本文目录
15 DeFINE:深度矩阵分解给词向量矩阵瘦身 (ICLR 2020)
(来自华盛顿大学)
15.1 DeFINE原理分析
16 DeLighT: Deep and Light-Weight Transformer (ICLR 2021)
(来自Facebook AI)
16.1 DELIGHT原理分析
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
但对于长序列来说,训练和部署这些模型的成本非常高,也就产生了设计轻量化Transformer的需求。
本文讲解2种Transformer模型:DeFINE,DeLighT,它们分别代表2种轻量化Transformer的方式,即:
- DeFINE:One-hot vector → word embedding 的过程轻量化。
- DeLighT:Transformer Block内部轻量化。
这2个模型提供了2种压缩Transformer模型的维度。
15 DeFINE: 深度矩阵分解给词向量矩阵瘦身 (ICLR 2020)
论文名称:DeFINE: Deep Factorized Input Word Embeddings for Neural Sequence Modeling
论文地址:
https://openreview.net/pdf?id=rJeXS04FPH
本文的背景是NLP任务,比如语言建模和机器翻译。深度学习模型的架构总是类似的,如下图1所示。词向量(tokens, 或words,或characters)表示成一个one-hot vector,被Embedding Layer建到连续空间中。紧接着被语言模型处理(图中是Transformer-XL),再map回一个vector (这个vector的维度与词向量的维度相等)以继续进行下面的任务。
在第1步和最后一步的mapping操作一般使用一个共享的可学习的lookup table,把每个token映射为一个 维的词向量,这个lookup table一般是通过embedding layer得到的,这一层的作用就是线性映射。但这样做的缺点是:当vocabulary的数量很大时, 就不能用的太大。
本文为了解决这个问题,提出了一种深度矩阵分解的办法 DeFINE 使embedding layer层的参数不需要太多就能得到具有相似效果的线性映射。DeFINE的思路是使得映射的维度 这个值减小以减小模型的计算复杂度,而实际效果甚至比标准的embedding layer还要好。
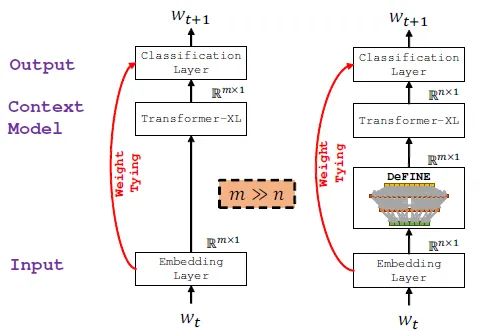
图1:左:没有DeFINE模型的Transformer-XL;有:有DeFINE模型的Transformer-XLDeFINE的具体做法如图1右图所示,它是一种深层、分层、稀疏的skip connection网络结构,目的是:减少参数量,加速训练,学习到更好的词向量。
词向量矩阵的作用是把一个one-hot的词向量映射到密集连续的空间 (dense continuous space)中,一般是个又宽又浅的网络。一共有个参数,当词表大小很大的时候,这巨大的参数量不但会降低计算效率,还会因为数据分布的不平衡性导致效果无法更上一层楼。我们想要给词向量矩阵瘦身。一个常见的做法是,使用简单的矩阵分解方法,即把词向量矩阵分解为两个矩阵的乘积,其中,这样,总的参数量就是,当很小的时候,参数量就会有很明显的减少。换句话说,就是先把词映射为一个低维向量,然后再映为一个高维向量。经过这样的操作,词向量矩阵从一个又宽又浅的网络变为了又窄又深的网络,能够在极大地节约参数的前提下保持相同的功能。DeFINE可以看成是针对上面 的一个改进,即:在 很小的情况下,用DeFINE模块来替代 ,在少参数的前提下得到相同功能的function。
下面图2是普通词向量和DeFINE在Transformer-XL上的参数量:
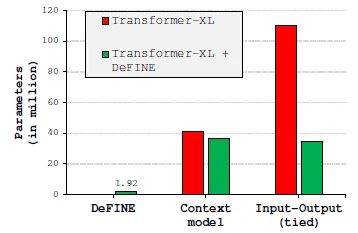
图2:普通词向量和DeFINE在Transformer-XL上的参数量DeFINE的具体做法是:
- 把 input token 按照 Map-Expand-Reduce (MER) 原理映射为低维度的embedding vector 。
- 将它通过 hierarchical group transformation (HGT) 这个操作变换到高维的向量空间 。
- 在以上过程中把input和output直接连接以实现特征重用。
Map-Expand-Reduce (MER)
顾名思义分成3步:Map,Expand,Reduce。
第1步 Map:词汇表V中的每个输入单词 都映射到固定维向量阵。 的值很小,例如64或128。这个值远小于传统的Transformer结构的400等等。
第2步 Expand:将 作为输入,并应用分层的组变换 (Hierarchical group transformation,HGT) 来生成非常高维的向量。其中 。与一堆完全连接的层不同,HGT使用稀疏和密集连接从输入的不同子集中有效地学习深度表示。
第3步 Reduce:将向量 投影到较低维度的空间,以生成给定输入词的最终嵌入向量。 的尺寸可以与上下文表示模型 (例如LSTM或Transformer) 匹配,从而允许DeFINE充当这些模型的输入层。
Hierarchical group transformation (HGT)
下面是矩阵分解的几种变体:
- LT(Linear Transform):使用多个FFN逐步将低维向量映为高维向量。每一层的计算复杂度是 ,所以总的计算复杂度是: 。
- GLT(Group Linear Transform):采用分组的策略将低维向量映为高维向量。每一层的计算复杂度是 ,所以总的计算复杂度是: 。
- HGT(Hierarchical Group Transform):采用先分组,再聚合的策略将低维向量映为高维向量。每一层的计算复杂度是 ,所以总的计算复杂度是: 。
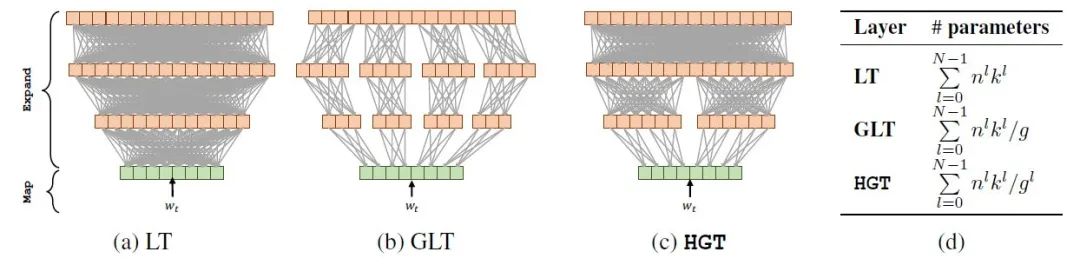 图3:矩阵分解的几种变体
图3:矩阵分解的几种变体接下来我们详细介绍HGT。HGT由 个layer构成,每一层都采取了分组操作,但是每一层分的组数是不同的。比如第 层有 个组(group),输入维度是,输出维度是。在第1层, HGT 有个组,之后组的个数按照指数2递减。而 LT 和 GLT 分别是 HGT 在 和 时的特殊情况。
问:为什么要采取这种组数依次递减的方法?
答: 目的是使得模型学习到representation之间的层级关系。如果只采用GLT,那么每个GLT层的输出都只与输入的一小部分有联系,所以只能学到weak representation;而HGT使得每一个layer的输出都能与所有的输入有联系,保证学到stronger representation,同时还能大量减少参数量。
DeFINE单元
DeFINE单元由使用 MER 原理设计的 HGT 组成。前面提到HGT是一种高效地替代FC层的办法,但是当堆叠次数 变得很大时也会阻碍训练。所以DeFINE单元也加入了skip-connection的连接。但是一个问题是由于HGT输入和输出的维度不同,没办法直接用skip-connection。
DeFINE单元的设计提供了一种思路:Split 是把上一层的输入和输出 (上一层的输出就是这一层的输入,也就是skip connection) 都分别分成这一层需要的组数 ,然后通过Mixer把各自的第 个组拼接起来,一共形成 个组,之后把这 个组继续往下送即可。使用这种方法,可以巧妙地结合skip connection,并且也不失分组的效率。
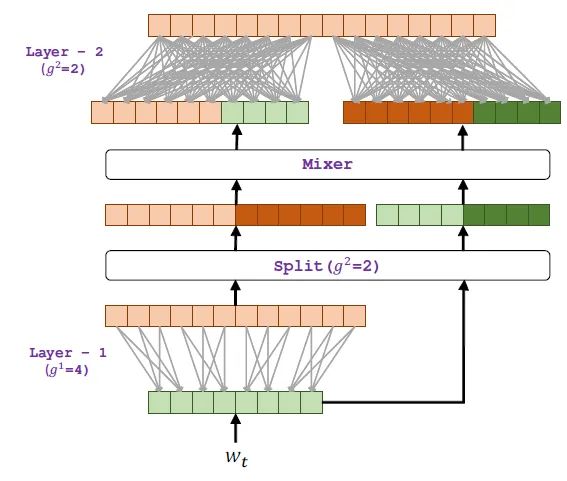
图4:DeFINE单元结构梳理一下,一开始我们想使用分组线性变换GLT来取代传统线性变换GT,以节约参数量。
但是 GLT存在不同组之间特征不共享的问题,所以我们又使用了HGT来共享不同组之间的特征以学习到更strong的特征表示。
但是 HGT又存在参数学习困难的问题,所以我们引入新的skip-connection操作得到 DeFINE单元 使得优化过程变得更加容易。
下图5为不同Block的堆叠方式,图4和图5(c)是等价的,都使用了Split and Mixer操作。图5(b)是直接使用残差连接堆叠Block的过程。图5(d)是不使用Split and Mixer操作,直接concat输入和每层输出的操作。
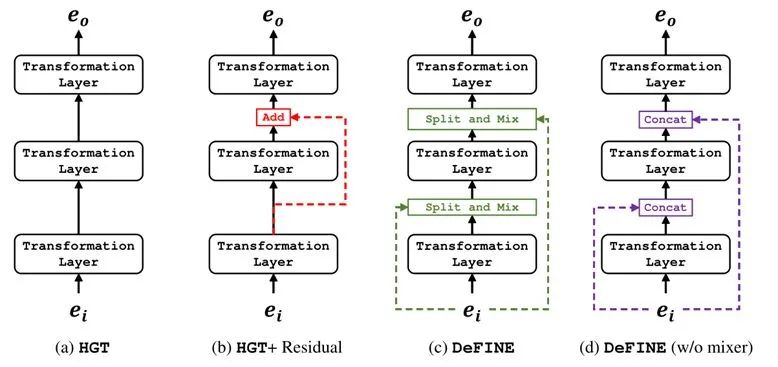 图5:不同Block的堆叠方式
图5:不同Block的堆叠方式Experiment:
实验1:language modeling
数据集: WikiText-103,Penn Treebank
模型: LSTM,Transformer-XL
下图6是使用基于LSTM的模型在LM上的实验结果。Adaptive方法对应到第2行,与DeFINE方法做个对比,DeFINE可以在只增加1.25%参数量的前提下提升大约3个点的性能。Adaptive 方法参数量最少,训练时间也最快,但是效果最差。而 Standard 方法参数量最多,但效果也不好。
当DeFINE的深度从3变化到11时,模型的性能提升了大约6个点。
下面的图b,c是和和AWD-LSTM与QRNN相比,DeFINE的参数量都有所减少,并且效果几乎没有明显下降。
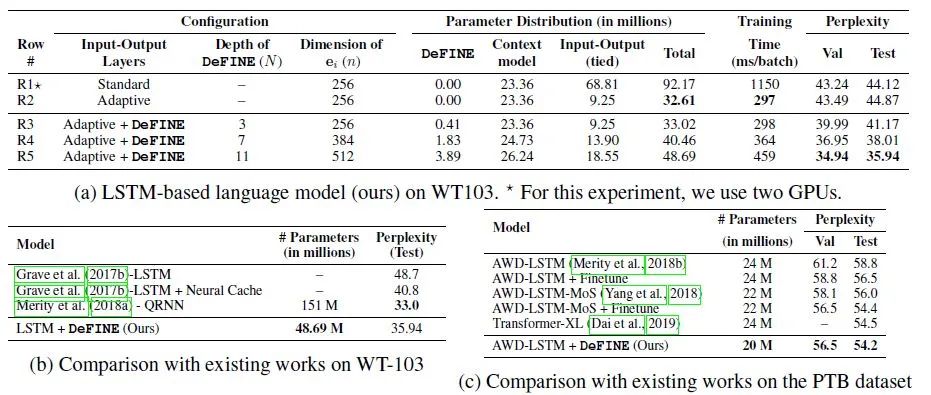 图6:使用基于LSTM的模型在LM上的实验结果
图6:使用基于LSTM的模型在LM上的实验结果下图7是使用基于Transformer的模型在LM上的实验结果。
实验设置为 ,Standard代表传统的线性变换,Projective代表渐进式把embedding的维度扩大为384。图a说明和原Transformer-XL相比,使用DeFINE可以在减少50%参数量的情况下使得PPL只减少2个点,而同等情况下不使用DeFINE会有5个点的下降,表明DeFINE对于学习word-level representations的高效性。
下图b进一步说明DeFINE和原版Transformer-XL在相似的性能下节约了大量的参数。
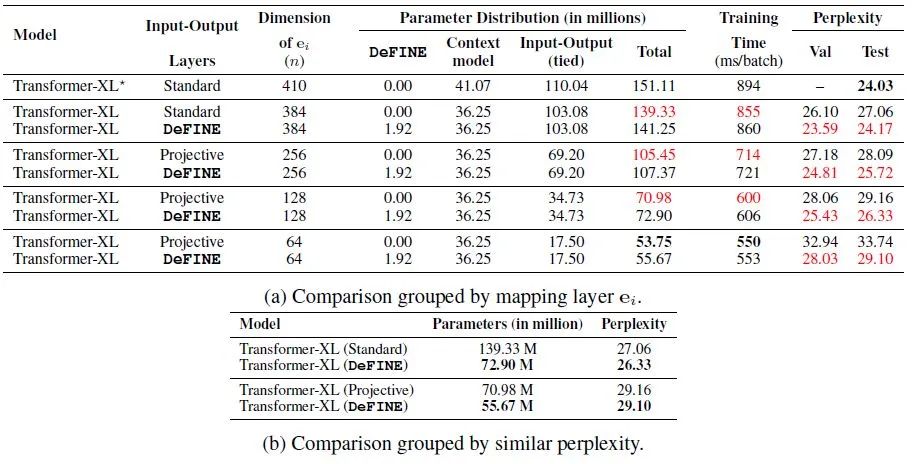 图7:使用基于Transformer的模型在LM上的实验结果
图7:使用基于Transformer的模型在LM上的实验结果实验2:NMT
数据集: Training:WMT 2014 English-German;Testing:newstest2014 and newstest2017
模型: Transformer
超参数设置: ,使用OpenNMT实现。
实验结果如图8所示,参数量减少26%而效果有2%的提高。
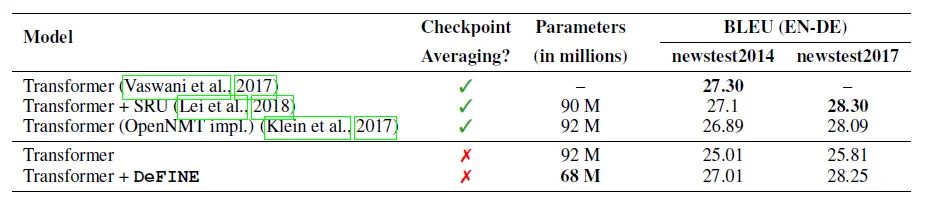
图8:Transformer-based model机器翻译任务实验结果实验3:不同任务不同矩阵分解方法的对比
下图9是不同任务不同矩阵分解方法的对比。DeFINE无论是从参数量和性能的角度来讲都是最优的选择,因为DeFINE的词嵌入结果更加接近标准embedding layer的词嵌入结果。
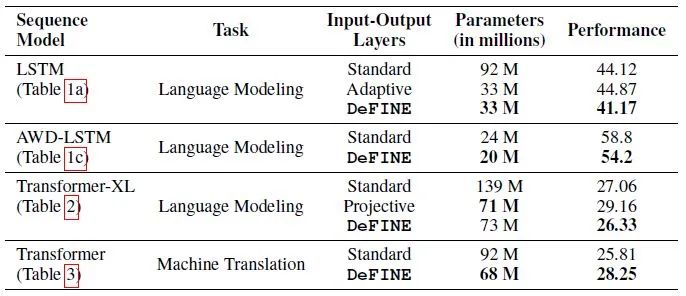 图9:不同任务不同矩阵分解方法的对比
图9:不同任务不同矩阵分解方法的对比对比实验1:不同变换策略的影响。
如下图10所示为不同变换策略的影响。HGT优于分组线性变换GLT。当我们把不同的组shuffle之后性能有所提升,但是依然不如HGT。同时DeFINE的性能优于HGT,提升了大约2.9个点却只带来了微小的参数量变化。

图10:不同变换策略的影响对比实验2:不同深度和宽度的影响
如下图11所示为不同深度和宽度的影响的实验结果,结果表明网络越深越好,但宽度似乎没有显著的影响。可能是因为随着k的大小的增加,更多的神经元接收到它们从相同的维度子集输入,从而多了许多冗余参数。
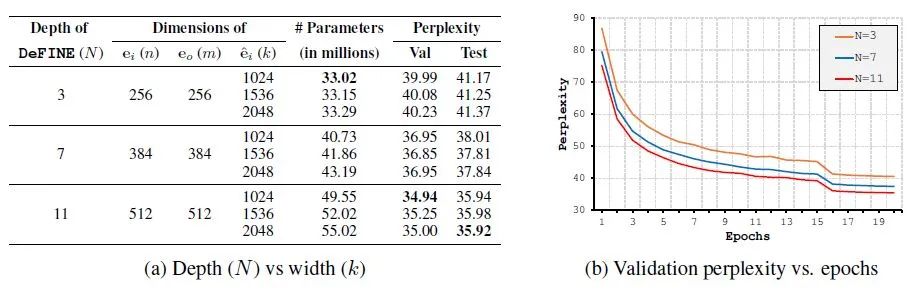 图11:不同深度和宽度的影响
图11:不同深度和宽度的影响对比实验3:连接方式的影响
作者也对比了普通的residual connection和DeFINE中的skip connection方法的不同,为了能够做成residual connection,作者把每个layer的维度都设置为固定的 ,而不是从 渐变到 ,结果表明DeFINE使用的方法更好。
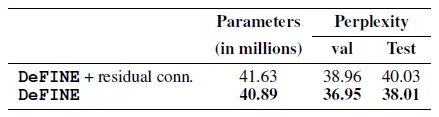
图12:连接方式的影响对比实验4:去掉低维映射的影响
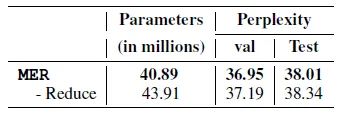
图13:去掉低维映射的影响图13为在把词向量送入到上下文建模模型 (如LSTM) 之前,是否去掉低维映射的影响 (称为reduce) 。结果显示,去掉reduce,参数量增加,但效果却没有变好,这也说明了单纯增加参数并不一定好。
为了进一步证明DeFINE的词嵌入矩阵与标准词嵌入矩阵的相似性,作者可视化了correlation map。这个correlation map的计算方法是:
假设现在标准的词嵌入矩阵这个look-up table: ,则correlation map为: 。
如果这个correlation map是个Identity矩阵,则说明这个词向量矩阵 的 个维度是没有任何联系的。那么为了得到更好的contextual representations,词向量矩阵的 个维度应该是没有任何联系的。所以可视化出来的correlation map应该是个Identity矩阵。
那么现在的问题是:DeFINE模型的correlation map也是个Identity矩阵吗?或者,它的correlation map与标准的correlation map差距有多大?
可视化结果如下图14所示。我们发现相比已有方法Projective Embedding来讲,DeFINE模型的correlation map与标准的correlation map更接近。换句话说,DeFINE模型的词嵌入矩阵Embedding layer与标准的Embedding layer更接近。
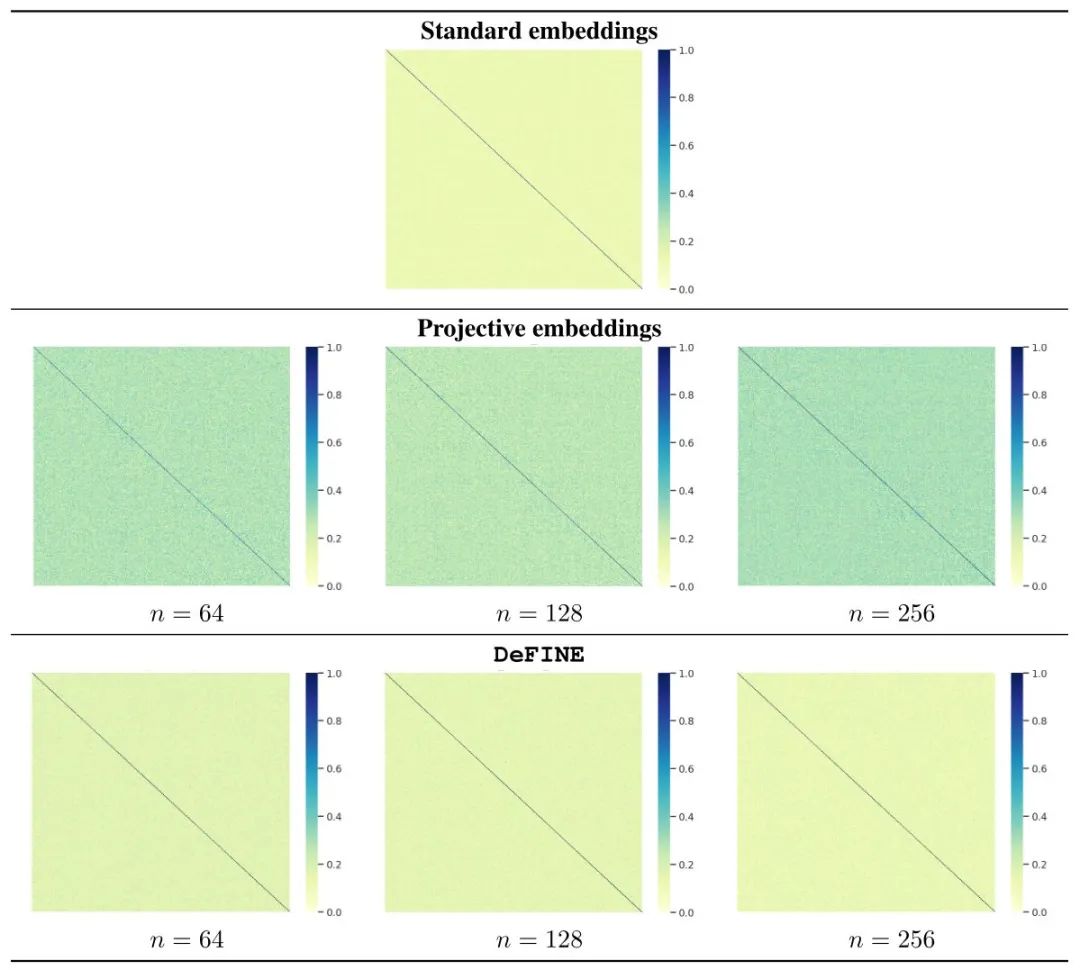 图14:DeFINE模型的correlation map和标准模型的correlation map的对比
图14:DeFINE模型的correlation map和标准模型的correlation map的对比下图15为n=256时的DeFINE模型的每一层的correlation map可视化结果。
我们发现随着网络的加深,词嵌入矩阵Embedding layer与标准的Embedding layer越来越接近,词向量矩阵的 个维度的相关性也越来越低了。
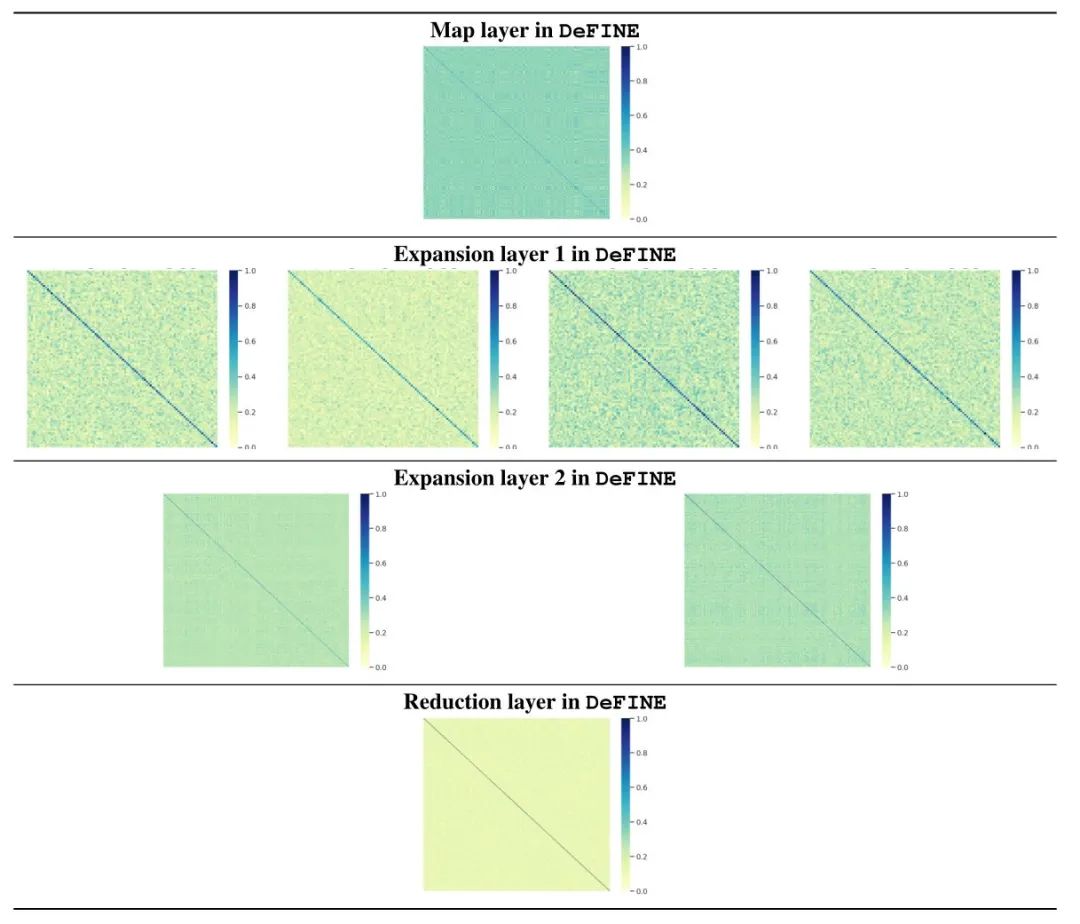 图15:n=256时的DeFINE模型的每一层的correlation map可视化结果
图15:n=256时的DeFINE模型的每一层的correlation map可视化结果小结:
DeFINE是一个高效地得到词向量的模块,它规避了传统的直接把token映射为 维词向量的过程,而是把token映射成一个 维向量 ( ),再通过DeFINE变为需要的 维词向量。在这个过程中节约了大量的参数,同时得到了相似的性能。
16 DELIGHT: Deep and Light-Weight Transformer
论文名称:DELIGHT: Deep and Light-Weight Transformer
论文地址:
https://arxiv.org/pdf/2008.00623.pdf
本文的背景是NLP任务,比如语言建模和机器翻译。为了提升性能,模型往往靠增加hidden dimension来增加宽度,比如一个叫T5的模型的hidden dimension竟然有65K之多,共有11 billion的参数;或者靠堆叠更多的transfomer block来增加深度,比如一个叫GPT-3的模型竟然能堆叠96个Transformer block,共有175billion的参数。这些模型因为参数量巨大,结构复杂导致非常难于训练。
我们发现模型变宽变深的代价是参数量巨大,而本文的目的是设计一种新型的parameter-efficient的attention结构,使得模型在参数量少的情况下也能做到又宽又深。
DELIGHT的结构与第1部分的DeFINE的结构很像,DeFINE使用expand-reduce strategy,先把input token 映射为维度为 的词向量,再通过DeFINE unit逐步映射为到高维的向量空间 (Expand),再投影到较低维度的空间 (Reduce)。
那么本文DELIGHT与DeFINE的区别在于:DeFINE是一个高效地得到词向量的模块,它的作用是高效地把one-hot的词变为 维度的word representation;而DELIGHT是Transformer block内部的模块,它的出现是为了使得Transformer的参数更加Efficient。二者结构上有很大的相似性,DELIGHT 使用了更多的group以节约参数,同时可以达到与DeFINE相当的效果。
传统Transformer block的结构如下图16所示,这里简要说明下几个变量的含义: 为每一层的输入和输出的hidden dimension,head数是 ,每一层的输入通过Linear Transformation分别变为 ,它们的hidden dimension为 。经过attention操作以后得到的 个输出维度也是 。把这 个输出concat起来之后经过fusion layer得到这一层attention最终的输出,维度是 。它进入MLP层,包含2个FFN,第1个FFN将维度扩大为 ,第1个FFN将维度缩小为 。
1个 Transformer block 的depth可以看做是4:
- 个输出concat起来之后经过fusion layer。
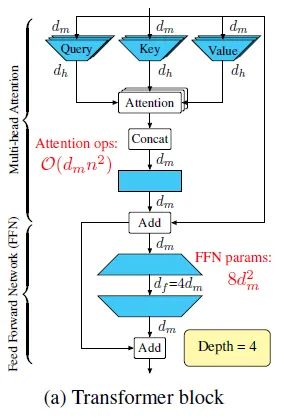
图16:传统Transformer的结构DELIGHT通过3个创新点达到节约参数的效果:第1个是节约参数的DeLighT transformation这个block。第2个是通过使用DeLighT transformation,可以把multi-head attention转化成single-head attention。第3个是将attention的depth和width解耦,可以给每个block的设置不同的宽度和深度而不是简单地堆叠blocks。
DeLighT transformation
如下图17所示,假设输入特征的维度是 ,DeLighT transformation先将其映射到高维的空间 (Expansion),然后使用 层的group transformation将其缩减为一个维的输出向量 (Reduce)。在Expansion和Reduce的过程中,DeLighT transformation都使用Group Linear Transformation以节约参数。为了解决不同组之间特征不共享的问题,对不同组的feature进行shuffling,与卷积网络的channel shuffle相似。
一种提升Transformer性能的方法是增加输入输出的特征维度 ,DeLighT 的做法是提升intermediate DeLighT transformations的维度,而不需要增加attention输入特征的维度。
那么在实际应用的时候我们一般是用DeLighT Block来替换你传统的Transformer Block。
每个DeLighT Block的超参数有5个:
- Group Linear Transformation (GLT layers) 的层数 。
- Group Linear Transformation的最大分组数 。
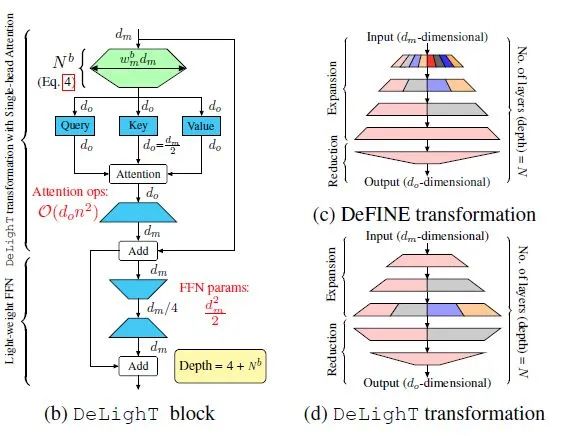 图17:DeLighT transformation的结构
图17:DeLighT transformation的结构DeLighT transformation的过程可以分解为Expansion阶段和Reduction阶段。在Expansion阶段,DeLighT transformation先将 维的输入特征通过 个层映射到高维的空间 维;在Reduction阶段,DeLighT transformation再将 维的输入特征通过 个层映射到低维的空间 维,写成表达式是:
式中, 是第 层的group数。测 和 是第 层的每一个group的权重和bias。第 层的输入特征 进入以后,被分成了 个group ,每个group 通过这一层的这一组的权重 和偏置 得到这一组的输出: 。再把这 个组的输出concat在一起得到这一层的输出 。其中 这个操作就是图4中的Split和Mixer操作,把输入和 进行Split和Mixer操作以避免vanishing gradient的问题。
DELIGHT第 层的分组数是:
就是前 层组数依次变为2倍,最大是 组。
DeLighT transformation的过程可以用下图18来表示。第1层的group=1,输出和输入一起通过Split和Mixer得到新的特征进入第2层。第2层的group=2,输出在2个组之间进行shuffle,再输出和输入一起通过Split和Mixer得到新的特征进入第3层。第3层的group=4,输出在4个组之间进行shuffle,再输出。
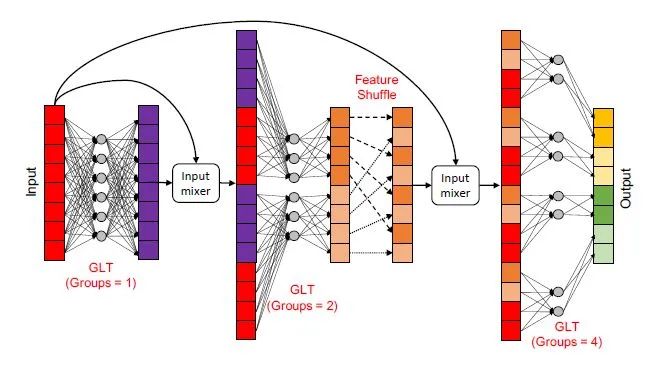 图18:DeLighT transformation的过程
图18:DeLighT transformation的过程下图19展示了DeLighT transformation的几种不同的变体,本文使用的是最后一种,它们的共同点是都使用了Group linear transformation (GLT)。
图19 (a)是最简单的GLT,随着网络的加深,分组的数量也有增加。
图19 (b)在GLT的基础上添加了feature shuffle的操作,就是中间层的输出进行shuffle,为了使GLT学到全局信息。
图19 (c)在之前的基础上又添加了Residual connection,具体的残差连接方法是Split and Mixer。这个操作是为了解决gradient vanishing problem。
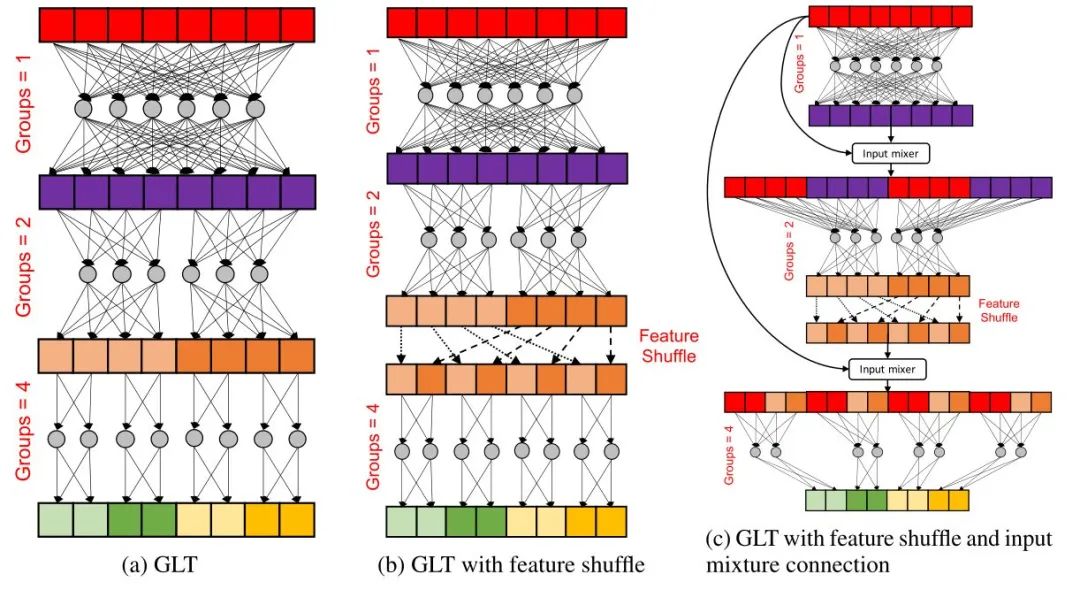 图19:DeLighT transformation的几种不同的变体
图19:DeLighT transformation的几种不同的变体Attention Layer:
下一步,当 维的输入特征映射到了 维的低维空间之后,这个 维的输出就进入到了single-head attention中,它当中的 全部都是 维的,输出当然也是 维的。再通过linear projection映射回原来的 维,表示为下式:
DELIGHT使用的是single-head的attention,计算复杂度是 ,相比原版Transformer attention的计算复杂度 来说节约了一半。
MLP:
对于FFN层,DELIGHT使用了轻量级的MLP,也包括2层FFN,只是中间的hidden dimension由原来的 变成了 。这样一来,节约了16倍的计算量和16倍的参数量。
深度:
1个 DeLighT block 的depth可以看做是N+4:
- 包含 个layer的DELIGHT transformation。
- 个输出concat起来之后经过fusion layer。
Block-wise Scaling
DeLighT的另一个特点是可以决定每个block的参数,取名为Block-wise Scaling。不是简单地堆叠很多相同的block或者简单地增大每个block的embedding dimension,因为这样做往往会带来冗余的参数。
DeLighT block 的超参数相比于普通的Transformer来说多了2个,一个是GLT layers 的数量 ,另一个是width multiplier ,借助这2个参数可以控制这个DeLighT block 的宽度和深度。假设 最大取 ,最小取 ,对于第 个block来说,我们假设GLT layers 的数量是 ,width multiplier是 。那么有下式成立:
式中, 代表DeLighT block 的总数,注意DeLighT block 是用来替代Transformer Block的。可以看出随着网络的深入,每个DeLighT block 的GLT的层数逐渐增加,宽度也逐渐增加。这样一来,输入附近的block又窄又浅,输出附近的block又宽又深,如下图20所示。
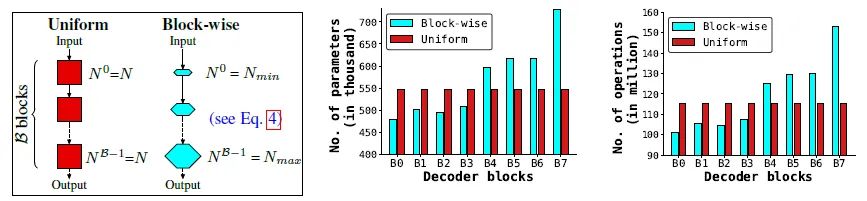
图20:逐块缩放由 个DeLighT block 构成的Transformer的总的深度是: ,其中 是原版Transformer的深度,剩下的是GLT layers的深度。
Experiment:
实验1:机器翻译
模型结构: 如下图21所示,编码器堆叠了 个DeLighT block。每个Block的配置按照Block-wise Scaling的方式决定。每个Block都会先经过DeLighT Transformation,目的是在高维空间中学习representations。然后再通过single-head attention编码contextual relationships。每个Block最后是轻量级FFN。使用learnable look-up table来将token映射为vector。
与encoder相似,解码器也堆叠了 个DeLighT block。Decoder blocks的结构与Encoder blocks一致,只是前面多了Masked Single-head Attention (其Key and Value来自Encoder的输出)。使用标准的learnable look-up table来将token映射为vector和linear classification layer将vector映射回tokens。
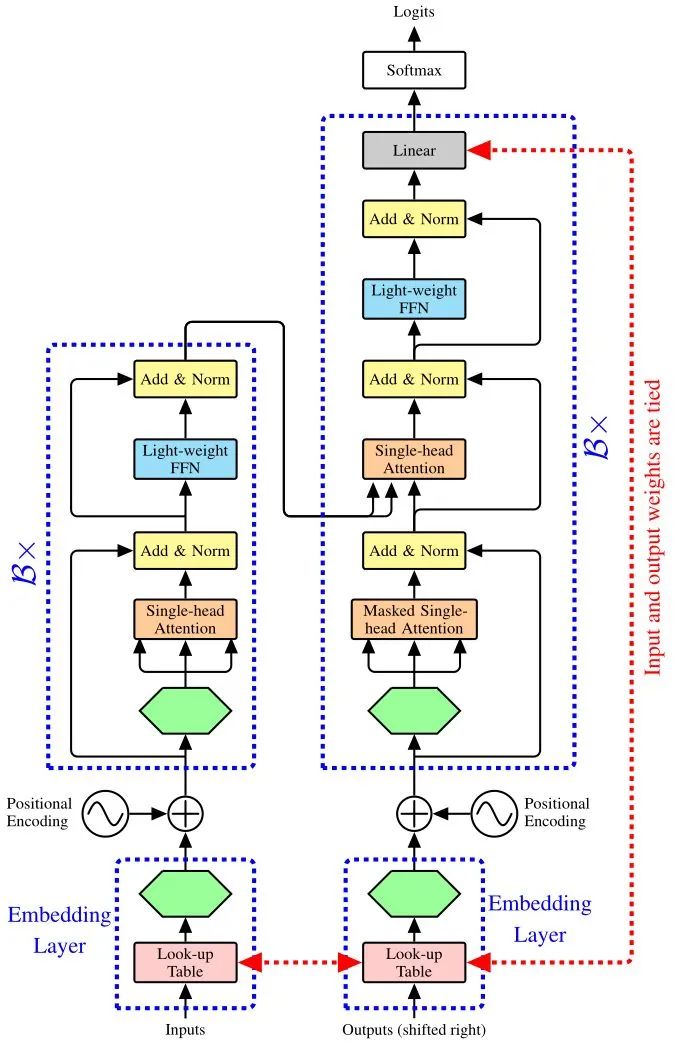 图21:DeLghT机器翻译结构
图21:DeLghT机器翻译结构数据集: IWSLT' 14 German-English (De-En),WMT' 16 English-Romanian (En-Ro),WMT' 14 English-German (WMT' 14 En-De),WMT' 14 English-French (WMT' 14 En-Fr)。
如下图22所示,DeLighT可以在更少的参数量的前提下得到比Transformer更优的性能。可以分别在性能相似的前提下减少1.8倍或2.8倍的参数量;当参数量上升时,DeLighT的性能超过了Transformer。比如在WMT' 14 En-Fr数据集上,DeLighT的深度是Transformer的3.7倍,参数量少了13M,BLEU指标涨点1.3。
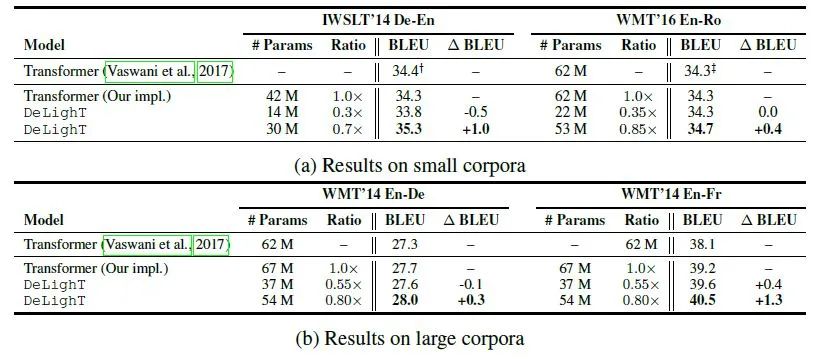
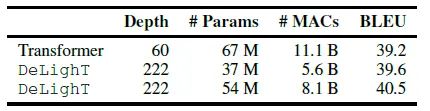
图22:与基线Transformer模型的性能对比下图23为DeLighT与SOTA模型性能的对比。对比的模型有基于NAS的Evolved Transformer等等强基线模型,DeLighT都取得了更优的性能。

图23:与SOTA模型性能的对比下图24为DeLighT不同大小模型的性能变化。DeLightT模型的性能随着网络参数的增加而提高。
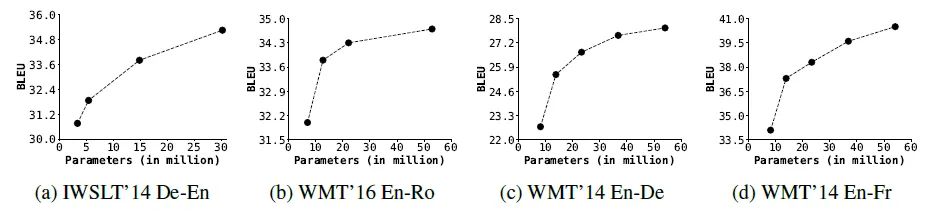
图24:DeLighT不同大小模型的性能变化实验2:语言建模
模型结构: 如下图25所示,堆叠了 个DeLighT block。每个Block的配置按照Block-wise Scaling的方式决定。每个Block都会先经过DeLighT Transformation,目的是在高维空间中学习representations。然后再通过single-head attention编码contextual relationships。每个Block最后是轻量级FFN。与之前的工作对应,作者使用tied adaptive input 和 adaptive softmax来讲token映射成词向量以及将词向量映射回token。
 图25:DeLghT语言建模模型
图25:DeLghT语言建模模型数据集:WikiText-103
下图26a为Perplexity随参数量的变化,DeLighT模型的性能优于Transformer-XL。
下图26b为DeLighT模型与其他SOTA的对比。DeLighT模型可以在节约大量参数的前提下得到更优的性能,表明DeLightT模型有助于学习强上下文关系。
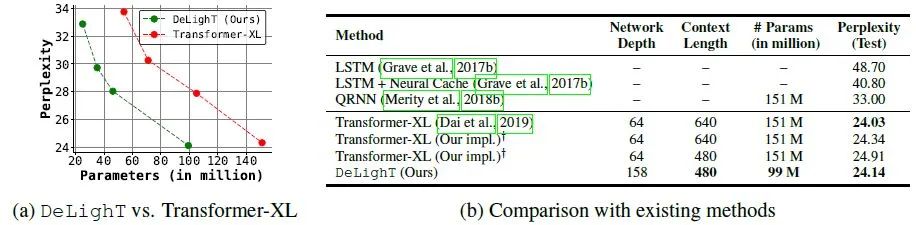 图26:语言建模实验结果
图26:语言建模实验结果小结:
DELIGHT通过3个创新点达到节约参数的效果:第1个是节约参数的DeLighT transformation这个block。第2个是通过使用DeLighT transformation,可以把multi-head attention转化成single-head attention。第3个是将attention的depth和width解耦,可以给每个block的设置不同的宽度和深度而不是简单地堆叠blocks。
总结:
本文讲解了2种Transformer模型:DeFINE,DeLight。它们分别代表2种轻量化Transformer的方式,即:
- DeFINE:One-hot vector → word embedding 的过程轻量化。
- DeLight:Transformer Block内部轻量化。
这2个模型提供了2种压缩Transformer模型的维度。
DeFINE是一个高效地得到词向量的模块,它规避了传统的直接把token映射为 维词向量的过程,而是把token映射成一个 维向量 ( ),再通过DeFINE变为需要的 维词向量。在这个过程中节约了大量的参数,同时得到了相似的性能。DeFINE通过使用改进的分组卷积HGT,在学习到各个组的特征的同时减少参数量,并结合skip-connection使得模型更易训练。
DeLight改变了Transformer Block的结构,使之变得更加轻量化。思路依然是先扩大维度,再降低维度,把降低后的维度的特征送入Self-attention layer里面,以减少attention layer的计算量和参数,并配合轻量化MLP节约计算量。







