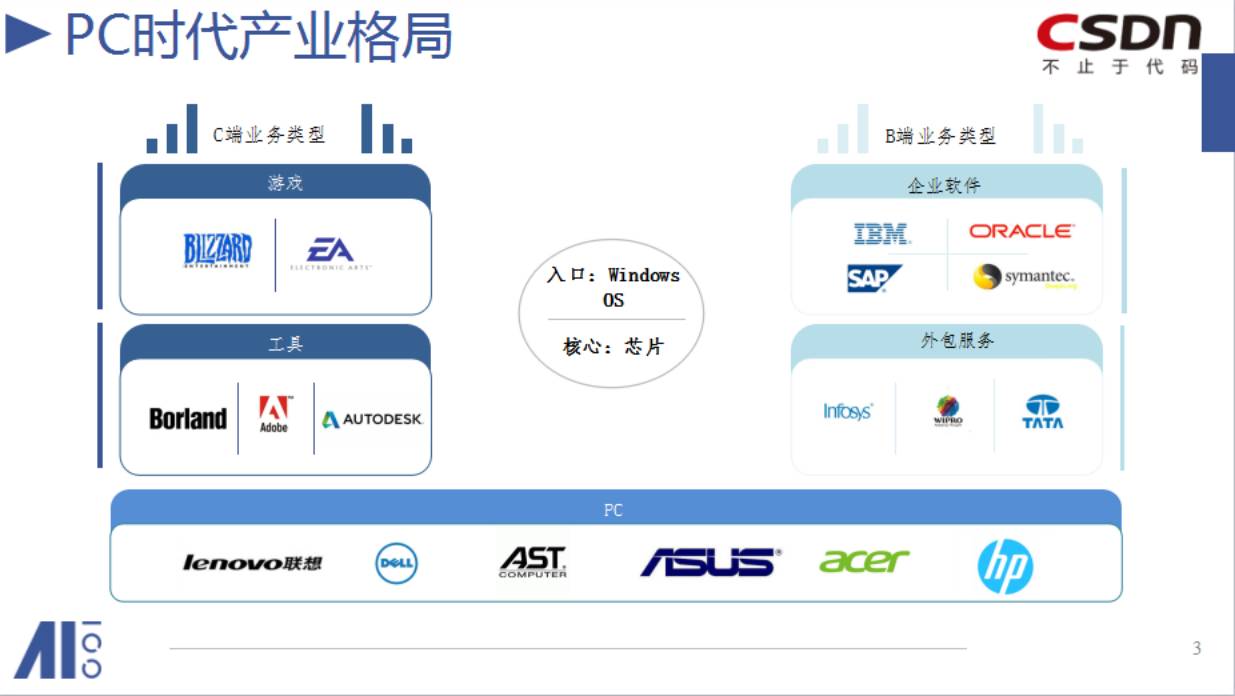
他们为开发者做了什么东西?
在PC时代,我们看最大的一个公司,出现了几类:
一个是行业,公司百亿级别,如IBM,Oracle,SAP,他们为企业提供信息化的软件和工具,包括数据库、ERP,还有做外包,因为各个行业都需要信息化。
另外一个就是C端的业务,服务个人。在个人市场只产生了两类大的公司:
一类是做游戏的,暴雪公司,EA,这是PC游戏行业,也是非常大的一个产业。
还有一类是工具厂商,如图像工具Adobe。
移动互联网时代
接着我们迎来了移动互联网时代,大家都开始找入口,一开始是门户,后来发现不是门户。
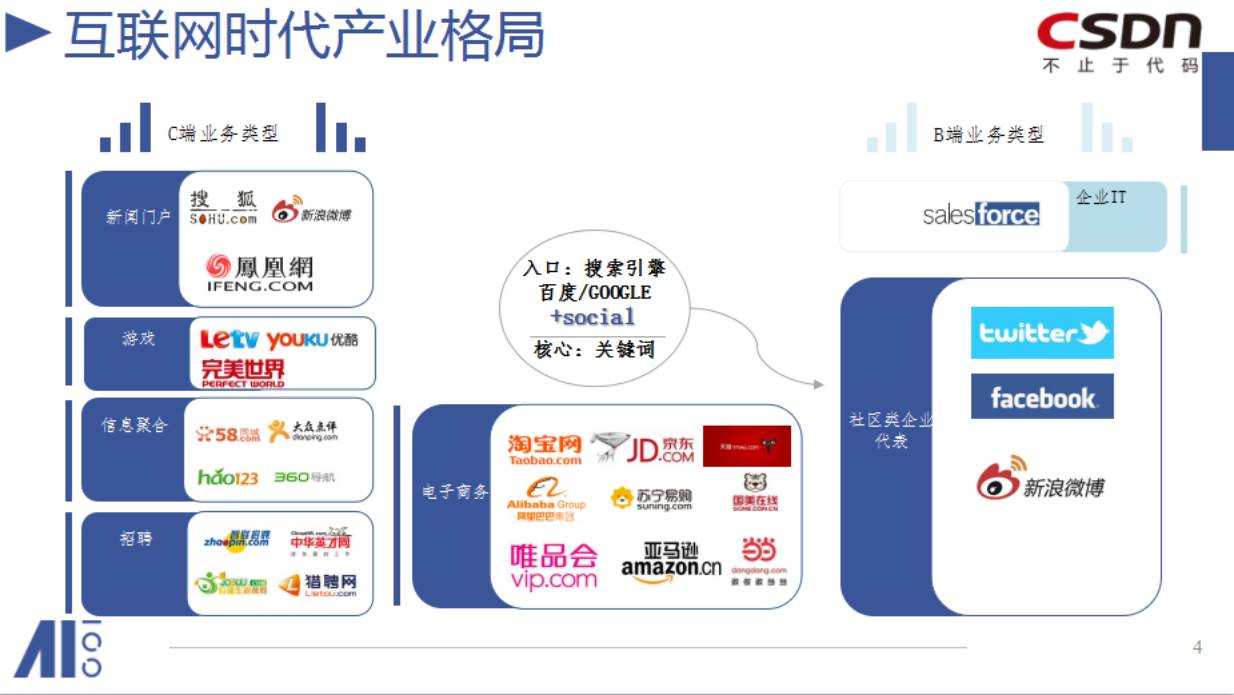
比如,一开始最厉害的是新浪,三大门户,还有网易。
后来随着时间的发展,发现最重要的入口是搜索引擎。谷歌和百度等掌握了绝大部分流量的分发权。
电商也是很大一块入口。比如淘宝,58同城,大家一般都直接去到淘宝,而不是用百度搜索,因此不会被百度卡了脖子。
这是整个PC互联网的发展,这时候我们开发者在做什么呢?
他们在建立各种各样的网站,但是你的网站呢,很重要一点是要服务这些C端的用户。
第二个,可能要做好跟搜索引擎之间的关联。
这是PC互联网,到了移动互联网,才是一个开发者大显身手的时候。
到了移动互联网时候,入口变成了APPSTORE,就是说你做一个应用,原来是关健词搜索,现在是你的应用名字比较重要,你的应用名字能不能在用户之间建立它的认知。
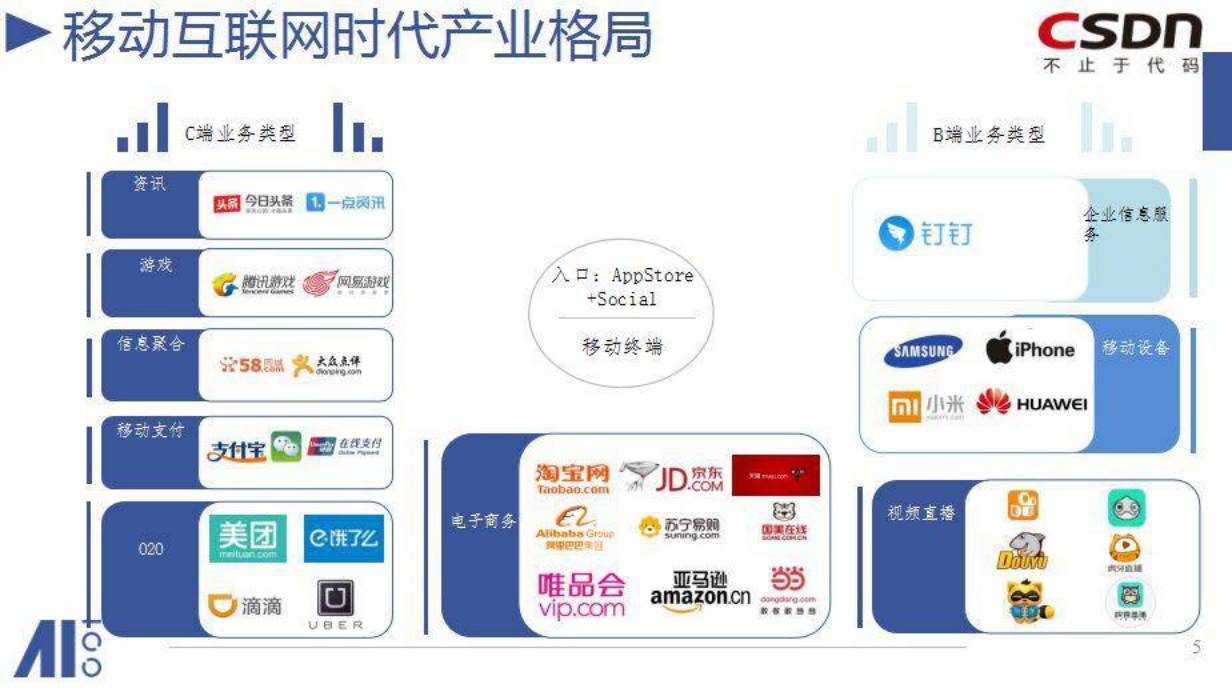
微信作为一个巨大的入口,对开发者没起什么作用,倒是对内容起到一个巨大的作用,不少内容生产者立足微信做创业。
因为PC互联网跟人的连接还是比较远一点,而手机是随身携带的,因此移动支付发展起来。
跟生活比较贴近的,如做天气的APP,也发展得很好,因为它跟生活连在一起,就可以接入更多的服务。
现在APP已极大丰富,APPSTORE上有150万个APP,你现在需要分走用户的注意力比较难了,基本上能做的都被大家做了一遍。
第二个用户没有增长了,获得新用户的成本越来越高。
这是整个APP移动互联网时代。
AI时代
今天什么百度要提出这么一个战略?
因为百度发现,它在移动互联网的时候抓瞎了,因为它不是入口,入口变成APPSTORE、变成微信,变成小米手机,手机成为一个入口,还有应用宝商店,腾讯开了个应用宝,百度买了个91也不是很成功,所以在移动互联网上,百度就Miss掉。
Miss掉以后,O2O战略也不是很成功,这次他们下了很大的决心要做AI的OS,做AI的生态。
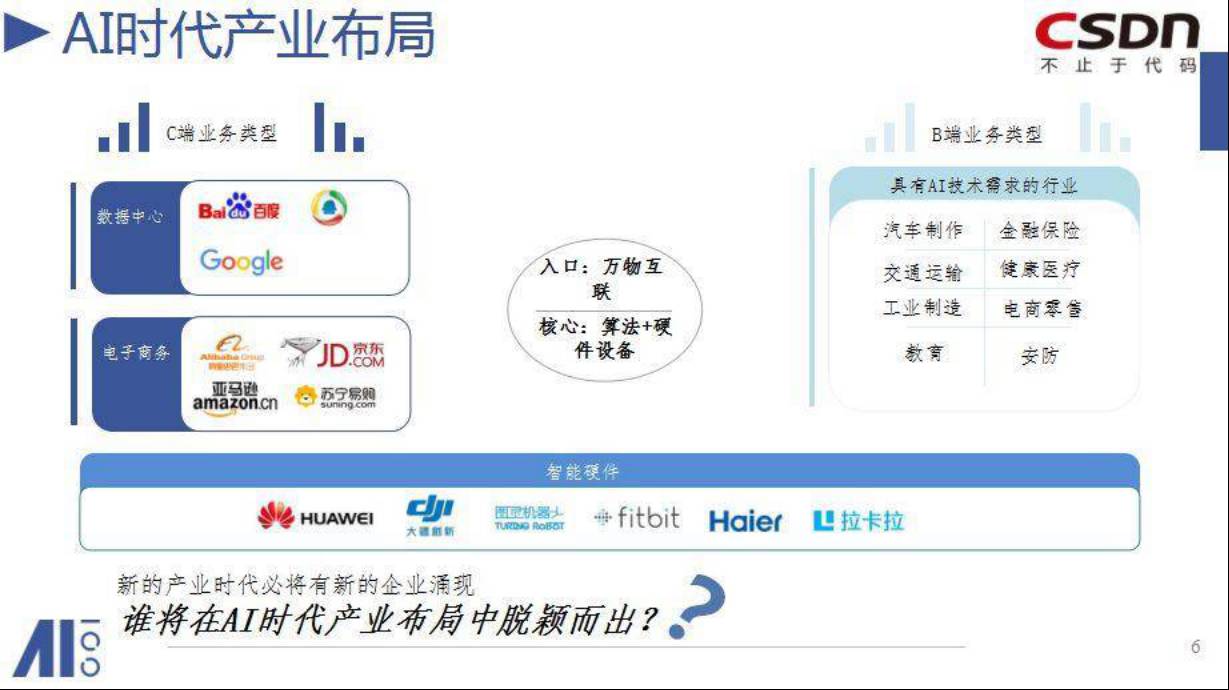
那AI的OS是什么呢?
以后所有的东西都要和互联网连接。摄像机可以连网,摄像机带人脸识别。摄像机识别以后,怎么跟你互动呢?
百度提了一个口号叫唤醒万物,你说Hello索尼摄像机,它就知道是在叫它。这个大概三年内就会发生,这就是说,语音会作为一个入口。
有了入口以后,后面是什么?
你把它唤醒了,它得和你进行交互,它得有算法在背后,而这个算法是要靠大量的硬件驱动。
百度认为,未来的每个行业,每个硬件都可能变智能,而智能化一定要有一个核心的OS来驱动它,所以这就是一个是入口。
但是现在这个生态刚刚开始,机会在哪里呢?
第一个你要做C端的应用,还是很有挑战的,因为现在做人工智能的应用,要有数据,没有数据你的算法就没有办法做出精确度。
那么数据在哪?
数据都在BAT手上,他们有大量的数据,有一大堆C端的公司,他们每天都产生大量的数据,饿了吗,滴滴,摩拜等。有了信息,他就能判断你的意图。比如,现在亚马逊在美国就能根据你过去的购买记录,预测你会喜欢什么样的书,于是它会提前把书送到你家。你回家就能看到5本新书,想看就留下,不想看就退。
所以在C端,实际上我们的机会就不是很大了,因为这些公司手上的数据太大了。其实在B端,AI时代产业B端布局会比移动互联网更大。
AI时代,B端机会更大
为什么这么说B端机会更大呢?
我来详细解释一下。
移动互联网大量解决的是C端的问题,而B端有很多问题没有解决,B端也面临巨大的变革,他们做了第一步的信息化,但是他们没有把业务进行重构,但是人工智能来了以后,会有一个非常大重构的机会。
这其中最大的重构就是无人驾驶汽车,这是一个上万亿美金的市场,围绕着它配套的产业,光售后就有八千亿,如果汽车都变成无人驾驶了,现有的很多服务都会瓦解。
所以我们看到有很多大的公司在这里面下重注。
这是从投资角度看到的一个非常大的机会。
深度学习可以做什么
那从整个产业的角度,人工智能为什么现在变得这么热?
当然第一个原因是阿法狗在去年打败了李世石。
实际上,真正历史性的转折点在2012年。
在2012年Imagenet比赛中,深度学习的使用,将识别错误率大大降低,引起了人们的关注。也就是说,原来人工智能技术被一道墙堵住了,过不去,进步很小,但是采用深度学习后,这个墙相当于被凿开了一个窟窿。下图中紫色代表采用深度学习,蓝色代表传统方式,可以看出其中的跨越式的变化。
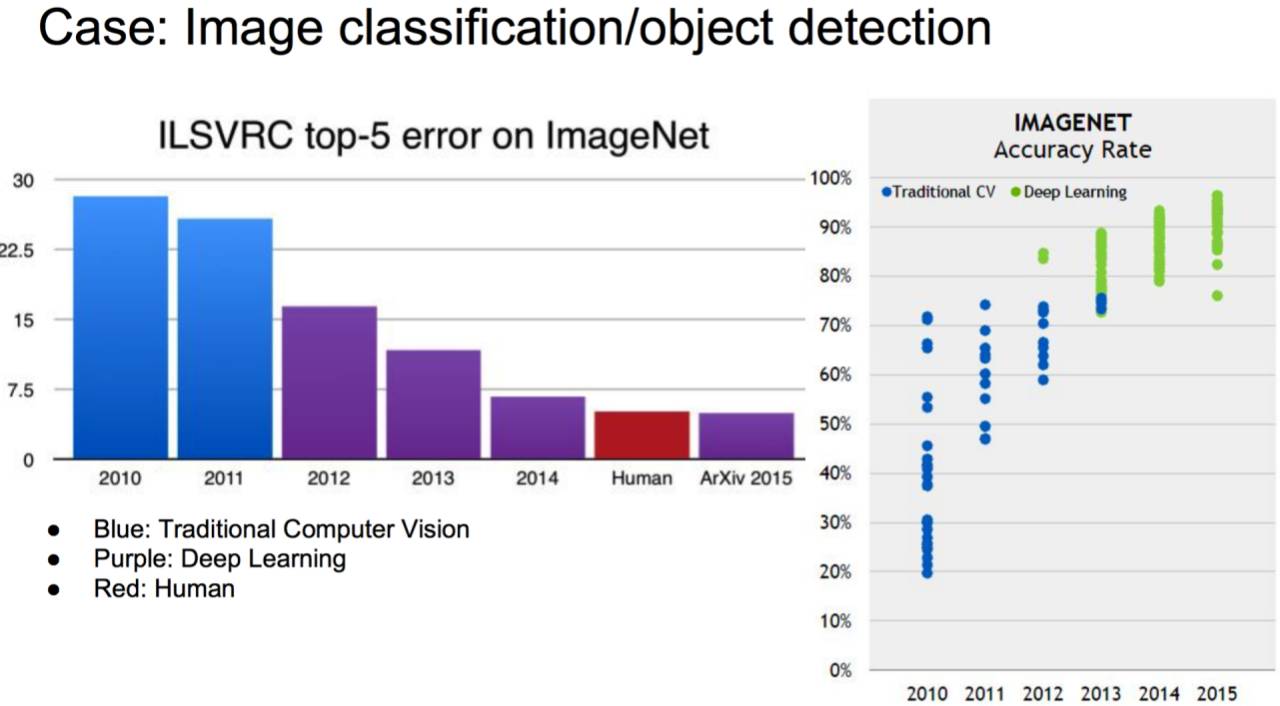
如下图,计算机采用深度学习可以做到精确的识别,把这张图描述出来。

我们常说代码时代结束了,其实它指的不是所有代码,而是原来我们是用各种各样的规则和技术,现在可以用深度学习,用神经网络来建立模型,用以取代原来人工设立的规则。

这是很大的一个不同,而且这个技术不是说只是用在识别领域,它可以用在非常多,以及看起来很小的领域。
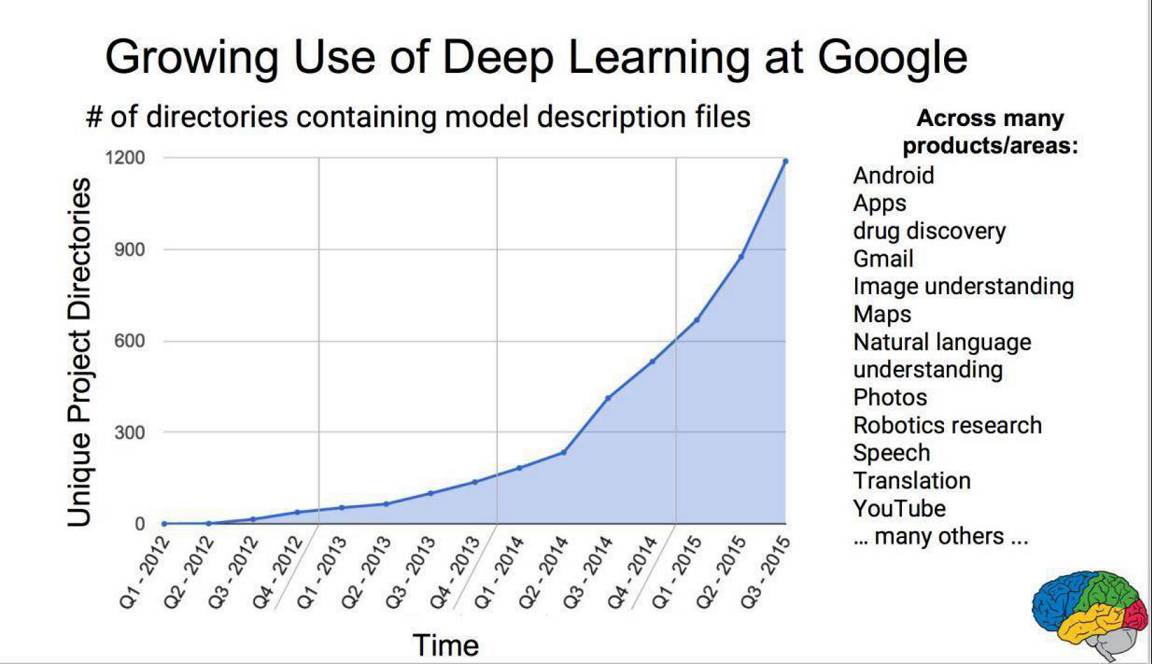
这是Google发布的数据源,展示出自己内部哪些项目用到了深度学习。
从2012年开始,他们就开始用,一开始几个项目,到2015年Q3已经有1200个项目使用深度学习。到2016年,已经有2700个。目前Google内部的所有项目,80%以上都用到了深度学习来改进。
比较小的地方,大家意想不到的地方,比如做缩略图的时候作,同比例放缩就看不清楚人了,所以用深度学习技术来改进。
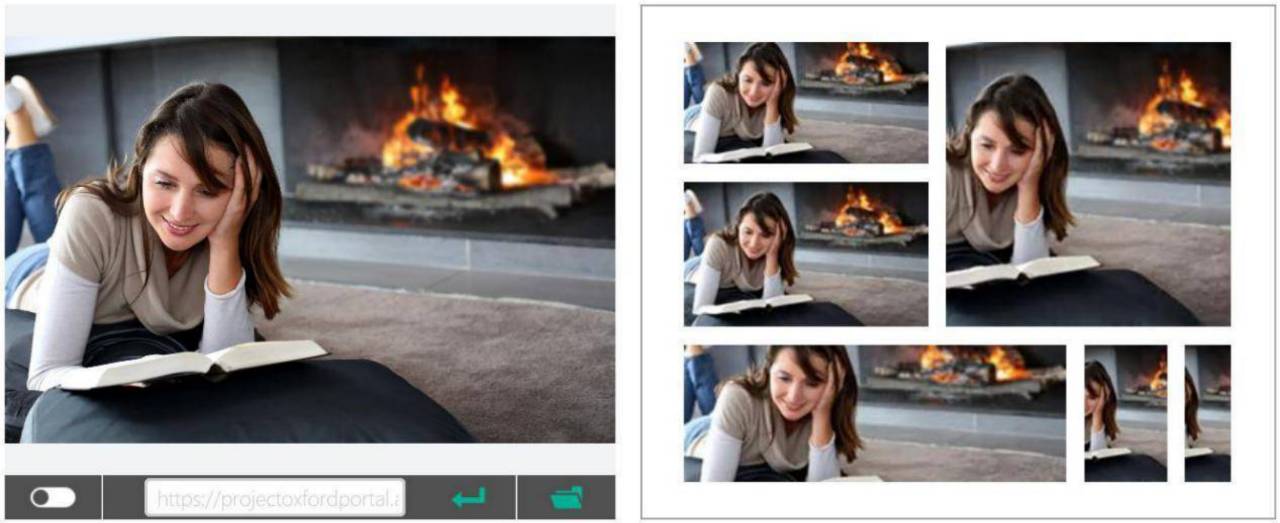
如上图,图片里有人头,当你同比例缩小的时候,就有点看不清了,不方便浏览。于是,我就可以用深度学习来识别头像,以此在缩放的时候,做一个调整,让人像看起来吐出一些方便查找。
还有做压缩,利用这个技术,还可以再压缩30%,因为机器会学习,知道哪里更重要,压缩的时候主要内容保持质量,其他次要内容进一步压缩。

现在我们已经进入到新应用时代。

图片上这个人是深度学习的网红,原来在Open AI,刚刚跳槽到特斯拉做无人驾驶的首席科学家。

他曾经拿托尔斯泰的作品来做一个学习,用机器去模拟,程序只有几百行,但就能让机器创造出来作品,虽然还达不到托尔斯泰的水平。
很多行业,都面临着这个巨大的挑战。
围棋行业已经被颠覆了,后面还有律师、金融,包括程序员,美国已经有不只一家公司做自动化编程,取代程序员的一部分工作。

上图是调用了Google的API做识别,这个人是斯坦福机器人研究室的一个博士,花一百美金左右买了这些设备,就做出来原来需要花50万美金的东西。这说明什么,说明智能应用时代是真的来临了。
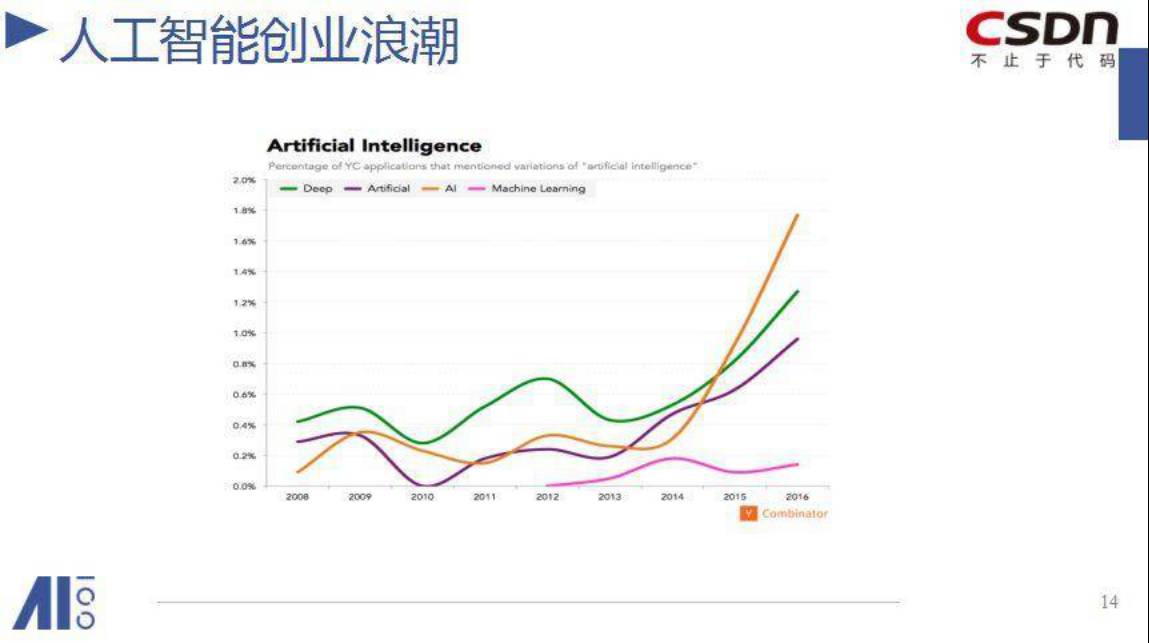
这是来自YC的分析图。从上图可以看出,学术界的突破在2012年,从2014年起进入创业高峰期,2017年进入爆发期。
AI现在被我们捧得非常热,但是要很好地解决我们实际面临的困难和问题,达到大家期望,还需要经历一个过程,我们把它分三个阶段。
AI发展的三个阶段
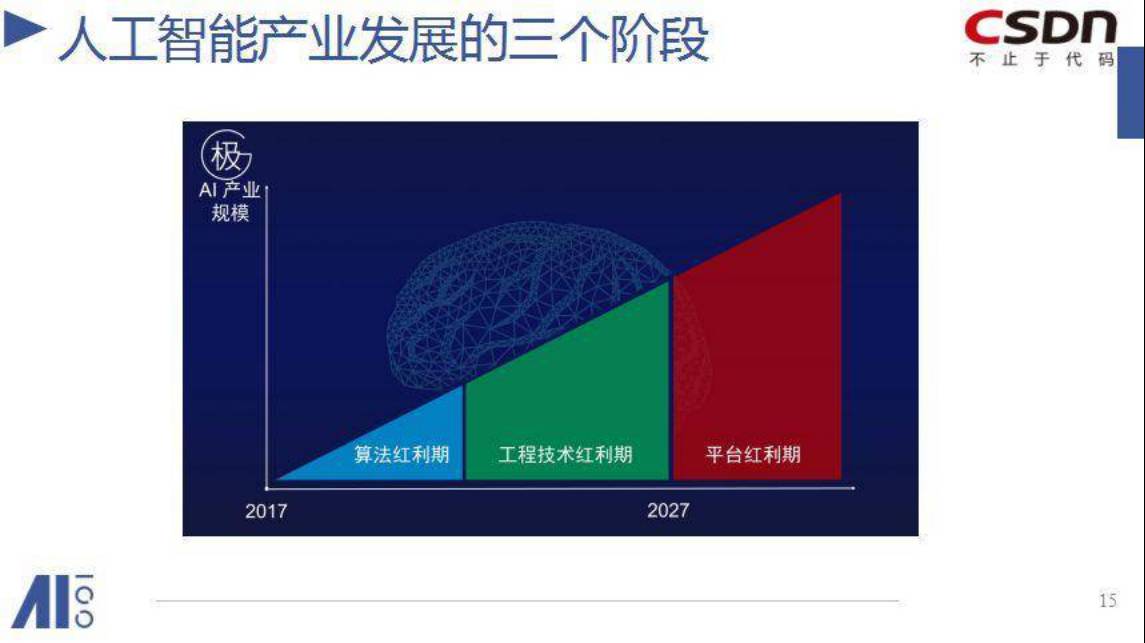
目前还是算法红利期。现在大家都下重注去挖算法的优秀人才,年薪开到上千万美金,这是一个优秀算法掌舵的时代。
学术界的进步对我们非常重要,因为论文的一个突破就可能带来技术上应用上的一个大突破,一个快速发展期。
不过这个阶段很快会稳定下来,变成局部很小的改进,不再是大的突破。
这之后是工程技术期,会在2到3年后到来,这个时期就可以真正去做出各行各业的应用,而且对这些行业会产生比较大的价值。
再后面才是平台,谁拥有最多的数据,谁就拥有最大的商业资源,谁就更强大。
我记得我很早时,跟微软谈事的时候,他们内部就说过,我们公司没有10亿美金以上收入的项目,都不会列入我们的计划。但是无人驾驶他们是可以杀进去的,这是一百亿一千亿的市场,但是我们可以在很多行业都找到这样的机会往里去切入,但是等到这个市场变得非常巨大的时候,你不一定打得过平台,或者你要先把这个平台要做的事做好,才有空间。
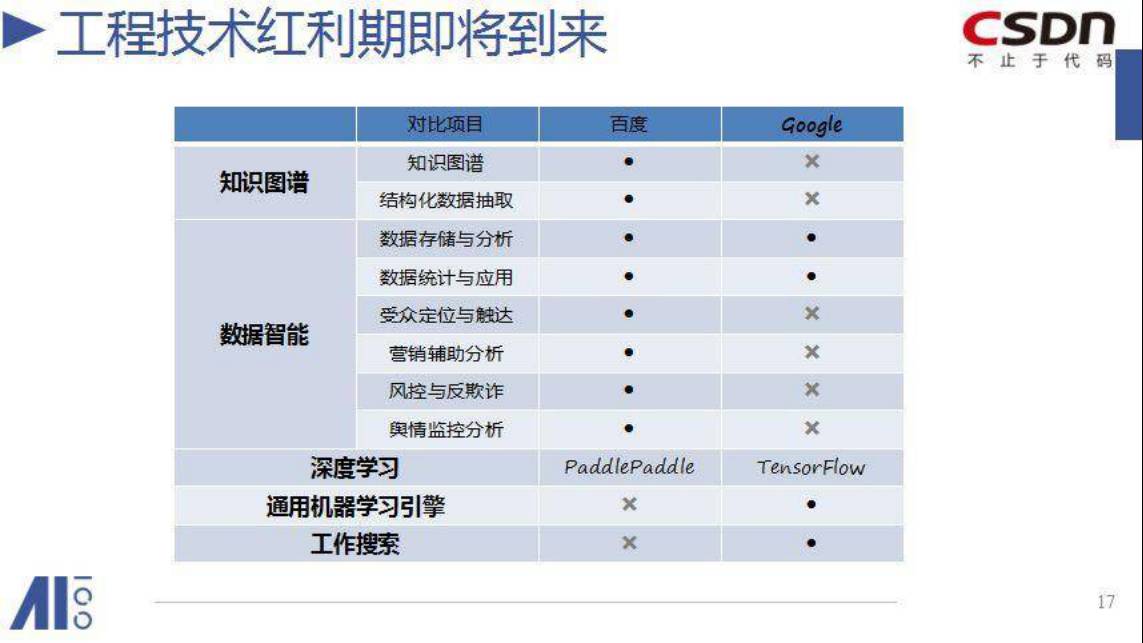
现在AI是同样的情况,我们可以调用谁呢?
Google是在这个领域做得最好,百度是目前最大,我把他们做了个对比,开放的能力大家可以去看一下,包括百度推的语音唤醒,Google现在还没有。视频内容比较分析,就是一个视频封面,我刚才讲,你怎么去选视频里面的哪一帧,作为你封面的展示页,百度也把它公布出来了,这些都是他们很大的积累了。
所以呢,这些技术的丰富,包括框架的成熟,就像安卓1.0时代,2.0时代,也不太成熟,我大概是3.0参加了Google IO大会,那时候才有了点气象,也不是像现在这样,安卓一定会胜利,大概是在4.0的时候会确定。
AI时代,我们要做什么
那顺便说说我们最近在做些什么。
最近花了很大的精力在组建我们自己的AI社区——AI100,其中媒体公众号为AI科技大本营。它可能是个升级的CSDN,或者升级版的社区。一方面我还要把工程师、专家聚集起来,为他们提供内容,交流的平台。第二方面,把行业的资源带入进来。
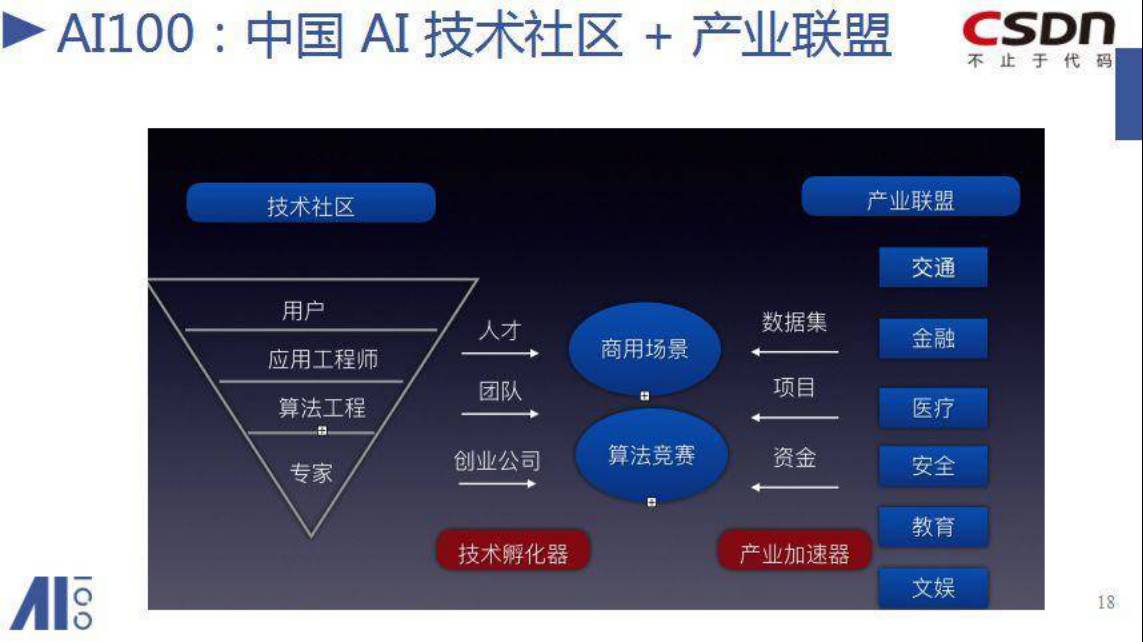
正如刚才所说,我们的基本判断是说C端的应用可能没有那么大机会,而B端有太多的事情可以做。所以,一开始,你马上切入核心业务也很难,一个是说,它固有的模式不容易马上变化;第二个是说,你也不知道从哪去切入。
所以我们现在跟这些行业分别做一些合作,把他们的数据集,它内部的商业需求和项目开放出来,甚至呢,提供相应的资金,这资金可能是作为一个项目的资金,也可能作为一个比赛的奖金。
比如说最近的一个比赛就是智能电视的项目,智能电视记录对于你看多长时间,怎么切换过去的信息,都可以记录下来,那我们用这个来做一个收视率的预测。
包括医疗行业、教育行业等都在给我们提供数据。因为对这些公司来说,你是愿意自建一个研发的团队,或者AI的研究院吗?不会,成本非常昂贵,且不一定能做的出来,所以还是通过我们这样一个新的AI社区的平台来做更省钱省力。
通过AI社区的平台,一方面我们能够做更多的尝试,一方面也能发现更多的人才,这是我们CSDN下面要做的一件主要的事情。
我们要做的是将工程师、技术和产业真正连接起来。
对工程师来说,你的成长最终是要做市场应用,这才是真正的成长。你学了这些AI,人工智能,图像识别,语音识别,我们能够给你找到应用的场所。
总结来说,我们做AI100有两点。
第一、人才的增长。假设现在有一千万名工程师,7年之内,中国应该有10%-20%的人要成为AI的工程师。
第二、每个行业都会变成一个以技术驱动和数据驱动来引领。对于企业来说,一定要了解数据在公司里面到底该怎么去应用。现在互联网公司有数据,但很多行业还不够智能,没有数据,因此我们也希望帮助三十万家企业走向智能化。

1. 人工智能产业有没有泡沫?
著名财经作家吴晓波最近发表了一篇文章,《为什么新科技的风口总火不过一年》,在文章中引用了Garner技术发展曲线,他认为人工智能目前处在第一波峰的顶点,那么很显然,马上就会面临泡沫的崩溃。如果他的判断是正确的,那么这将是第三次人工智能的泡沫破灭。
作为财经作家,吴晓波非常的博学,而且也特别的聪明,他能够很快的从一个现象当中抓住足以引爆舆论的点。但从专业角度分析的话,这个判断有问点题。从这幅图上来看,无人机、机器人和物联网已经开始爬坡了。
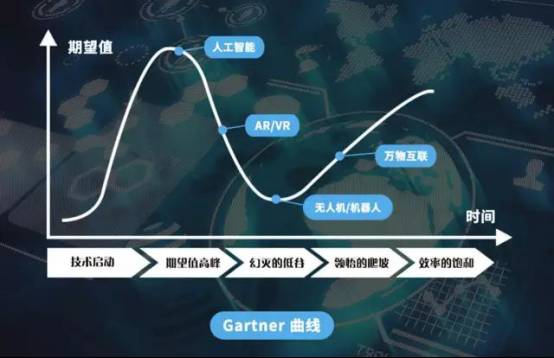
那问题来了,如果无人机、机器人和物联网即将迈上迅速成长的阶梯,你怎么可能想象人工智能会崩溃呢?因为无人机,机器人本身就是人工智能的应用平台,而物联网则是大数据的最大来源,会有力的推动人工智能的发展。大家要理解,在无人机、机器人、物联网这样的技术浪潮当中,人工智能将扮演很重要的角色。
所以我直接说我的观点,人工智能目前没有泡沫。
具体的分析一下。
第一,本轮人工智能技术的红利还没有吃完。今天人工智能的热潮,是技术上主要是深度学习的突破引发的。深度学习理论上的突破是2006年,所以大家会问一个问题,11年过去了,深度学习的红利是不是已经吃完了?
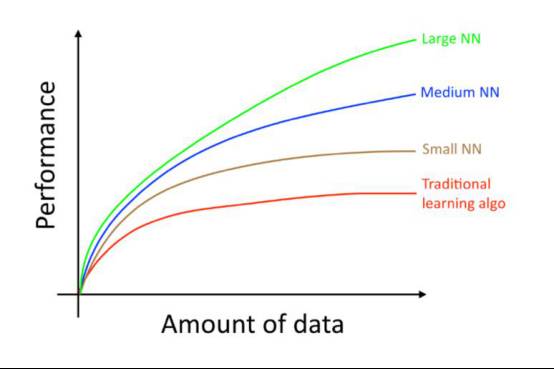
我们来看,这张图是吴恩达在一本书叫 Machine Learning Yearn的书里面一幅著名的插图,纵坐标是算法的表现,横坐标数据量。从这个图中你可以看到,对于大规模的神经网络来说,数据量越大,它的性能就会越高,也可以说它的能力越强。我问过在这方面非常顶尖的专家,目前有没有看到顶点?他告诉我说,他们有人已经做到上万层的深度神经网络,还是没有看到这个顶点在哪里。深度学习它的红利是很厚的,目前还远远没有吃完。这是第一点。
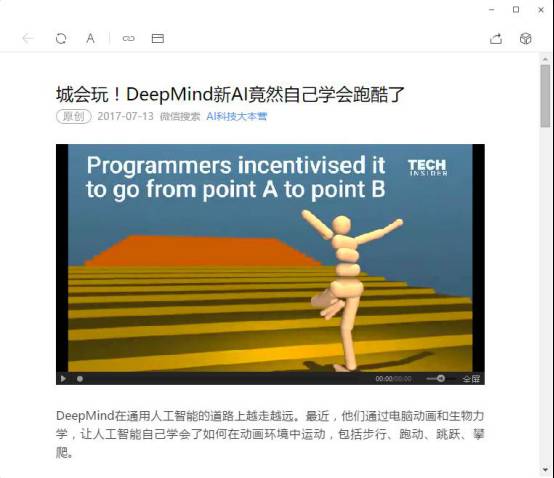
第二件事情,最近DeepMind公布了两分钟的Video,他们利用深度增强学习,教会虚拟空间的木偶走路、跳跃、跨越,甚至在漂浮的木条上保持平衡和跳跃。这些木偶并不知道什么叫走路,仅仅是给它目标,给他激励,他就自己学会了走路,自己学会了跨越障碍物,甚至可能在一些复杂情况下比人的表现要好得多。这充分展现了深度学习的潜力。
所以我们不需要看每天 arXiv 上那么多的论文,就从这些新闻事件上来看,都可以得出结论,这一代技术的红利还远远没有被吃光。
另外,我们不能光看技术,还要看这个产业。

这个是来自麦肯锡的一个报告,2013年到2016年里面,AI这个领域获得的外部投资增加了3倍,2016年的总规模达到了260亿到390亿美金之多。投资的效应是累积的,这些投资将会对 AI 的发展产生很大的拉动。
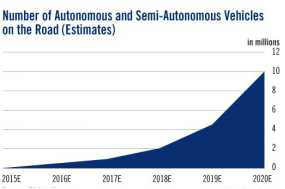
一个重点的行业是自动驾驶。同样来自麦肯锡的报告,预测从2015年到2010年,自动驾驶和半自动驾驶车辆的数量将从100万上升到1000万台。汽车这是一个几万亿美元的产业,单单只要考虑这一个产业的转型,对于 AI 就足以产生巨大的牵引力。
所以我完全不担心这次 AI 的泡沫会崩溃。
今天的 AI 整体是什么水平呢?如果你反推,从现实需求出发来对 AI 提要求,你会发现,它有很多事情确实做不到。但是如果你正推,从AI今天已经具备的能力出发,来看看我们能够解决什么问题,你会发现,在今天的AI的能力范围之内,已经可以解决很多问题,可以激发很多行业的变革。
所以如果你们认为AI有泡沫,我告诉你,泡沫只会来的更凶猛,这是第一个问题,AI是不是有泡沫?我的回答很明确,AI没有泡沫。
2. 人工智能人才薪资虚高吗?
第二个问题,人工智能的人才薪资是不是虚高。PingWest 最近发表了一篇文章,作者花了很大的功夫去做调研,写出来一篇强文,题目是《百万年薪的人的泡沫与人工智能的虚假繁荣》。文章写得很棒,我读了好几遍,也推荐所有人都去看。
这个文章的核心意思,是说现在很多 AI 的人才在市场上拿到高薪,但是却没有为企业赚到钱。有些挂着高级学术头衔的人,跑到企业里先拿个高薪爽几年,然后可能拍拍屁股就回学术圈了。
我们怎么看待这个问题。
首先,AI 和数据科学人才的高薪是个全球现象,他们现在就是在享受薪资溢价,这个是事实。我接触的很多 AI 界的人也是这么看。
我们看一下美国的情况。
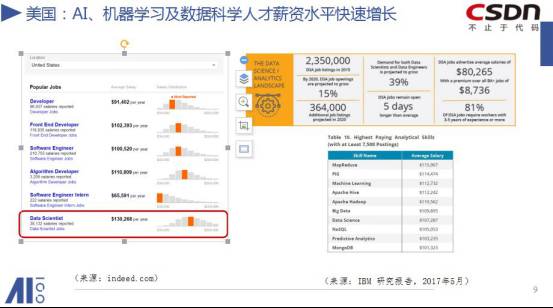
在美国,AI、机器人,机器学习与数据科学人才薪资水平目前快速增长中。你如果是程序员,你的薪资平均水平是九万一千美金,不过图中代表众数(mode)的那根柱子靠左,说明更多的人是略低于这个水平的。这说明少数的超高薪的程序员把多数低工资的程序员给平均了。而算法工程师,尤其是数据科学家,他们整体收入水平很高,均值十三万美元,而且图中代表众数的那个柱字偏右,说明超过这个收入的人群在他们整个这个人群当中也是多数。在招聘网站上,把 AI 方面人才的广告挂出去,5天时间招不到人,显著高于其他职业。意味着什么?供不应求。这个是美国的情况。
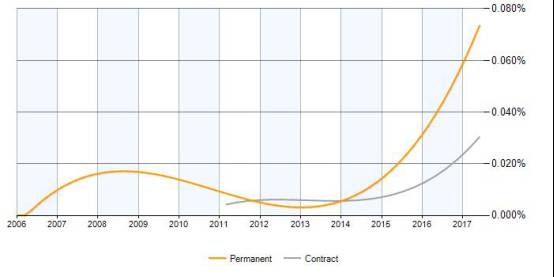
英国是全球人工智能的另一个中心。从2014年开始,英国的AI人才需求迅速的直线的上升,就是需求量迅速的上扬。
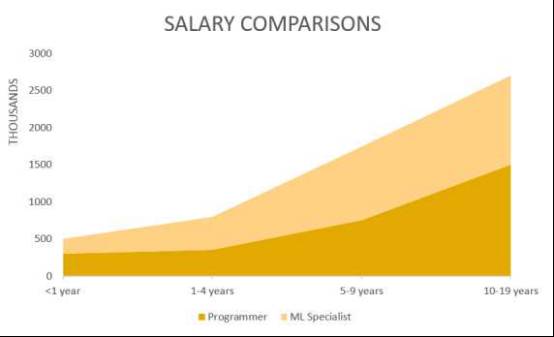
然后看印度,他们对程序员和机器学习专家的收入做了一个对比。结果呢,机器学习专家的收入不仅始终高于开发者,而且差距还越拉越大。
我们再从另外一个侧面来看一下,我们知道这个AI开发者使用的主力语言主要是Python。
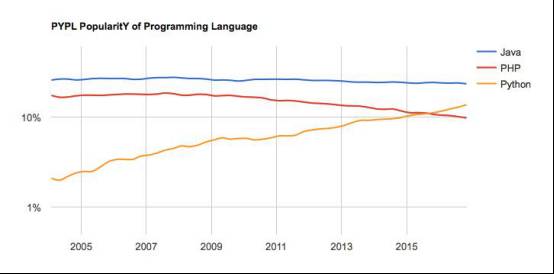
这是从2005年到2016年,这三个语言薪资水平之间的一个对比,排在上面的是遥遥领先的是Java,它在整个企业应用,电子商务开发的地位,很难被撼动,目前它的薪资是排名第一的。排名第二名的是世界上最好的语言,PHP,这个语言跟Java一直是并驾齐驱,保持不是很大的一个差距,但是到2014年,15年之后,出现了一个死亡交叉,Python语言在收入上开始超过PHP,我相信Python开发者的薪资水平超过是Java是迟早的事情,在最近两三年之内就会发生。
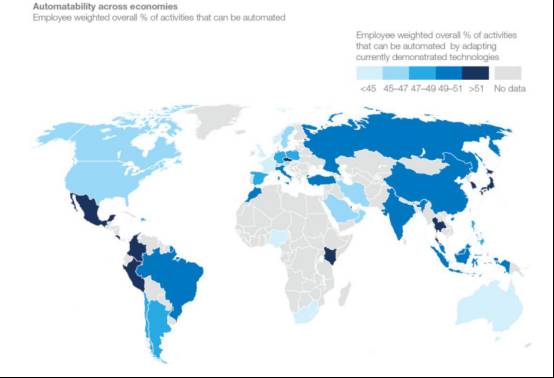
中国会怎样呢?大家看这幅图,也来自麦肯锡,在世界地图上蓝色越深的地方,当前劳动力当中可以被机器和人工智能取代的比例越高。墨西哥、玻利维亚、秘鲁这些国家,它整个自动化程度很低,所以有大量的手工工作都是可以被机器所取代的,他们是深蓝色。然后呢,像美国、加拿大、澳洲这样的国家,他们的自动化程度很高,所以他能够被机器所取代的工作的比例并不是特别高,所以是浅色的。
你看我们中国呢,是比较深的,是49%到51%,就是在我们中国的话,AI和自动化取代人力是非常有潜力的。所以呢,我认为在未来的相当长的时间里面,中国的做AI的这帮人,都将参与到一场劳动力替代当中,而且是占据优势地位的一方,享受高薪是必然的。
但是刚才那篇文章里所说的薪资泡沫也很确凿,因为我们看到呢,很多的企业,现在花了很多的钱去雇了一些一流的博士硕士,但是 AI 这个产业的规模还没有起来,这些高薪基本上是靠投资人撑着,这合理不合理?
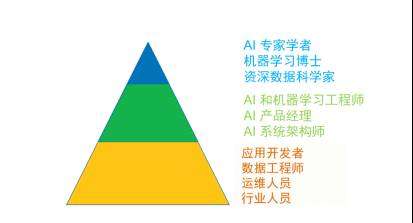
我认为事情的本质是人才结构的问题。这张图是我和蒋总讨论了很久以后我们列出来,其实一个成熟的,在未来5年以后真正赚到很多钱的人工智能企业,它的人才结构应该是这个样子的,应该是AI专家学者,机器学习的博士们,资深专家比较多;然后呢,应该有一大堆AI的机器学习工程师,AI的产品经理、架构师在这里。更重要的底下有大批的开发者,数据工程师,运维人员,行业人员,这是一个合理的结构。
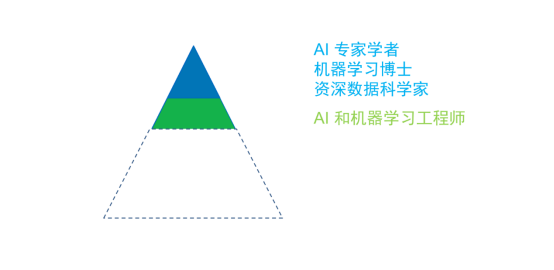
但是实际情况,目前市场上独立的人工智能初创企业,普遍严重缺乏优秀的产品、工程和运维人才。有些公司非常得意的宣传说,你看我的团队里,一流名校博士占百分之多少,比 Google、Facebook、微软高多了。但其实这样的构成恰恰有问题,这种团队的工程化、产品化能力会成为瓶颈,从而制约他们赚钱的能力。很简单,用户只会为产品和服务买单,不会为论文、算法和你们的学位买单。正是这样的反差,让一部分人觉得这里头有泡沫。
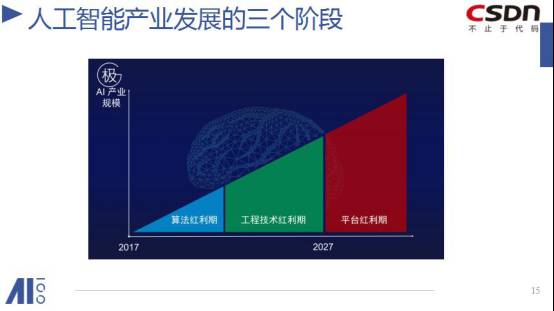
那么怎么办呢?我主张不要着急,把这个事情交给市场。投资者不傻,他们很清楚,现在我们处在算法红利期,算法领域还不断的有突破,所以我们先把懂算法的人找来,花钱养着他,先把论文看懂,先突破,往前突破。
但是算法红利期还有个两三年可能就要结束了。这不是说算法不会有进步了,还是会有很大的进步,但是呢,从算法的突破,到工具化,这个转化路径现在变得很顺畅,两三年之后会更顺畅。如果你有一个算法突破,发表论文出来,很短的时间内,几个月,甚至几周内,Github 上会有实现出来,甚至你可能会看到百度、谷歌把新的算法放在自己的开放API里面,这就意味着,企业竞争主要拼的就是工程能力和产品能力了。到那个时候,整个 AI 产业里的薪资水平会有更合理的分布。
我说一下我的结论。所谓的人才泡沫问题,只是一个暂时性的现象,是发展的一个必然过程,不需要担心。
3. 数据科学向左,人工智能向右
我再说第三个问题,选择方向的问题。
我们现在叫广义 AI,其实里面大致包含两个工作性质差别挺大的方向。一个是商业分析与优化,一个是智能产品与解决方案。
两者主要的不同是谁来做决策,人做决策还是算法做决策,这个决定了自动化程度的高低。
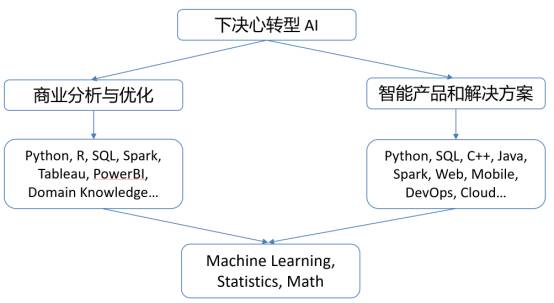
商业分析与优化技术的应用的周期当中,人仍然在里面扮演很重要的角色,数据分析是用来辅助人类决策的,自动化水平受到人的决策的制约,不会太高。
另外一个方向叫做智能产品和解决方案,自动驾驶、扫地机器人、自动广告投放系统,都是这类。整个产品的执行过程基本上是完整的,很少需要有人干预,决策主要由机器来完成,自动化程度接近 100%。
大家很快会面临方向上的选择,你是走左分支,还是走右分支,这件事情你们要好好的想一想。左边这一支走下去,你可能会成为数据分析师、数据科学家、CDO。右边这一支走下去,你应该会成为 AI 工程师、AI 产品经理,CTO。
走左分支,你的关键是获得高质量的业务数据。在中国,这个事情难度很大。
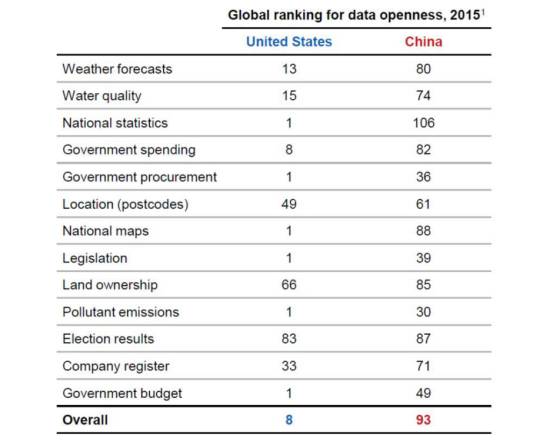
这个是最近的一个全球数据开放度调查,美国排名第8,中国排名第93。如果你们想走左分支,尽可能加入到一些具有数据访问特权的机构,否则想在中国想低价拿到别人的数据是很难的。
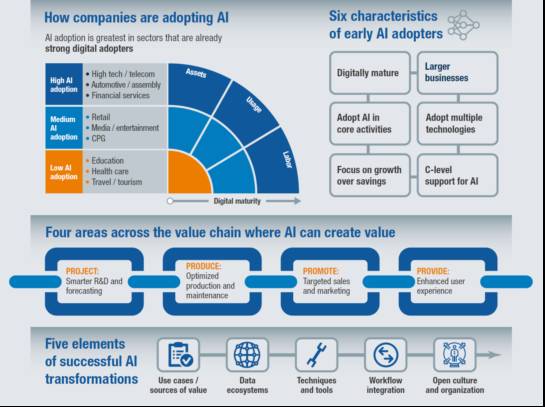
那么怎样选择行业呢?麦肯锡给了六个原则,
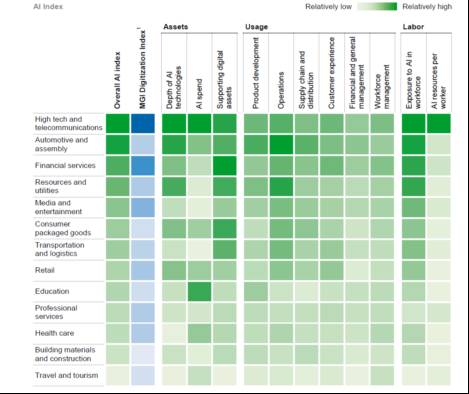
选择方向的时候,用这六把尺子来量一量,就会有一个大致的判断。这是麦肯锡的一个行业分析,排在第一名的,叫做高科技和电信,就是它各个领域里面绿的比较多,如果你们在这个领域做AI比较容易。今天大部分在互联网领域里,你们可能在这个领域里面做AI比较容易,因为数据也比较全,各方面的支持也比较到位,人的意识到位。随后分别是汽车和生产线、金融、电力、娱乐传媒、零售等行业。我们现在很多人都在谈医疗的大数据,医疗的AI化,但是其实呢,这个行业的准备度是不足的,做这个方向,要克服很大的难度。
其他的行业不一一解释了,谢谢大家。
Part 3 智亮:你是我的眼——对计算机视觉的介绍

今天我们主要聊的是计算机视觉,咱们先从最大的概念开始说一说,人工智能,机器学习,计算机视觉。
人工智能这个概念一点都不新,机器学习也一点都不高深,那个计算机视觉也谈不上神奇,为什么这样说?
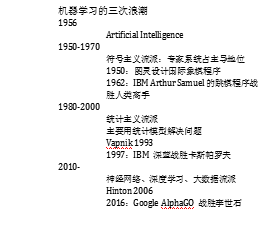
我们人工智能实际上在历史上,浪潮至少三次。
第一次50年代到70年代,叫符号主义流派,专家系统占主导地位。
什么叫专家系统?就是人去学一个东西,然后把学到的知识理论化,再把这些理论模型化,最后把这个模型程序化,形成一个系统,就叫专家系统。
专家系统巅峰在1962年,IBM公司的跳棋,战胜了当时的人类高手,引爆了第一次浪潮。
专家系统能解决一些问题,但是也解决不了很多问题。
到了1980年,统计时代开始盛行。统计流派巅峰在1993年,Vapnik系统性的提出了一篇论述叫支持向量机,现在这个算法在很多地方被大量的使用,它非常有效。
引爆第二波浪潮的重点就是1997年,IBM的深蓝战胜了当时的国际象棋冠军卡斯帕罗夫。

2016年的阿尔法狗引爆了第三波浪潮,我们这一波的流派现在还没有名字,我更倾向于把它叫暴力流派。
2006年Hinton提出过一个经典的论文,Hinton这篇论文虽然在2006年提出,但是我们神经网络是一个非常老的概念,它的前身要追溯到1986年的多层感知器反向传播算法。
这里边还有一段历史公案,就是Vapnik老爷子和Hinton老爷子,他们学术矛盾很深,在80、90年代外面SVM一个占据主流的时候,神经网络被打压到连论文都发不出去,业都毕业不了。现在老爷子算是打了一个翻身仗。
刚才说到我们三次浪潮,前两次每次都是这样,说人类要毁灭了,后来发现其实并不是这样。
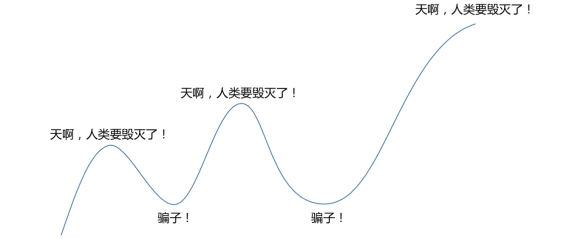
我们现在就处在这个状态,人类又要毁灭了。其实和前两次比,还是有一点区别。
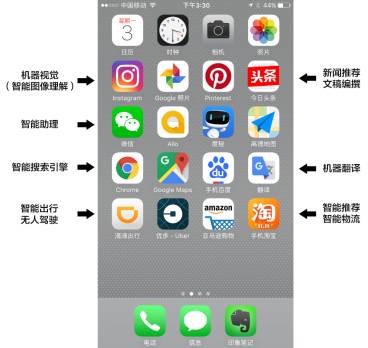
我觉得最大的一个区别就是它现在真的是深入到我们生活的每一个角落,打开你的手机看看,淘宝,智能推荐,拍一拍,谷歌翻译,搜索引擎,智能出行,智能规划,微信,智能助理,头条,智能推荐,还有机器识别,其实它已经深入的改变了我们生活的每一个角落,而将来它会改变更多。
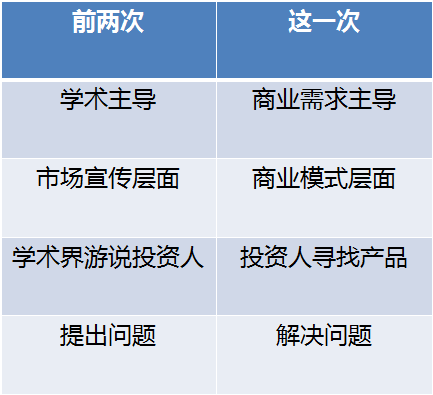
然后我们刚才说为什么机器学习一点都不高深。当年,Vapnik老爷子他提出支持向量机有一个核心概念,这个世界是线性可分的。
什么叫线性可分呢?线性就是一条直线,二维空间里它就是一条直线,三维空间里它就是一个平面,他认为这个世界用直线能全分割开,在我们的二维世界给它变一个纬度也能分开。
有点像我拿着一堆木球和铁球,你在它们在地上滚,然后你让它一刀切,分成两堆这是不可能的,但没关系,我把它放到水里,木球漂起来,铁球沉下去,横着来一刀,这就是支持向量机的核心理念。
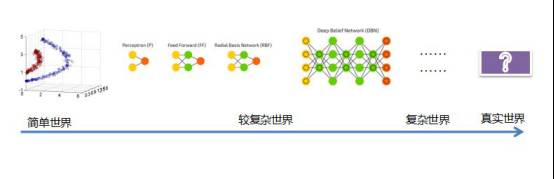
虽然有些时候是这样的,但是并不是所有时候都能够成立,所以支持向量机当时只能解决简单世界的问题。
而神经网络是用了一个比较复杂的结构,多层感知机。
现在深度神经网络用了一个非常复杂的多层、高阶的结构,然后去拟合我们现实的世界,它比支持向量机要成功得多。但是如果说它真的能够拟合我们真实世界的所有情况,其实还差那么一点意思。这也就是说为什么我说,机器学习或者神经网络没有那么高深。
它本质上不对这些问题进行数学上的建模,我就是用一个很复杂的神经网络,做出了一个足够复杂的方程,Y等于F(X),这个方程参数非常多的,阶数高,非常的巨大,我们的输入是X,这个方程给我们算出来Y。
然后我们比如说我们看一张图片,我们这张图片输入就是X,一只猫,这只猫它真的是一只猫,我们的期望就是这个F(X),计算出来的结果等于猫,这就是我们目标,怎么让它等于呢?就是我们用大量的数据不断的迭代。
当年,Hinton老爷子提出这个东西之后,被Vapnik老爷子批评,说你这个东西一点数学的美感都没有,Hinton老爷子在数学成就上确实不如Vapnik他老人家,这也是历史公认的。但是一句话,我好使,我有用。
但是现在也有人质疑什么呢?我们这么算出来的东西,为什么?什么原理啊?它怎么就好使了呢?不知道,但是我们知道,这个复杂的非线性方程,它能够在某种程度上模拟出来我们真实世界的情况,但它具体怎么模拟的,是一个黑箱,我们都不知道,阿尔法狗下棋能赢柯洁,没问题,但是你让他去教围棋,那是一把瞎,别说阿尔法狗教不了,写阿尔法狗的人也教不了。
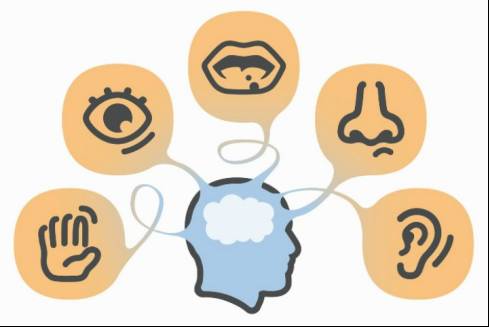
再说智能,我们的大脑就是一个典型的智能。
佛家有六识,眼、耳、鼻、舌、身、意,它对应的是六尘色、香、声、味,触、法。视觉,听觉,嗅觉,味觉,触觉,以及我们的思考,这个构成了我们的智能。
而计算机如果想有智能,它首先也得有这些感官,有输入才能有思考,有思考才能有输出,有了输入、思考和输出,它才有智能。而我们今天主要讲的就是在我们生活中,我们最大的信息来源,视觉。放在计算机上,就是计算机视觉。
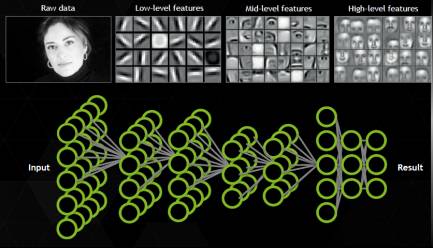
当前的计算机视觉,它的技术上一般是有叫卷积神经网络。这个东西就是用大量的神经网络堆叠起来。
比如,给一个输入说,这是个人,而且是个女人,计算完了以后,得到输出,只要这个网络得出的是个女人,就OK。换句话说,我给它的每一个训练数据,我都告诉他正确答案是什么,这个就是监督式学习。
然后呢,它和以前的模式识别,特征检索,是有比较大的区别,区别在哪里?
其实它也有特征提取和特征检索,为什么说有区别?
区别在这,它的特征不是我们告诉的,不是我们编码,不是我们手工设定,而是通过大量的数据,它自己学习出来的,这也是神经网络和以前的所谓专家系统最大的区别。
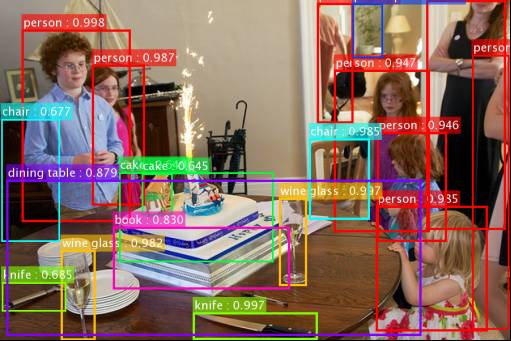
那我们来看看,单就计算机视觉这个领域它能做什么。上图就是大家现在能做得非常好甚至超过人的一个例子,在这张图片里面,有很多东西,计算机能够把它分析出来。它能够从一个图片里面区分出不同的物体,并且辨别出它们是什么,在哪里,这是能做得事情。

这张图是毕加索的公牛,毕加索在画这一系列的图时有一个目的,说我画的公牛跟真的公牛一模一样,你能认出来,说明我画的好,如果我画的跟真实的公牛不一样,你们是怎么认出来?
我全涂成黑的,是牛;我再黑一点,细节全都丢失了,还是牛;那我把纹理去掉,把形状变一下,把各种全都抽象起来,到这还是跟我们平时看到的比较接近,画到后来还有人认为是牛,那么对人来说牛到底是什么东西?为什么这个样子是牛?这就是抽象。
我要说的就是计算机视觉现在有两个非常大的不能做的事情,第一就是抽象。
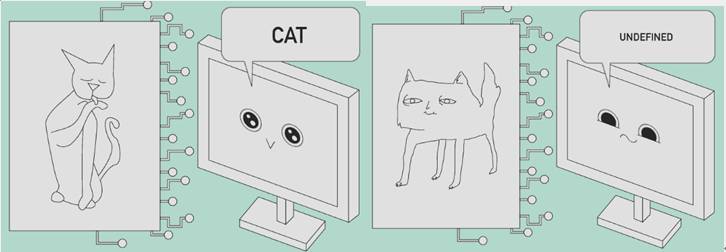
第二件事情很有意思,看上图,计算机第一反应有可能是猫,但是再仔细看看,就不认识了。我们的计算机视觉至少在目前这个阶段,它不知道自己不知道,这个事它做不到。
这两个事,一个是看到抽象的东西它认识,另外一个是看到不认识的东西,它知道自己不认识。在目前的卷积神经网络这个结构下,计算机是做不到的,它并不是万能的。
当然它也能做很多事情,接下来,我就仔细的看一下,卷积神经网络的一个大致的发展历程。
卷积神经网络开拓者Yann LeCun做了一个非常简单的卷积网络,去做手写数字的识别,也就是我们现在每个人初入机器学习,一定接触到的一个Mnist。
他做了一个数据集,用了一个卷积神经网络去计算一个手写的数字,它到底是一二三四五六七八九中的哪一个。这个东西做的非常的成功,美国的邮政和银行都在用,但是并没有产生太大的反响,因为支持向量机,也能做到同样的事情。
第二个,Alex,刚才两位老师也提过,他也是老爷子的学生。2012年,他刷爆了计算机视觉的比赛,以碾压性的优势,干掉了所有的SVM的东西,从那以后卷积神经网络才成为了计算机视觉的标配。
第三个人,何凯明,微软亚洲研究院出来的,2015年他提出的参加网络也是卷积神经网络的一种。这一年,计算机在Imagenet的比赛成绩超过了人类,虽然不像阿尔法狗那么有名,但是在计算机视觉史上这个时间点是要被铭记的。
下一个时代在哪里?是不是在你们中间,我也不知道。
介绍完了历史,我们来看一看卷积神经网络最大的特点。这个特点在于它能够自己去学习这些特征,我们看一下一个非常经典的一篇论文,叫做《Visualizing and Understanding ConvolutionalNetworks》,非常有名。
他们做了一个实验说,我训练一个非常简单的积卷神经网络,训练出来之后,我想看一看究竟学到了什么,大家都说它是黑箱,那我们打开看一下,到底学到了什么东西。

第一层,他们发现,都是非常简单的直线,斜线,各种颜色,这些非常简单的纹理。用这种形状的卷积核能够把图片上面的线条区分出来。这个网络在没有任何人工指定的情况下,大量的学习数据网络,它天然学到的,非常的巧合,或者说也是必然。
第二层,每个九宫格是个神经元,在我们用大量数据去输入它的时候,它会给出一个反馈。这个反馈是一个数,越高,代表它越兴奋,对这个输入越敏感。
它在所有的数据里面,找出了让这个神经元最敏感的九张图,并且通过反卷积的方式把它计算出来,它不代表这个神经元就是这个内容,而是这个神经元对这样内容的东西最为敏感。我们能看到第二层里面出现了圆形和各种角度的弧线,我们在大量的观察之后,得出一个判断,这个网络的第二层对形状敏感。
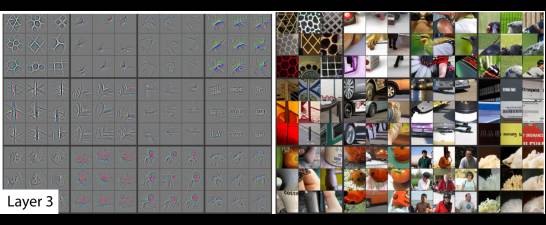
第三层,我们看到的纹理有点像长颈鹿,在经过大量的数据研究之后呢,我们认为它的第三层是对形状,纹理,这些信息比较敏感。

第四层,就开始对纹理形状结合,是对形状和纹理的复杂结合开始敏感。
第五层的时候,它就开始把所有的信息结合起来,形成一个高阶的概念。比如,我对狗敏感,我对花敏感,我对人脸敏感,它在一层一层这样不断递进之后,把上一层的信息,结合起来,然后形成下一层的输入,通过不断的训练自己,让每一层的神经元对不同的信息产生反映。

计算机视觉这个领域,它现在的课题大概就是这么几个。
首先就是识别,比如,这张照片,我能说出来它是人,那么就OK。
然后就是检测,检测的目标是我不但要说出来这个照片都有哪些东西,我还要知道它在哪一块。
再然后是语义分割,就是我画框已经满足不了我,我要精确的描绘出来这个人的轮廓,我要把有语义的东西从背景里面挑选出来。
最后一个叫描述,比如我给你一张图,你要给我一句话,一个女人和孩子在看电视,如果我们粒度再细腻点,还要说电视里面有一只狮子,这就是我们描述要做得事情。
识别检测分割和描述,就是当前计算机视觉的四个重要课题,现在很多论文都是围绕着这几个方面。
识别已经超过人了;检测还比人差点,但是不会差特别多;语义分割差的稍微远点,人能画出来,它不一定能画的像;描述,英文方面,现在是大概能看,说出来的东西比较靠谱,中文,基本上是一个空白,现在大概就是这样的情况。

然后如果说我们刚才看到的识别,检测,分割和描述,是我们现在在研究的这个领域,那么它的未来在哪里?
这是我个人的判断,首先说我们人在看到这个世界的时候,不是通过一张张的照片去认识这个世界,我们看到的是连续的,流动的物体,我们在大脑里面接受的是视频,这个也是视觉的一个发展方向,它未来必然是以视频或者序列为基础。
第二个大的发展方向,就是理解和分组,像上图,我们人一看到,就知道这是草地上有一条公路,公路上有一辆车,有一个树把车挡住了,在我们的脑海里是这个样子。但是计算机确实不是这么理解的,而让他能够这样去理解问题,就是我们未来的一个研究的目标。
第三个,叫无监督和One-Shot。比如,我们现在都知道Imagenet这个大赛,它一共有1000个类别,每个类别平均下来有一千张图像,加在一起是一百多万张图片,每张图片都有标签,都告诉你这张图片是什么东西。
所以大家现在看到的很多这种检测都是这样,为什么呢?因为他们只有Imagenet这样一个大量的数据都有标签,我们倒是想训练出来一个能识别其他的东西的,但是没数据。
所以未来我们的方向有一个很重要的分支,我们怎么样能够缩减数据的需求量,最好是什么呢?我给你图片,哪怕一千万张都可以,但是你别让我每张数据我都给它标个标签,太累。
无监督学习是个分组的过程。举个例子,分组的过程就相当于是,我看到无数只猫的图片,我不知道它叫什么,但是我知道所有这些猫都是同一个东西,当我把猫这个概念抽离出来以后,你给我一张照片,说这个物体叫做猫,我瞬间就明白了猫这个概念,这个是我们的无监督学习。也是我认为非常重要的一个方向,甚至说能不能够改变我们未来的产业的格局,就是最后一点。
如果说每一个数据都要监督,每一个分类都要一百张带标签的图片,那就只有Google、BAT这样的公司玩儿得起这个产业,但是如果当无监督出现之后,我们会看到,整个这个人工智能或者叫计算机视觉这个领域,会进入到一个群雄并起的局面,这个技术的成功,或者失败决定了未来的产业化的发展方向。
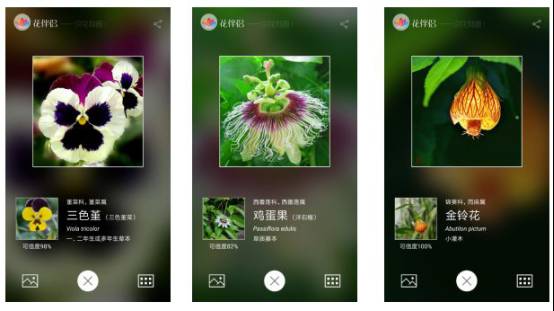
介绍一下目前用计算机视觉技术做的一些市面上的应用,这个东西就是我们做得一个识花的东西,对着一个花,拍张照片,我告诉你它是什么,从技术本身来讲其实没有太大的难度,就是一个简单的识别。

然后还有一个比较有意思的东西,Prisma,用到的是英文,给你一张照片,选定一个名作,比如梵高的星空,选定一个艺术风格之后,对这张照片进行应用,我们得到一个内容还是这张照片,但是风格变成了星空,或者呐喊的这样一张图片。
为什么把它们两个提出来呢?因为这两个应用用的技术都不难,投入也非常的小,像我们花伴侣,第一个用了一个星期训练,一个下午写APP,出来之后,大概四个多月的时间就有了一百多万的用户,最可怕的是什么呢?它从0到十万,花了三个月的时间,然后到三月的时候,春天来了,野花开了,一个月的时间,从十万变成一百万。而Prisma是5周,一千万用户。
我们并没有用多复杂多高深的技术,都是计算机视觉技术一个简单的应用,但是引爆了我们的社会,这也是我们为什么要去了解计算机视觉,了解机器机学习技术的原因,因为在之前这些技术并不是保密,是公开的,他们都流传在学术界。
我们为什么说机器学习是个的大的机会,学术界的宝藏,刚才两位老师也提到了,算法的红利,在于把它拿到工业界,学术界已经玩儿的不爱玩儿的东西,但是你把它向公众开放,让大家看到它能做什么之后,往往会爆发出连你自己都想象不到的一个巨大作用。
然后接下来就介绍一些前沿的尝试,这个是从16年开始,在学术界就非常热门的一个叫对抗生成网络的技术。
意思就是说我有两个网络,一个网络不断的去创造出来东西,相当于各种各样的造假;而另外一个网络呢,我就去负责分辨真伪,这两个网络不断的去训练自己,去提升自己。
造假一张接着一张的往外造,分辨网络再去分辨是真是假,这样它们两个在不断对抗磨合的过程中,只要有训练数据,就等生成一个以假乱真的东西。

这个是对抗生成网络的一个例子,你用手画个猫的轮廓出来,它给你生成一只猫,但是很快被人玩儿坏了。左边这样的东西,大家能够说很像是猫。但是右边呢?真正能像人一样,画出来的都像猫吗?有一定的距离,但是这个技术现在确实是未来的一个非常重点的一个方向。

这几张图是哪位大师的作品呢?我们肯定不知道,因为都是电脑画的,没有一张是人画的,但是看起来好像都很厉害的样子。计算机造了大量的图片出来,然后让人去挑,说哪个你觉得最有艺术价值。

然后这个呢,是挑战对世界的理解,为什么这么说?上边大家看到的是真实的行车记录仪拍摄下来的记录,下边这个是计算机根据第一帧的真实的画面,自己训练的生成后面的画面,凭空生成,无中生有,这也是对抗神经网络的一个非常可怕的点,也许有一天你看到的视频,你根本就不知道是真是假。

最后一个,是比较老的论文,但是我觉得代表了很多东西,就是它不光是能够学习图片上的特征,它还能学习它的语义。大家看,我有一堆照片训练出来说第一个戴眼镜的是男人,然后剪掉一个男人,加上一个不戴眼镜的女人,得到的是戴眼镜的女人,这篇论文非常的有意思,后来没有在语义上面学术界没有跟得太紧,但是这可能是我们未来一个很大的一个爆发点,很有意思。
【完】
7月22-23日,本年度中国人工智能技术会议最强音——2017 中国人工智能大会(CCAI 2017)即将在杭州国际会议中心拉开序幕。汇集超过40位学术带头人、8场权威专家主题报告、4场开放式专题研讨会、超过2000位人工智能专业人士将参与本次会议.
目前,大会门票火热发售中,扫描下方二维码或点击【阅读原文】火速抢票。











