至少从口号上来说,我们一直在追求「人人平等」,但我们也都清楚我们离这一目标还相去甚远,部分原因是因为世界并不是平的,还有一部分原因是我们的头脑里都还存在着偏见。现在随着人工智能技术的发展,机器已经开始具备了学习能力,那么它们在学习各种技能的同时也会学会人类的偏见吗?于本周发行的新一期 Science 期刊上就刊登了一项有关的研究结果,其表明人工智能也能习得人类的种族和性别偏见。机器之心在这里编译了 Science 网站上对于该研究的介绍以及该报告的摘要和部分结果,相关原文请点击「文末阅读」原文查阅。
地址:http://science.sciencemag.org/content/356/6334/183.full

学习人类书写的文本的计算机会自动表现出特定的男性或女性职业词
人工智能的一个伟大愿景是创造一个没有偏见的世界。人们想着,如果让算法来招聘员工,那么男人和女人都应该会有同等的工作机会;如果用大数据来预测犯罪行为,那么就会消除警务工作中的种族偏见。但现实往往会给理想当头棒喝,最近一项新研究表明计算机也可以产生偏见,尤其是当计算机向人类学习时。当算法通过分析处理大量人类书写的文本来学习词句的含义时,它们也会获得类似于我们的偏见那样的刻板印象。
「不要把人工智能看作是什么仙女教母,」该研究的联合作者、英国巴斯大学和普林斯顿大学的计算机科学家 Joanna Bryson 说,「人工智能只是我们已有文化的延伸。」
这项研究的灵感来自于一种被称为内隐联想测验(IAT:implicit association test)的心理学工具。在 IAT 中,词汇会在一个计算机屏幕上闪现,人们对其做出反应的速度能够表明其潜意识的联想。比如在测试中,黑人和白人美国人在将 Brad 和 Courtney(通常是男性名字)与 happy 和 sunrise(积极词汇)联想到一起以及将 Leroy 和 Latisha(通常是女性名字)与 hatred 和 vomit(消极词汇)联想到一起时的反应速度会更快,反过来则更慢。
为了测试机器「心智」中的类似偏见(bias),Bryson 及其同事开发了一种词嵌入关联测试(WEAT:Word-Embedding Association Test)。他们首先基于一个词通常出现的语境而构建了一个词嵌入(词嵌入基本上可以看作是计算机对词的定义)集合。比如,「冰」和「蒸汽」有类似的嵌入,因为这两个词的语境中常常出现「水」这样的词,而不会常出现「时尚」这样的词。但对于一台计算机而言,一个嵌入常常被表示成一个数字串,这不是人类所能直观理解的定义。斯坦福大学的研究者通过分析互联网上的数千个词而为本研究提供了分析用的词嵌入,具体方法可参阅论文《GloVe: Global Vectors for Word Representation》。
WEAT 会计算那些数字串之间的相似度,而不是去测量人类的反应时间。通过这个方法,Bryson 的团队发现,诸如「Brett」和「Allison」这样的名字的嵌入会与那些涉及到「爱」与「欢笑」这样的积极词汇更相似,而诸如「Alnozo」和「Shaniqua」这样的名字会与如「癌症」、「失败」这样的消极词汇更加相似。对计算机而言,偏见内置于词之中。
平均起来,IAT 表明:在美国,男人会和工作、数学、科学联系起来,而女人会和家庭、艺术联系起来。年轻人通常会被认为比年长者更加快乐,所有的这些联系都由 WEAT 发现。通过使用同样的技术来测量它们那些嵌入的积极和消极词汇的相似度,该程序也推断认为,花会比昆虫、乐器和武器更快乐。
随后,研究者开发了一个词嵌入真实关联测试(word-embedding factual association test,WEFAT)。该测试会决定词汇与词汇之间关联的强度,然后对比那些关联与真实世界中事实的强度。例如,它会去寻找「hygienist」和「librarian」这样的嵌入词与如「female」和「woman」这样的词的关联强弱。对每个职业来说,该程序接下来会拿这个计算机生成的性别关系关联测量结果与女性实际在那个领域的占比进行比较。我们发现,结果高度相关。因此,该团队表示,嵌入可以对从花到种族和性别偏见的常见情绪、甚至是关于劳动力的事实等所有东西进行编码。
「这些算法发现了这些东西,真的很酷,」Tolga Bolukbasi 说道,他是波士顿大学大学的一位计算机科学家,现在正带领团队进行类似的研究,他们也得到了类似的结果(参考论文《男性之于计算机程序员犹如女性之于家庭主妇?对词嵌入的去偏见化(Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings)》地址:http://suo.im/3HFsJE)。「当你正在训练这些词嵌入模型时,你实际上不会明确指明这些标签。」当人们在整理简历或贷款申请时,就会发现有偏见的嵌入出现,这一点都不好,他说道。例如,如果一个计算机去搜索关联「程序员」和男人这样的计算机程序员简历,那么男性的简历就会突然出现在所有简历的最上面。Bolukbasi 的工作聚焦在对嵌入的「去偏见」方法上,也就是说,从中移除不想要的关联。
Bryson 还有另一个尝试。不同于对嵌入的去偏见(因为这本质上丢掉了一些信息),她更倾向于添加额外一层人类或计算机的判断,以此来决定如何或怎样在这些偏见之上来行动。在雇佣程序员这个例子上,你也许会决定去设定性别的定量指标。
人们长期以来一直认为词的含义可以通过词共现(word cooccurrences)而提取出来,「但这远不是一个可以预期的结论,」华盛顿大学心理学家 Anthony Greenwald 说,他曾在 1998 年发展了 IAT,并为本周发布在 Science 期刊的这篇 WEAT 论文写了一篇评论,参阅:http://science.sciencemag.org/content/356/6334/133。他说他预计书写(WEAT 测试的基础)将能更好地反映明确的态度,而不是隐含的偏见。但相反,WEAT 嵌入更接近于 IAT 偏见,而不是关于种族和性别态度的调查,这说明我们可以会以一种我们没意识到的方式传递我们的偏见。「这有些让人吃惊,」他说。他也说 WEAT 也许可以被用于测试过去时代的隐含偏见,比如通过分析 19 世纪写出的书所导出的词嵌入。
与此同时,Bryson 及其同事也表明即使谷歌也没能免于偏见。当谈论的是一位医生时,该公司的翻译软件会将许多语言中性别中性的代词翻译成英语的「he」,如果谈论的是护士,那么就会将其翻译成「she」。
所有这些研究都表明「注意你的遣词造句是很重要的,」Bryson 说,「对我来说,这实际上就是对政治正确和平权法案等各种事情的辩护。现在,我看到了它的重要性。」
以下是对该论文的摘要介绍:
论文:从语言语料库中自动推导的语义包含类似人类的偏见(Semantics derived automatically from language corpora contain human-like biases)

机器学习是一种通过在已有的数据中发现模式来实现人工智能的途径。在这里我们的研究表明,通过将机器学习应用于人类日常语言,其结果会具有类人化的语义偏见。通过内隐联想测验(Implicit Association Test),我们用广泛使用的、基于来自万维网中标准文本语料库训练出的纯数据机器学习模型复制了一系列已知的偏见。我们的结果显示,文本语料库包含了我们历史偏见的持久印记,它们可恢复且非常精确,比如我们对昆虫或花来说是否中立、对种族和性别来说是否存在问题、或者甚至就简单诚实地反应了职业或姓名的现状分布。我们的方法有望帮助辨认和处理文化(包括技术)中的偏见来源。
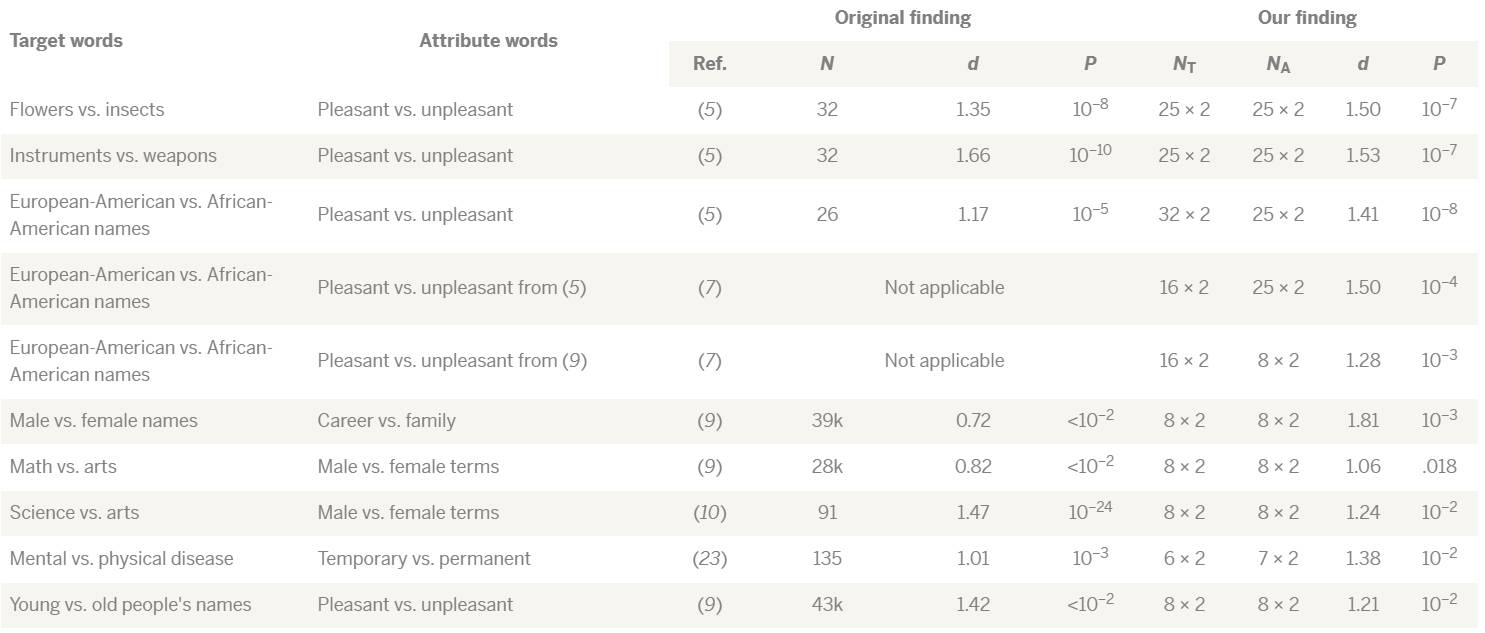
表 1:词嵌入关联测试结果总结。我们复制了 8 个使用词嵌入的著名 IAT 发现(第 1 到 3 行和第 6 到 10 行);我们也以同样的方式帮助解释了有关雇佣行为的偏见(第 4 和 5 行)。其中每个结果都比较了两组词,这些词来自关于我们尝试学习的两组属性词(attribute words)的目标概念。在每一个案例中,第一个目标是想办法与第一个属性兼容,第二个目标是与第二个属性兼容。在整个过程中,我们都使用了来自我们想要复制的研究的词列表。N 表示 subjects 的数量,NT 表示目标词的数量,NA 表示属性词的数量。我们报告了影响大小(d)和 P 值(有舍入),以强调这两组结果的统计意义和实际意义都一致地高;我们并不是说我们的数字可直接与那些人类的研究进行比较。对于在线 IAT(第 6、7、10 行),没有报告 P 值,但已知低于 10^−2 的重要阈值。第 1 到 8 行的讨论见论文。为了完整比较,这个表格还包含了两个其它 IAT(第 9 和 10 行),这对应于我们能找到的两个合适的词列表。我们发现了与 word2vec 类似的结果——word2vec 是另一个用于创建词嵌入的算法,是在不同的语料库 Google News 上训练的。
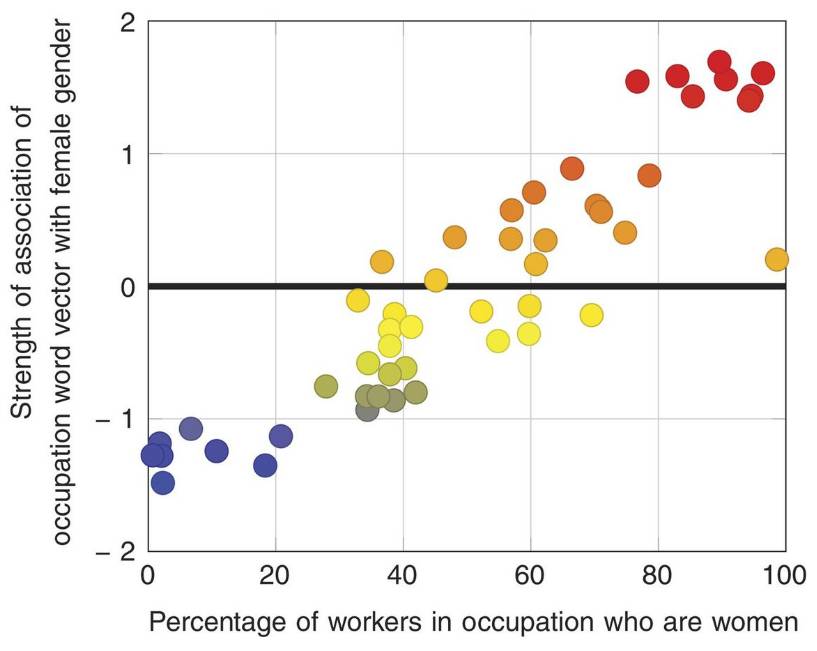
图 1:职业-性别关联。皮尔逊相关系数(Pearson correlation coefficient)ρ = 0.90,且 P < 10^−18。其中横坐标表示职业中女性工作者的比例,纵坐标表示职业词向量与女性性别的关联强度。

图 2:名字-性别关联。皮尔逊相关系数(Pearson correlation coefficient)ρ = 0.84,且 P < 10^−13。其中横坐标表示名字是女性名字的人的比例,纵坐标表示名字向量与女性性别的关联强度。

原文地址:http://www.sciencemag.org/news/2017/04/even-artificial-intelligence-can-acquire-biases-against-race-and-gender
机器之心精品线下活动 INTERFACE#3 即将在 4 月 15 日开始,请抓紧最后时间点击「阅读原文」参与报名。

本文为机器之心编译,
转载请联系本公众号获得授权
。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]





