云豆
贴心提醒,本文阅读时间6分钟
这篇文章直接给出上次关于Kmeans聚类的篮球远动员数据分析案例,最后介绍Matplotlib包绘图的优化知识。
希望这篇文章对你有所帮助,尤其是刚刚接触数据挖掘以及大数据的同学,同时准备尝试以案例为主的方式进行讲解。如果文章中存在不足或错误的地方,还请海涵~
一、案例实现
这里不再赘述,详见第二篇文章,直接上代码。
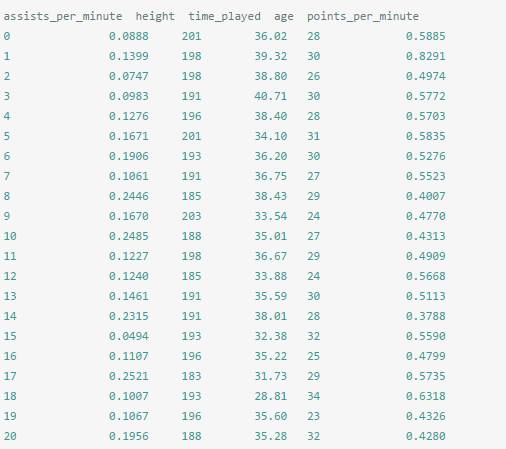
篮球运动员数据,每分钟助攻和每分钟得分数。通过该数据集判断一个篮球运动员属于什么位置(控位、分位、中锋等)。完整数据集包括5个特征,每分钟助攻数、运动员身高、运动员出场时间、运动员年龄和每分钟得分数。
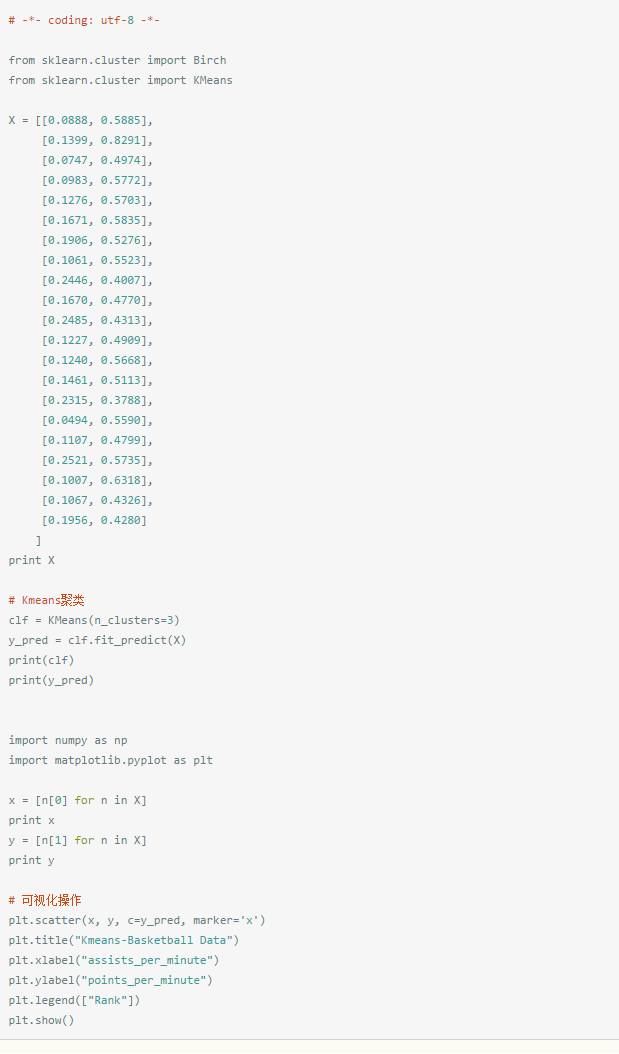
完整代码:
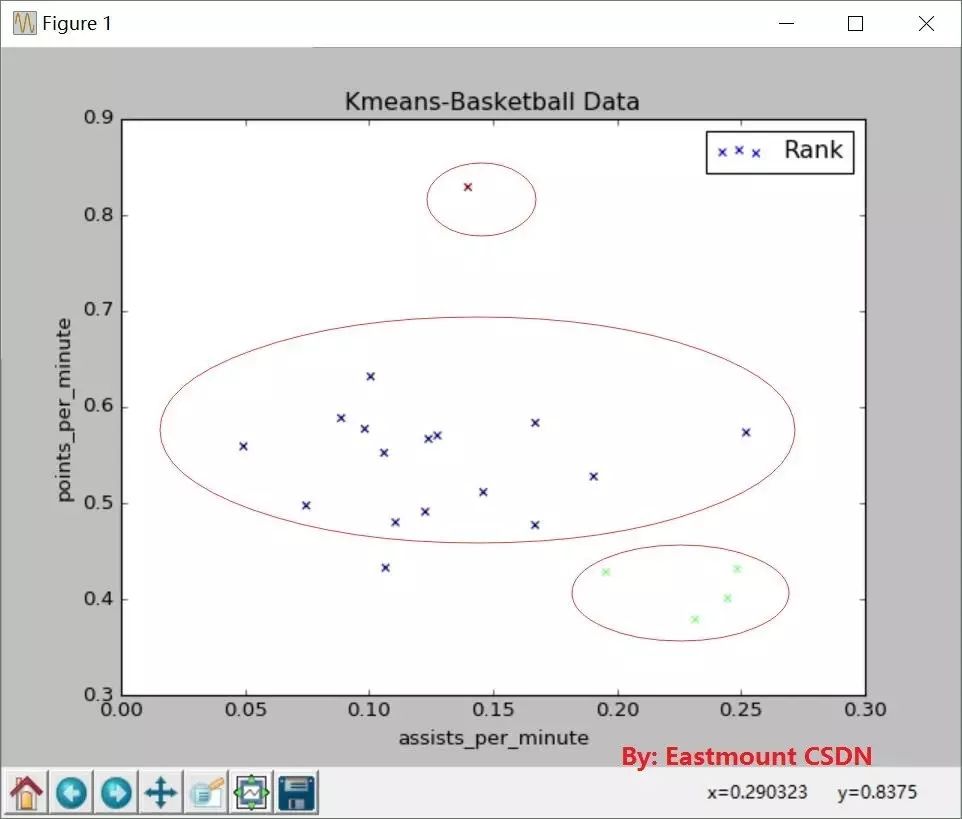
运行结果:
从图中可以看到聚集成三类,红色比较厉害,得分很高;中间蓝色是一类,普通球员;右小角绿色是一类,助攻高得分低,是控位。
代码分析:

表示在sklearn中处理kmeans聚类问题,用到 sklearn.cluster.KMeans 这个类。

X是数据集,包括2列20行,即20个球员的助攻数和得分数。

表示输出完整Kmeans函数,包括很多省略参数,将数据集分成类簇数为3的聚类。

输出聚类预测结果,对X聚类,20行数据,每个y_pred对应X的一行或一个孩子,聚成3类,类标为0、1、2。

输出结果:[0 2 0 0 0 0 0 0 1 0 1 0 0 0 1 0 0 0 0 0 1]

matplotlib.pyplot是用来画图的方法,matplotlib是可视化包。

获取第1列的值, 使用for循环获取 ,n[0]表示X第一列。
获取第2列的值,使用for循环获取 ,n[1]表示X第2列。

绘制散点图(scatter),横轴为x,获取的第1列数据;纵轴为y,获取的第2列数据;c=y_pred对聚类的预测结果画出散点图,marker='o'说明用点表示图形。

表示图形的标题为Kmeans-heightweight Data。

表示图形x轴的标题。

表示图形y轴的标题。

设置右上角图例。

表示显示图形。
二、Matplotlib绘图优化
Matplotlib代码的优化:
1.第一部分代码是定义X数组,实际中是读取文件进行的,如何实现读取文件中数据再转换为矩阵进行聚类呢?
2.第二部分是绘制图形,希望绘制不同的颜色及类型,使用legend()绘制图标。
假设存在数据集如下图所示:data.txt
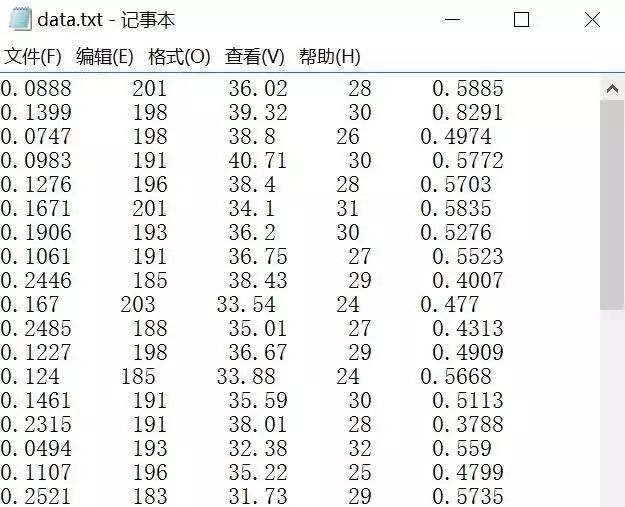
数据集包括96个运动员的数据。
现需要获取第一列每分钟助攻数、第五列每分钟得分数存于矩阵中。
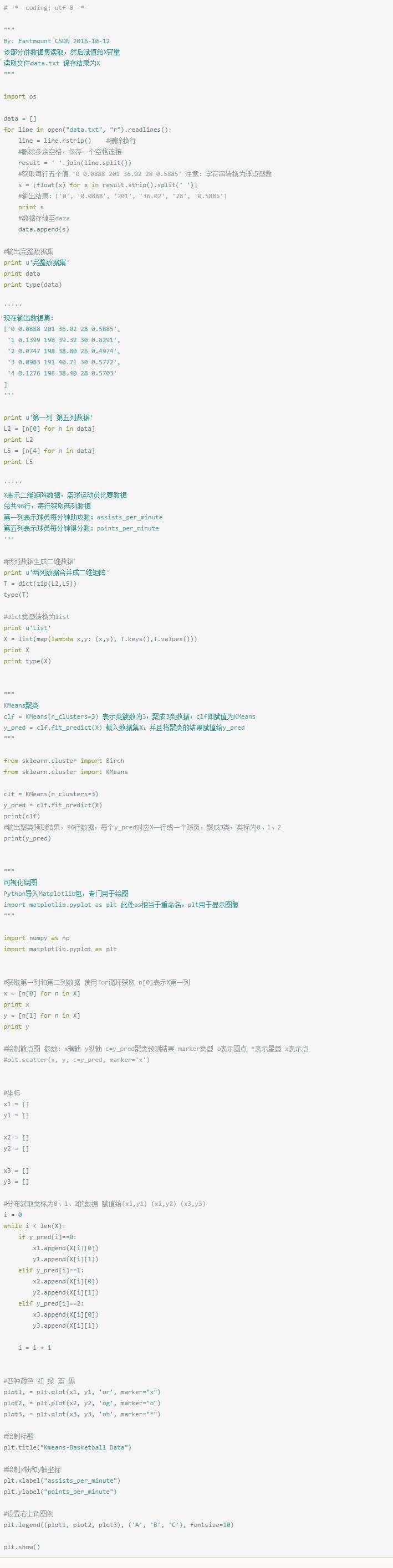
代码如下:
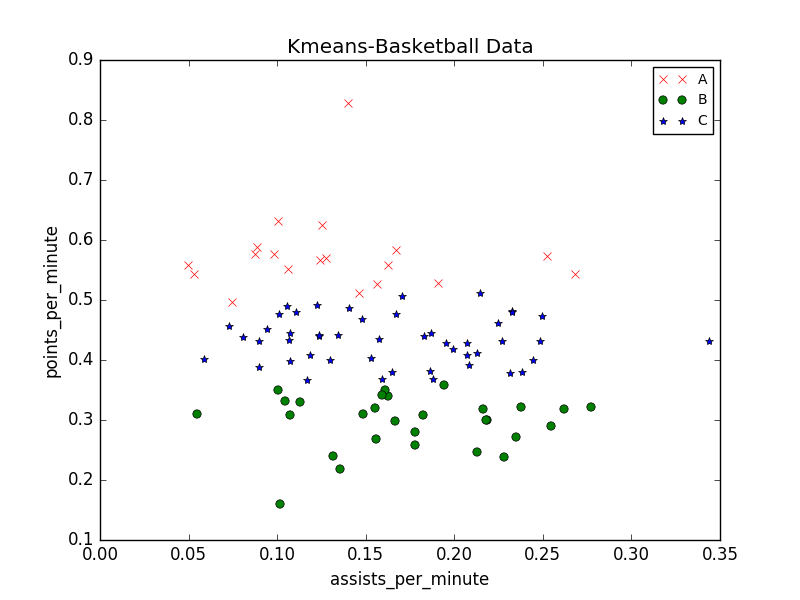
输出结果如下图所示:三个层次很明显,而且右上角也标注。
三、 Spyder常见问题
下面是常见遇到的几个问题:
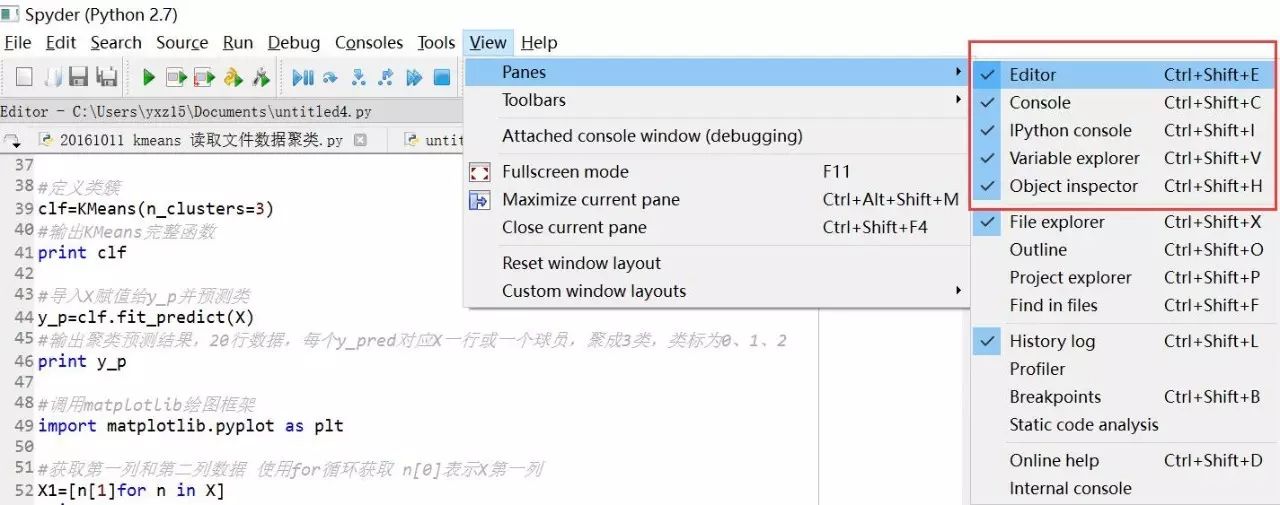
1.Spyder软件如果Editor编辑框不在,如何调出来。
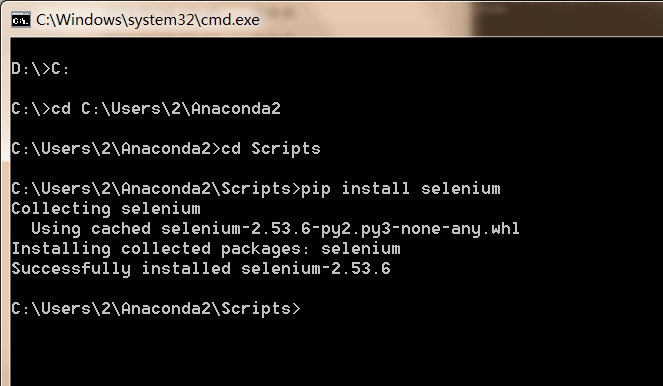
2.会缺少一些第三方包,如lda,如何导入。使用cd ..去到C盘根目录,cd去到Anaconda的Scripts目录下,输入"pip install selenium"安装selenium相应的包,"pip install lda"安装lda包。
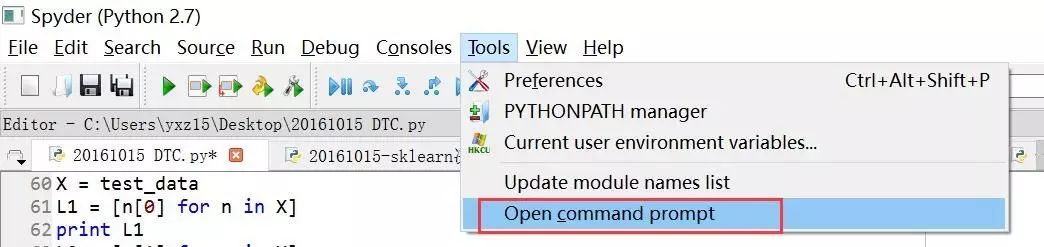
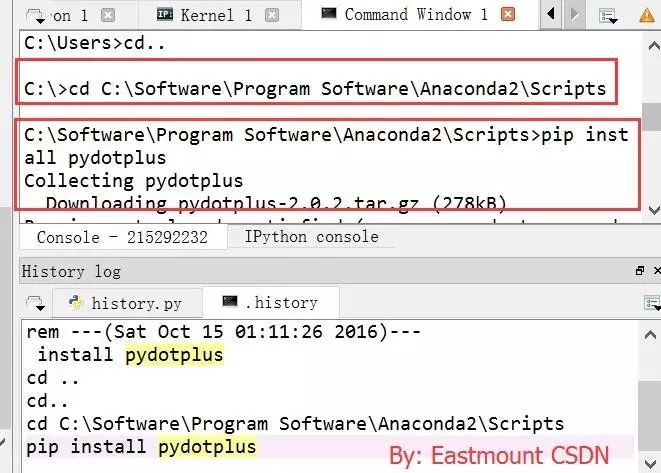
另一个更方便的方法:
3.运行时报错,缺少Console,点击如下。
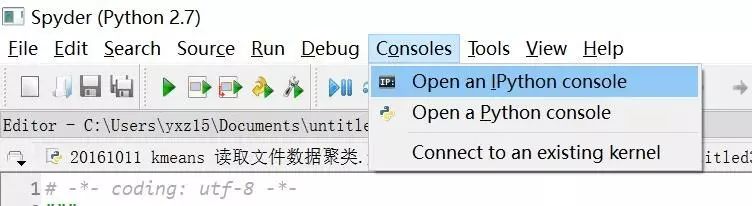
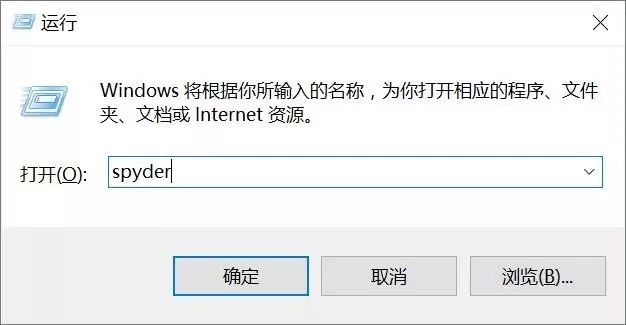
4.如果Spyder安装点击没有反应,重新安装也没有反应,建议在运行下试试。
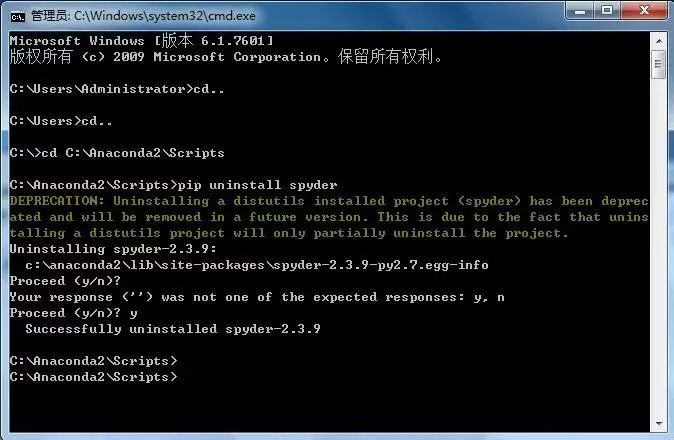
实在不行卸载再重装:pip uninstall spyder
pip install spyder
5.Spyder如何显示绘制Matplotlib中文。