我们一直在期待机器人能在我们的日常生活中发挥重要的作用,而作为机器人强国的日本也一直是这一领域的领导者之一。近日,日本大阪大学和日本科学枝术振兴机构(JST)ERATO ISHIGURO 共生人机交互项目(Symbiotic Human-Robot Interaction Project)的研究者在 arXiv 提交了一篇论文,介绍了他们在机器人的社会智能上的研究成果。另外值得一提的是,他们的实验用到了著名的 Pepper 机器人。

摘要
要让机器人与人类在类似我们社会那样的社会世界中共存,它们需要掌握类似人类的社交技能,这是很关键的。通过编程的方式来让机器人掌握这些技能是很艰难的。在这篇论文中,我们提出了一种多模态深度 Q 网络(MDQN:Multimodal Deep Q-Network),可以让机器人通过试错的方法来学习类似人类的交互技能。这篇论文的目标是开发能够在与人类的交互过程中收集数据并且能够使用端到端的强化学习从高维度传感信息中学习人类交互行为的机器人。本论文表明,机器人在经过了与人类的 14 天交互之后,可以成功学会基本的交互技能。

图 1:机器人向人学习社交技能
算法介绍
这里提出的算法由两个独立工作的流组成:一个用于处理灰度帧(grayscale frame),另一个用于处理深度帧(depth frame)。
下面的 Algorithm 1 概述了这个算法。因为该模型有两个流,因为其参数 θ 和 θ- 是由两个网络的参数构成的。和 DQN [10] 不同,我们将数据生成阶段和训练阶段分开了。每一天的实验都对应于一个 episode,在这期间,算法要么执行数据生成阶段,要么执行训练阶段。

本研究所提出的算法的伪代码
以下是这两个阶段的简述:
数据生成阶段(data generation phase):在数据生成阶段,系统使用 Q 网络 Q(s, a; θ) 来与其环境进行交互。该系统会观察当前场景(由灰度帧和深度帧构成),并使用 ε-greedy 策略来采取行动。该环境又会反过来提供标量的奖励(reward)(请参阅 5(2) 节了解奖励函数的定义)。交互经历是

其被存储在重放记忆 M 中。重放记忆 M 会保存 N 个最近的经历,然后这些经历会在训练阶段被用于更新该网络的参数。
训练阶段(training phase):在训练阶段,该系统会利用存储在重放记忆 M 中的数据来对网络进行训练。超参数 n 表示经历重放的数量。对于每一次经历重放,都会从有限大小的重放记忆 M 中随机采样出一个包含 2000 次交互经历的迷你缓存器 B。该模型会在从缓存器 B 中采样出的 mini batch 上进行训练,该网络的参数会在 bellman targets 的方向上迭代式地更新。这个对重放记忆的随机采样会打破样本之间的相关性,因为标准的强化学习方法假定样本是独立的且完全分布式的。将该算法分成两个阶段的原因是为了避免延迟——如果该网络在交互期间同时进行训练就会产生这种延迟。该 DQN [16] 代理在一个循环中工作,其中它首先会与环境进行交互,然后会将这个转变存储到重放记忆中,然后其会从该重放记忆中采样出 mini batch,并在这个 mini batch 上训练该网络。这个循环会不断重复,直到终止。这个交互和训练的顺序过程在 HRI 之外的领域也许是可以接受的。在 HRI 领域,代理必须基于社会规范来和人类进行交互,因此机器人的任何停顿和延迟都是不可接受的。因此,我们将该算法分成了两个阶段:在第一个阶段,机器人通过与人类进行有限时间的交互来收集数据;在第二个阶段,其进入阶段。在这个休息阶段,训练阶段激活从而对该多模态深度 Q 网路(MDQN)进行训练。
实现细节
这个模型由两个流(stream)构成,一个用于灰度信息,另一个用于深度信息。这两个流的结构是完全相同的,每个流都由 8 个层组成(包括输入层)。整体模型架构如图 2 所示。
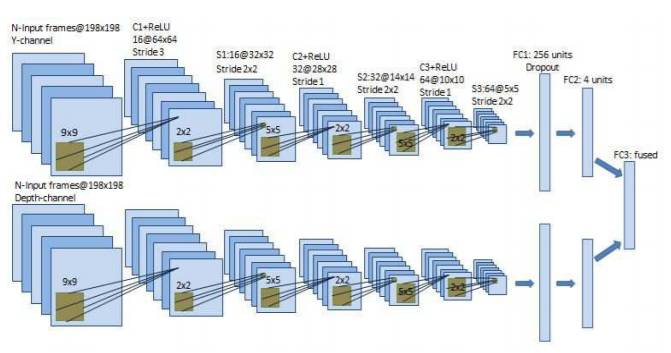
图 2:双流式卷积神经网络
该多模态 Q 网络的 y 信道和 depth 信道的输入分别是灰度图像(198 × 198 × 8)和深度图像(198 × 198 × 8)。因为每个流都使用 8 帧输入,因此,来自对应相机的最新的 8 帧是被预处理后堆叠到一起,构成该网络的每个流的输入。因为这两个流是完全一样的,所以我们在这里只讨论一个流的结构即可。198 × 198 × 8 的输入图像首先被传递给第一个卷积层(C1),其以 3 的步幅卷积计算 9×9 的 16 个滤波器,后面则跟着一个整流线性单元(ReLU)函数并得到每个大小为 64×64 的 16 个特征图(我们将其记为 16@64×64)。这个来自 C1 的输出然后会被送入下采样层 S1,其以 2×2 的步幅应用 2×2 的最大池化(max-pooling)。第二(C2)和第三(C3)个卷积层分别卷积计算 32 和 64 个滤波器,其大小为 5×5,使用了 1 的步幅。C2 和 C3 的输出通过非线性 ReLU 函数,然后分别被送入下采样层 S2 和 S3。最后的隐藏层是带有 256 个整流单元的全连接层。输出层则是一个全连接的线性层,带有 4 个单元,每一个单元对应一个合法动作。

图 3:成功和不成功的握手示例

图 4:在经过了一系列的 episode 之后,MDQN 在测试数据集上的表现
论文链接:https://arxiv.org/abs/1702.07492
©本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]









