深度学习方法因其在建模现实问题上极强的灵活性,近年来被许多专家、学者应用于无人车决策系统。
NVIDIA 研发的无人驾驶车辆系统架构是一种典型架构,其采用端到端卷积神经网络进行决策处理,使决策系统大幅简化。系统直接输入由相机获得的各帧图像,经由神经网络决策后直接输出车辆目标转向盘转角。
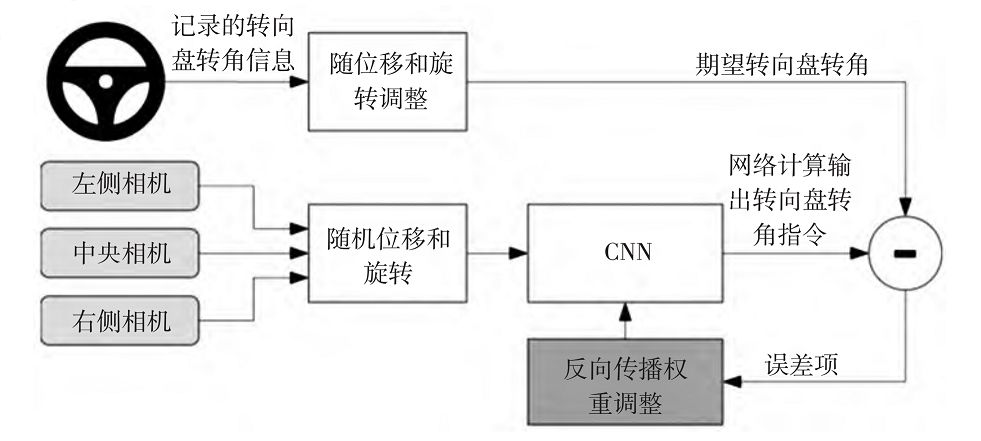
图 9 NVIDIA 无人车决策系统训练模型
该系统使用 NVIDIA DevBox 作处理器,用 Torch 7 作为系统框架进行训练,工作时每秒处理 30帧数据,其训练系统框架如图 9所示。
图像输入到卷积神经网络
(Convolutional Neural Networks,CNN)
计算转向控制命令,将预测的转向控制命令与理想的控制命令相比较,然后调整 CNN 模型的权值使得预测值尽可能接近理想值。
权值调整由机器学习库 Torch 7 的反向传播算法完成。
训练完成后,模型可以利用中心的单个摄像机数据生成转向控制命令。
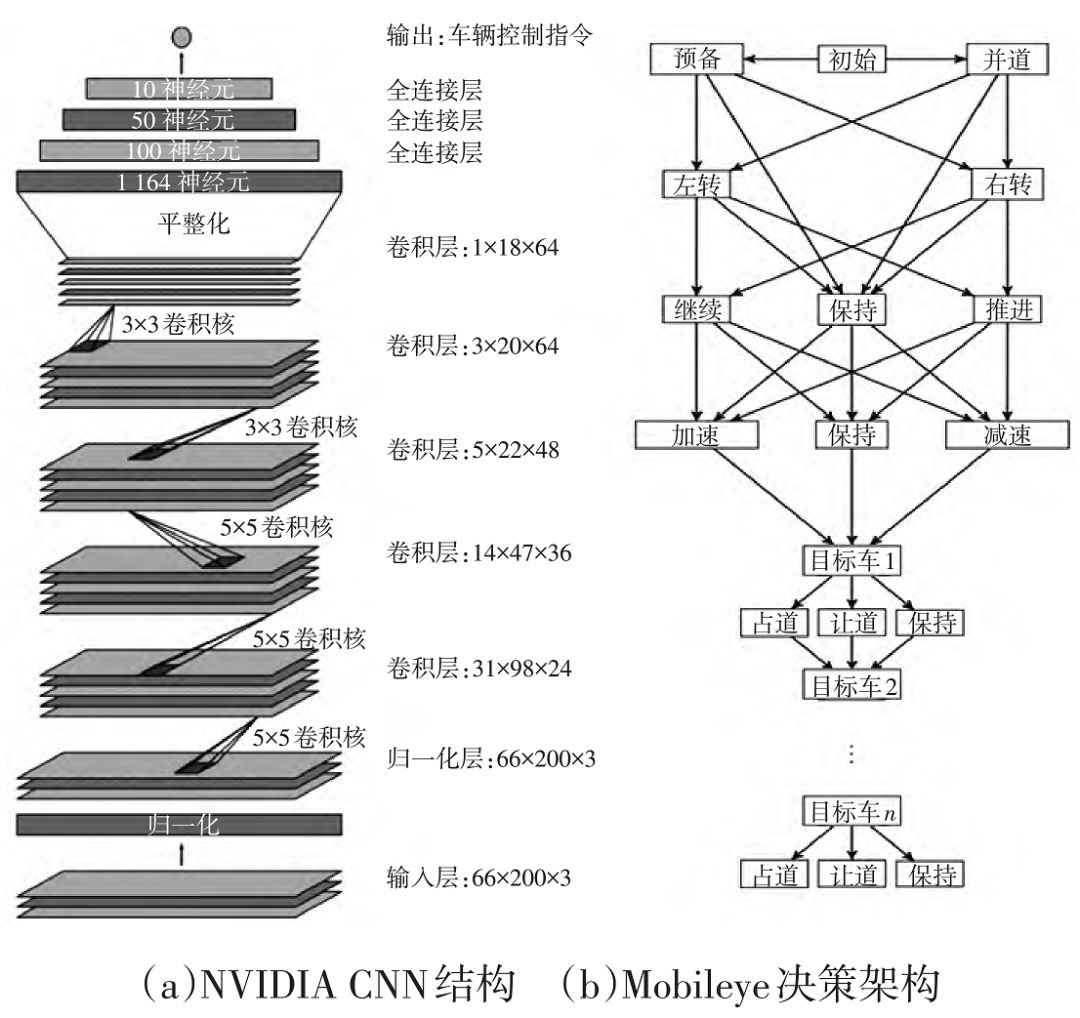
图 10 NVIDIA 与 Mobileye 决策架构
其深度学习系统网络结构如图 10a 所示,共 9层,包括 1 个归一化层、5 个卷积层和 3 个全连接层。输入图像被映射到 YUV 颜色空间,然后传入网络。
仿真结果表明,其神经网络能完整地学习保持车道驾驶的任务,而不需要人工将任务分解为车道检测、语义识别、路径规划和车辆控制等。
CNN 模型可以从稀疏的训练信号(只有转向控制命令)中学到有意义的道路特征,100 h 以内的少量训练数据就足以完成在各种条件下操控车辆的训练。
百度端到端系统实现了对车辆的纵向和横向控制:
模型主要关注视觉特征的提取、时序规律的发现、行为的映射等方面。
其中,纵向控制被看作时空序列预测问题,输入单元为最近 5 帧图像(图像采集频率是每秒 8帧),每帧图像均缩放为 80 像素 × 80 像素的 RGB 格式。LSTM 模型的第 1 层有 64 个通道,其内核大小为 5 像素 × 5像素,后续层拥有更多的通道和更小的内核,最后一个卷积层为 2 个完全连通的层。输出单元是线性单元,损失函数是 MSE,优化器是 rmsprop。横向控制由 1 个预处理层、5 个卷积层和 2 个全连接层组成。输入为 320 像素 × 320 像素的 RGB格式图像。
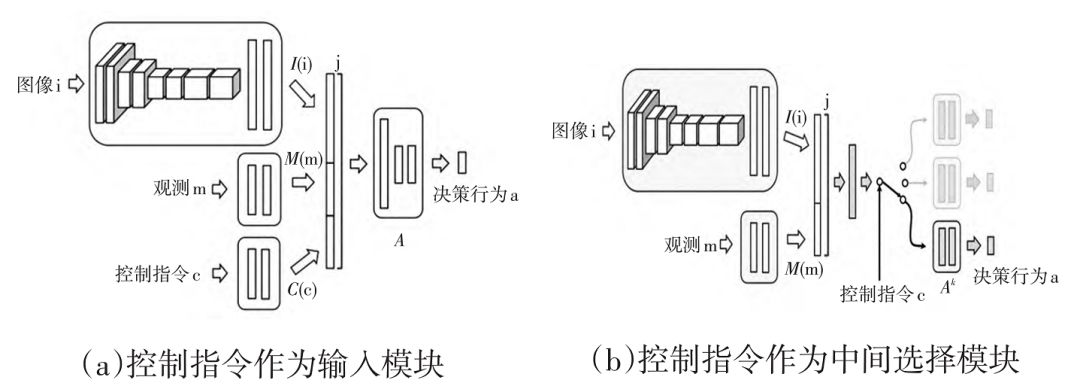
图 11 Intel 决策网络架构
Intel [20] 利用已有控制数据训练网络,完成端到端的自动驾驶,如图 11 所示。其在网络中考虑了方向性的控制指令(直行、左转、右转),使得网络可以在车道保持的同时完成转弯等操作。图 11 为 2 种不同的结合控制指令的结构:一种作为网络的输入,另一种将指令分为 3 个不同的输出层,根据控制指令选择不同的输出。
Comma.ai [21] 利用 CNN,并且几乎只用 CNN来构造决策系统。该系统将图像导入网络,通过网络输出命令调整转向盘和车速,从而使车辆保持在车道内。根据 Comma.ai 公布的数据,该公司目前已经累计行驶约1.35×10^6 km,累计行驶时间为 22000 h,累计用户 1909 人。
美国伍斯特理工学院 [36] 提出了一种自动驾驶汽车的端到端学习方法,能够直接从前视摄像机拍摄的图像帧中产生适当的转向盘转角
。主要使用卷积神经网络将特征级的图像数据作为输入,驾驶员的转向盘转角作为输出进行训练和学习,使用 Comma.ai 公布的数据集进行训练和评估。试验结果表明,该模型能够实现相对精确的转向控制,很好地完成了车道保持动作。
Mobileye [22] 把
增强学习
应用在高级驾驶策略的学习上,感知及控制等模块则被独立出来处理,其系统结构如图 10b 所示。
相对于端到端学习大大提高了决策过程的可解释性和可操作性,很好地适配了传统机器人学中感知-决策-控制的系统架构
。
Drive.ai 获准在美国加州公共道路上测试无人驾驶汽车,其在感知和决策上都使用深度学习,但避免整体系统的端到端,而是将系统按模块分解,再分别应用深度学习,同时结合规则、知识确保系统的安全性。
Waymo 通过模拟驾驶及道路测试获取了大量的数据对其行为决策系统进行训练
。该系统不仅能对物体进行探测,还能对障碍物进行语义理解。对不同道路参与者的行为方式建立准确的模型,判断它可能的行为方式以及对汽车自身的道路行为产生的影响,输入到决策系统,保证决策行为的安全性。
卡耐基梅隆大学 [37] 提出了一种基于预测和代价函数算法(Prediction and Cost function-Based algorithm,PCB)的离线学习机制,用于模拟人类驾驶员的行为决策。其决策系统针对交通场景预测与评估问题建立模型,使用学习算法,利用有限的训练数据进行优化。训练数据来源于人类驾驶员在实际道路的跟车场景,主要包含自车车速、前车车速以及两车之间的距离等。在 120 km 的低速跟车测试中,PCB 和人类跟车的车速差异仅为 5%,能够很好地完成跟车操作。
国防科技大学的刘春明教授等人 [38] 构建了 14 自由度的车辆模型,采用模型控制预测理论,利用基于增强学习理论的方法,基于仿真数据得到了无人车的决策模型。该方法利用多自由度车辆模型对车辆的实际动力学特性进行考量,有利于满足车辆行驶稳定与乘员舒适的要求。
麻省理工大学 [39] 在仿真器中模拟单向 7 车道工况,利用定义好的深度强化学习(Deep Q-Learning,DQN)模型调整网络结构,可在浏览器上进行训练工作,完善决策系统。










