(点击
上方公众号
,可快速关注)
出处:LBD
linbingdong.com/2017/02/10/全球分布式数据库:Google%20Spanner(论文翻译)/
如有好文章投稿,请点击 → 这里了解详情
5. 实验分析
我们对 Spanner 性能进行了测试,包括复制、事务和可用性。然后,我们提供了一些关于 TrueTime 的实验数据,并且提供了我们的第一个用例——F1。
5.1 微测试基准
表 3 给出了一用于 Spanner 的微测试基准(microbenchmark)。这些测试是在分时机器上实现的:每个 spanserver 采用 4GB 内存和四核 CPU(AMD Barcelona 2200MHz)。客户端运行在单独的机器上。每个 zone 都包含一个 spanserver。客户端和 zone 都放在一个数据中心集合内,它们之间的网络距离不会超过 1ms。这种布局是很普通的,许多数据并不需要把数 据分散存储到全球各地)。测试数据库具有 50 个 Paxos 组和 2500 个目录。操作都是独立的 4KB 大小的读和写。All reads were served out of memory after a compaction,从而使得我们只需要衡量 Spanner 调用栈的开销。此外,还会进行一轮读操作,来预热任何位置的缓存。
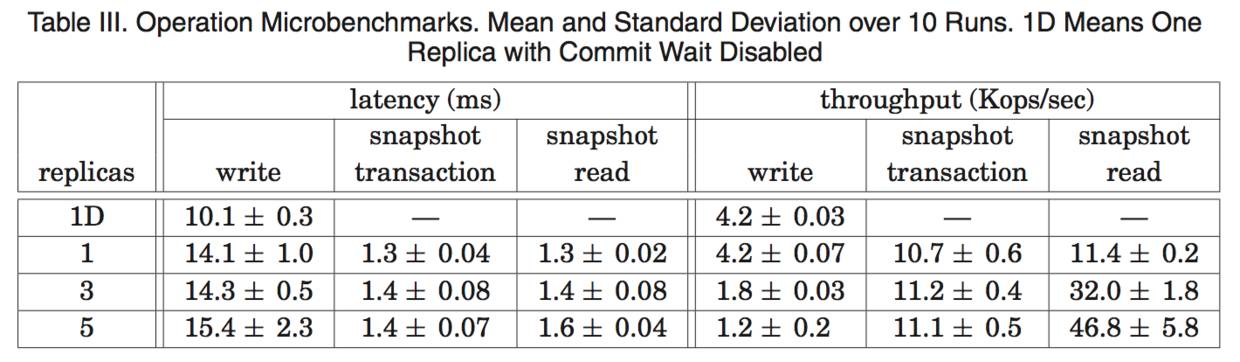
对于延迟实验而言,客户端会发起足够少量的操作,从而避免在服务器中发生排队。从 1 个副本的实验中,提交等待大约是 5ms,Paxos 延迟大约是 9ms。随着副本数量的增加, 延迟大约保持不变,只具有很少的标准差,因为在一个组的副本内,Paxos 会并行执行。随着副本数量的增加,获得指定投票数量的延迟对一个 slave 副本的慢速度不会很敏感。
对于吞吐量的实验而言,客户端发起足够数量的操作,从而使得 CPU 处理能力达到饱和。快照读操作可以在任何足够新的副本上进行,因此,快照读的吞吐量会随着副本的数量增加而线性增加。单个读的只读事务,只会在领导者上执行,因为,时间戳分配必须发生在领导者上。只读事务吞吐量会随着副本数量的增加而增加,因为有效的 spanserver 的数量会增加:在这个实验的设置中,spanserver 的数量和副本的数量相同,领导者会被随机分配到不同的 zone。写操作的吞吐量也会从这种实验设置中获得收益(副本从 3 变到 5 时写操作吞吐量增加了,就能够说明这点),但是,随着副本数量的增加,每个写操作执行时需要完 成的工作量也会线性增加,这就会抵消前面的收益。
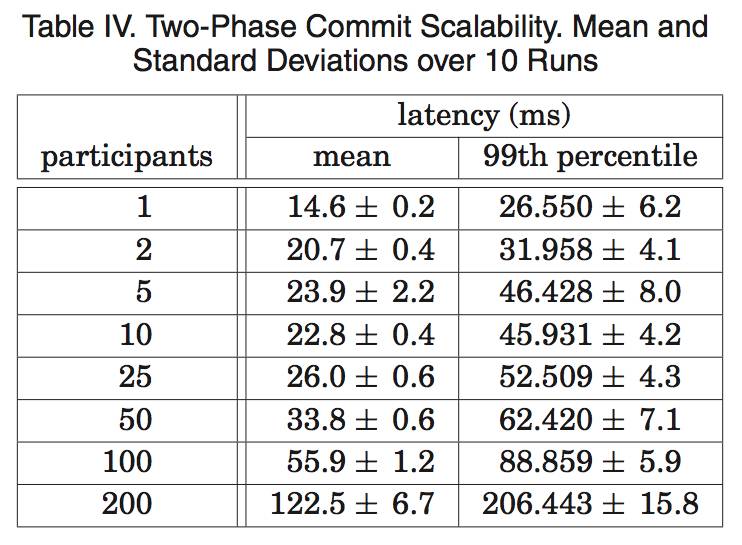
表 4 显示了两阶段提交可以扩展到合理数量的参与者:它是对一系列实验的总结,这些实验运行在 3 个 zone 上,每个 zone 具有 25 个 spanserver。扩展到 50 个参与者,无论在平均值还是第 99 个百分位方面,都是合理的。在 100 个参与者的情形下,延迟开发明显增加。
5.2 可用性
图 5 显示了在多个数据中心运行 Spanner 时的可用性方面的收益。它显示了三个吞吐量实验的结果,并且存在数据中心失败的情形,所有三个实验结果都被重叠放置到一个时间轴 上。测试用的 universe 包含 5 个 zone Zi,每个 zone 都拥有 25 个 spanserver。测试数据库被 分片成 1250 个 Paxos 组,100 个客户端不断地发送非快照读操作,累积速率是每秒 50K 个读操作。所有领导者都会被显式地放置到 Z1。每个测试进行 5 秒钟以后,一个 zone 中的所有服务器都会被“杀死”:non-leader 杀掉 Z2,leader-hard 杀掉 Z1,leader-soft 杀掉 Z1,但是,它会首先通知所有服务器它们将要交出领导权。
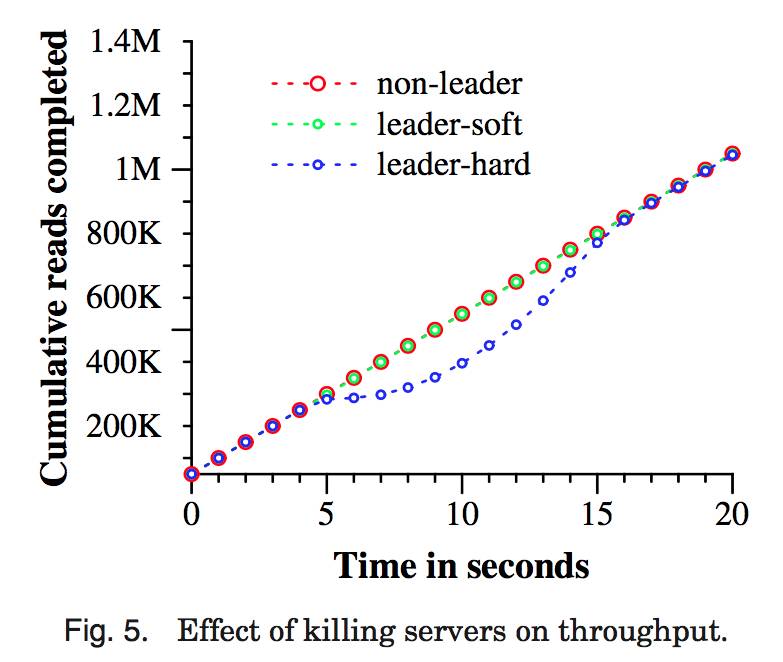
杀掉 Z2 对于读操作吞吐量没有影响。杀掉 Z1,给领导者一些时间来把领导权交给另一个 zone 时,会产生一个小的影响:吞吐量会下降,不是很明显,大概下降 3-4%。另一方面,没有预警就杀掉 Z1 有一个明显的影响:完成率几乎下降到 0。随着领导者被重新选择,系统的吞吐量会增加到大约每秒 100K 个读操作,主要是由于我们的实验设置:系统中有额外的能力,当找不到领导者时操作会排队。由此导致的结果是,系统的吞吐量会增加直到到达 系统恒定的速率。
我们可以看看把 Paxos 领导者租约设置为 10ms 的效果。当我们杀掉这个 zone,对于这 个组的领导者租约的过期时间,会均匀地分布到接下来的 10 秒钟内。来自一个死亡的领导者的每个租约一旦过期,就会选择一个新的领导者。大约在杀死时间过去 10 秒钟以后,所有的组都会有领导者,吞吐量就恢复了。短的租约时间会降低服务器死亡对于可用性的影响, 但是,需要更多的更新租约的网络通讯开销。我们正在设计和实现一种机制,它可以在领导者失效的时候,让 slave 释放 Paxos 领导者租约。
5.3 TrueTime
关于 TrueTime,必须回答两个问题: ε 是否就是时钟不确定性的边界? ε 会变得多糟糕? 对于第一个问题,最严峻的问题就是,如果一个局部的时钟漂移大于 200us/sec,那就会破坏 TrueTime 的假设。我们的机器统计数据显示,坏的 CPU 的出现概率要比坏的时钟出现概率大 6 倍。也就是说,与更加严峻的硬件问题相比,时钟问题是很少见的。由此,我们也相信,TrueTime 的实现和 Spanner 其他软件组件一样,具有很好的可靠性,值得信任。
图 6 显示了 TrueTime 数据,是从几千个 spanserver 中收集的,这些 spanserver 跨越了多 个数据中心,距离 2200 公里以上。图中描述了 ε 的第 90 个、99 个和 99.9 个百分位的情况, 是在对 timemaster 进行投票后立即对 timeslave daemon 进行样本抽样的。这些抽样数据没有考虑由于时钟不确定性带来的 ε 值的锯齿,因此测量的是 timemaster 不确定性(通常是 0) 再加上通讯延迟。
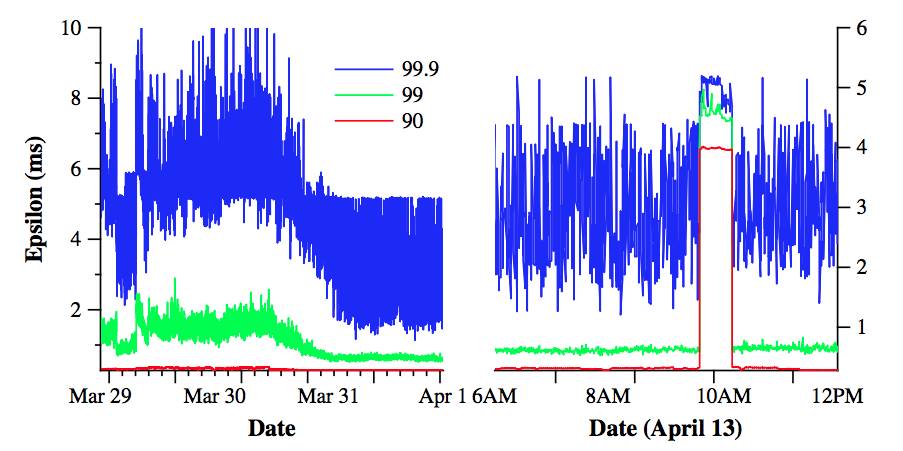
图 6 中的数据显示了,在决定 ε 的基本值方面的上述两个问题,通常都不会是个问题。 但是,可能会存在明显的拖尾延迟问题,那会引起更高的 ε 值。图中,3 月 30 日拖尾延迟的降低,是因为网络的改进,减少了瞬间网络连接的拥堵。在 4 月 13 日 ε 的值增加了,持续了大约 1 个小时,主要是因为例行维护时关闭了两个 time master。我们会继续调研并且消除引起 TrueTime 突变的因素。
5.4 F1
Spanner 在 2011 年早期开始进行在线负载测试,它是作为谷歌广告后台 F1[35]的重新实现的一部分。这个后台最开始是基于 MySQL 数据库,在许多方面都采用手工数据分区。未 经压缩的数据可以达到几十 TB,虽然这对于许多 NoSQL 实例而言数据量是很小的,但是, 对于采用数据分区的 MySQL 而言,数据量是非常大的。MySQL 的数据分片机制,会把每个客户和所有相关的数据分配给一个固定的分区。这种布局方式,可以支持针对单个客户的 索引构建和复杂查询处理,但是,需要了解一些商业知识来设计分区。随着客户数量的增长, 对数据进行重新分区,代价是很大的。最近一次的重新分区,花费了两年的时间,为了降低风险,在多个团队之间进行了大量的合作和测试。这种操作太复杂了,无法常常执行,由此导致的结果是,团队必须限制 MySQL 数据库的增长,方法是,把一些数据存储在外部的 Bigtable 中,这就会牺牲事务和查询所有数据的能力。
F1 团队选择使用 Spanner 有几个方面的原因。首先,Spanner 不需要手工分区。其次, Spanner 提供了同步复制和自动失败恢复。在采用 MySQL 的 master-slave 复制方法时,很难进行失败恢复,会有数据丢失和当机的风险。再次,F1 需要强壮的事务语义,这使得使用 其他 NoSQL 系统是不实际的。应用语义需要跨越任意数据的事务和一致性读。F1 团队也需要在他们的数据上构建二级索引(因为 Spanner 没有提供对二级索引的自动支持),也有能力使用 Spanner 事务来实现他们自己的一致性全球索引。
所有应用写操作,现在都是默认从 F1 发送到 Spanner。而不是发送到基于 MySQL 的应 用栈。F1 在美国的西岸有两个副本,在东岸有三个副本。这种副本位置的选择,是为了避免发生自然灾害时出现服务停止问题,也是出于前端应用的位置的考虑。实际上,Spanner 的失败自动恢复,几乎是不可见的。在过去的几个月中,尽管有不在计划内的机群失效,但是,F1 团队最需要做的工作仍然是更新他们的数据库模式,来告诉 Spanner 在哪里放置 Paxos 领导者,从而使得它们尽量靠近应用前端。
Spanner 时间戳语义,使得它对于 F1 而言,可以高效地维护从数据库状态计算得到的、放在内存中的数据结构。F1 会为所有变更都维护一个逻辑历史日志,它会作为每个事务的 一部分写入到 Spanner。F1 会得到某个时间戳下的数据的完整快照,来初始化它的数据结构, 然后根据数据的增量变化来更新这个数据结构。
表 5 显示了 F1 中每个目录的分片数量的分布情况。每个目录通常对应于 F1 上的应用栈中的一个用户。绝大多数目录(同时意味着绝大多数用户)都只会包含一个分片,这就意味着,对于这些用户数据的读和写操作只会发生在一个服务器上。多于 100 个分片的目录,是那些包含 F1 二级索引的表:对这些表的多个分片进行写操作,是极其不寻常的。F1 团队也只是在以事务的方式进行未经优化的批量数据加载时,才会碰到这种情形。
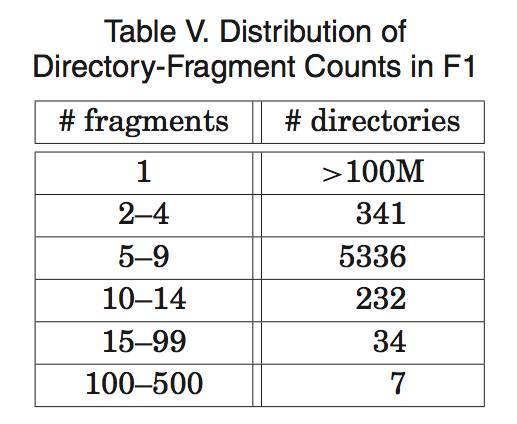
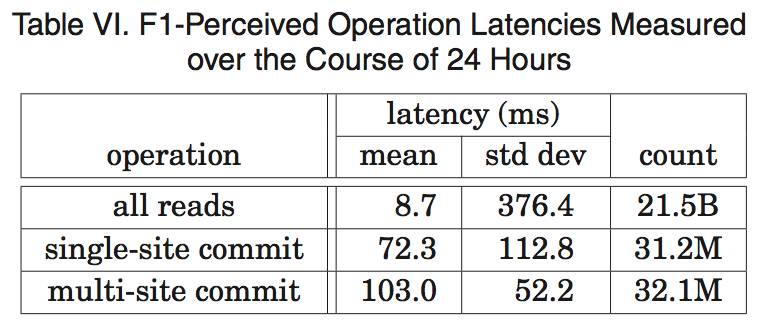
表 6 显示了从 F1 服务器来测量的 Spanner 操作的延迟。在东海岸数据中心的副本,在 选择 Paxos 领导者方面会获得更高的优先级。表 6 中的数据是从这些数据中心的 F1 服务器 上测量得到的。写操作延迟分布上存在较大的标准差,是由于锁冲突引起的肥尾效应(fat tail)。在读操作延迟分布上存在更大的标准差,部分是因为 Paxos 领导者跨越了两个数据中心,只有其中的一个是采用了固态盘的机器。此外,测试内容还包括系统中的每个针对两个 数据中心的读操作:字节读操作的平均值和标准差分别是 1.6KB 和 119KB。
6. 相关工作
Megastore[5]和 DynamoDB[3]已经提供了跨越多个数据中心的一致性复制。DynamoDB 提供了键值存储接口,只能在一个 region 内部进行复制。Spanner 和 Megastore 一样,都提供了半关系数据模型,甚至采用了类似的模式语言。Megastore 无法活动高性能。Megastore 是架构在 Bigtable 之上,这带来了很高的通讯代价。Megastore 也不支持长寿命的领导者, 多个副本可能会发起写操作。来自不同副本的写操作,在 Paxos 协议下一定会发生冲突,即使他们不会发生逻辑冲突:会严重影响吞吐量,在一个 Paxos 组内每秒钟只能执行几个写操作。Spanner 提供了更高的性能,通用的事务和外部一致性。
Pavlo 等人[31]对数据库和 MapReduce[12]的性能进行了比较。他们指出了几个努力的方向,可以在分布式键值存储之上充分利用数据库的功能[1][4][7][41],二者可以实现充分的融合。我们比较zan同这个结论,并且认为集成多个层是具有优势的:把复制和并发控制集成起来,可以减少 Spanner 中的提交等待代价。
在一个采用了复制的存储上面实现事务,可以至少追述到 Gifford 的论文[16]。Scatter[17] 是一个最近的基于 DHT 的键值存储,可以在一致性复制上面实现事务。Spanner 则要比 Scatter 在更高的层次上提供接口。Gray 和 Lamport[18]描述了一个基于 Paxos 的非阻塞的提交协议,他们的协议会比两阶段提交协议带来更多的代价,而两阶段提交协议在大范围分布 式的组中的代价会进一步恶化。Walter[36]提供了一个快照隔离的变种,但是无法跨越数据中心。相反,我们的只读事务提供了一个更加自然的语义,因为我们对于所有的操作都支持外部语义。
最近,在减少或者消除锁开销方面已经有大量的研究工作。Calvin[40]消除了并发控制: 它会重新分配时间戳,然后以时间戳的顺序执行事务。HStore[39]和 Granola[11]都支持自己的事务类型划分方法,有些事务类型可以避免锁机制。但是,这些系统都无法提供外部一致性。Spanner 通过提供快照隔离,解决了冲突问题。
VoltDB[42]是一个分片的内存数据库,可以支持在大范围区域内进行主从复制,支持灾难恢复,但是没有提供通用的复制配置方法。它是一个被称为 NewSQL 的实例,这是实现 可扩展的 SQL[38]的强大的市场推动力。许多商业化的数据库都可以支持历史数据读取,比如 Marklogic[26]和 Oracle’ Total Recall[30]。Lomet 和 Li[24]对于这种时间数据库描述了一种 实现策略。
Faresite 给出了与一个受信任的时钟参考值相关的时钟不确定性的边界13:Farsite 中的服务器租约的方式,和 Spanner 中维护 Paxos 租约的方式 相同。在之前的工作中[2][23],宽松同步时钟已经被用来进行并发控制。我们已经展示了 TrueTime 可以从 Paxos 状态机集合中推导出全球时间。
7. 未来的工作
在过去一年的大部分时间里,我们都是 F1 团队一起工作,把谷歌的广告后台从 MySQL 迁移到 Spanner。我们正在积极改进它的监控和支撑工具,同时在优化性能。此外,我们已经开展了大量工作来改进备份恢复系统的功能和性能。我们当前正在实现 Spanner 模式语言,自动维护二级索引和自动基于负载的分区。在未来,我们会调研更多的特性。以最优化的方式并行执行读操作,是我们追求的有价值的策略,但是,初级阶段的实验表明,实现这个目标比较艰难。此外,我们计划最终可以支持直接变更 Paxos 配置[22]34]。
我们希望许多应用都可以跨越数据中心进行复制,并且这些数据中心彼此靠近。 TrueTime ε 可能会明显影响性能。把 ε 值降低到 1ms 以内,并不存在不可克服的障碍。 Time-master-query 间隔可以继续减少,Time-master-query 延迟应该随着网络的改进而减少, 或者通过采用分时技术来避免延迟。
最后,还有许多有待改进的方面。尽管 Spanner 在节点数量上是可扩展的,但是与节点相关的数据结构在复杂的 SQL 查询上的性能相对较差,因为,它们是被设计成服务于简单的键值访问的。来自数据库文献的算法和数据结构,可以极大改进单个节点的性能。另外,根据客户端负载的变化,在数据中心之间自动转移数据,已经成为我们的一个目标,但是,为了有效实现这个目标,我们必须具备在数据中心之间自动、协调地转移客户端应用进程的能力。转移进程会带来更加困难的问题——如何在数据中心之间管理和分配资源。
8. 总结
总的来说,Spanner 对来自两个研究群体的概念进行了结合和扩充:一个是数据库研究群体,包括熟悉易用的半关系接口,事务和基于 SQL 的查询语言;另一个是系统研究群体,包括可扩展性,自动分区,容错,一致性复制,外部一致性和大范围分布。自从 Spanner 概念成形,我们花费了 5 年以上的时间来完成当前版本的设计和实现。花费这么长的时间,一部分原因在于我们慢慢意识到,Spanner 不应该仅仅解决全球复制的命名空间问题,而且也应该关注 Bigtable 中所丢失的数据库特性。
我们的设计中一个亮点特性就是 TrueTime。我们已经表明,在时间 API 中明确给出时钟不确定性,可以以更加强壮的时间语义来构建分布式系统。此外,因为底层的系统在时钟不确定性上采用更加严格的边界,实现更强壮的时间语义的代价就会减少。作为一个研究群体,我们在设计分布式算法时,不再依赖于弱同步的时钟和较弱的时间 API。
致谢
许多人帮助改进了这篇论文:Jon Howell,Atul Adya, Fay Chang, Frank Dabek, Sean Dorward, Bob Gruber, David Held, Nick Kline, Alex Thomson, and Joel Wein. 我们的管理层对于我们的工作和论文发表都非常支持:Aristotle Balogh, Bill Coughran, Urs H ̈olzle, Doron Meyer, Cos Nicolaou, Kathy Polizzi, Sridhar Ramaswany, and Shivakumar Venkataraman.
我们的工作是在Bigtable和Megastore团队的工作基础之上开展的。F1团队,尤其是Jeff Shute ,和我们一起工作,开发了数据模型,跟踪性能和纠正漏洞。Platforms团队,尤其是Luiz Barroso 和Bob Felderman,帮助我们一起实现了TrueTime。最后,许多谷歌员工都曾经在我们的团队工作过,包括Ken Ashcraft, Paul Cychosz, Krzysztof Ostrowski, Amir Voskoboynik, Matthew Weaver, Theo Vassilakis, and Eric Veach; or have joined our team recently: Nathan Bales, Adam Beberg, Vadim Borisov, Ken Chen, Brian Cooper, Cian Cullinan, Robert-Jan Huijsman, Milind Joshi, Andrey Khorlin, Dawid Kuroczko, Laramie Leavitt, Eric Li, Mike Mammarella, Sunil Mushran, Simon Nielsen, Ovidiu Platon, Ananth Shrinivas, Vadim Suvorov, and Marcel van der Holst.
参考文献非常多,这里不再列出,请参见英文原文。
觉得本文有帮助?请分享给更多人
关注「数据库开发」,提升数据库开发
技术






