(点击上方蓝字,快速关注我们)
来源:Exolution
junjiecai.github.io/posts/2016/Oct/20/none_vs_nan/
如有好文章投稿,请点击 → 这里了解详情
python原生的None和pandas, numpy中的numpy.NaN尽管在功能上都是用来标示空缺数据。但它们的行为在很多场景下确有一些相当大的差异。由于不熟悉这些差异,曾经给我的工作带来过不少麻烦。 特此整理了一份详细的实验,比较None和NaN在不同场景下的差异。
实验的结果有些在意料之内,有些则让我大跌眼镜。希望读者看过此文后会None和NaN这对“小妖精”有更深的理解。
为了理解本文的内容,希望本文的读者需要对pandas的Series使用有一定的经验。
首先,导入所需的库
In[2]:
from numpy import NaN
from pandas import Series, DataFrame
import numpy as np
数据类型?
None是一个python特殊的数据类型, 但是NaN却是用一个特殊的float
In[3]:
type(None)
Out[3]:
NoneType
In[4]:
type(NaN)
Out[4]:
float
能作为dict的key?
In[5]:
{None:1}
Out[5]:
{None: 1}
In[6]:
{NaN:1}
Out[6]:
{nan: 1}
In[7]:
{None:1, NaN:2}
Out[7]:
{nan: 2, None: 1}
都可以,而且会被认为是不同的key
Series函数中的表现
Series.map
In[8]:
s = Series([None, NaN, 'a'])
s
Out[8]:
0 None
1 NaN
2 a
dtype: object
In[9]:
s.map({None:1,'a':'a'})
Out[9]:
0 1
1 1
2 a
dtype: object
可以看到None和NaN都会替换成了1
In[10]:
s.map({NaN:1,'a':'a'})
Out[10]:
0 1
1 1
2 a
dtype: object
同样None和NaN都会替换成了1
In[11]:
s.map({NaN:2,'None':1,'a':'a'})
Out[11]:
0 2
1 2
2 a
dtype: object
将None替换成1的要求被忽略了
In[12]:
s.map({'None':2,NaN:1,'a':'a'})
Out[12]:
0 2
1 2
2 a
dtype: object
将NaN替换成1的要求被忽略了
总结: 用Series.map对None进行替换时,会“顺便”把NaN也一起替换掉;NaN也会顺便把None替换掉。
如果None和NaN分别定义了不同的映射数值,那么只有一个会生效。
Series.replace中的表现
In[13]:
s = Series([None, NaN, 'a'])
s
Out[13]:
0 None
1 NaN
2 a
dtype: object
In[14]:
s.replace([NaN],9)
Out[14]:
0 9
1 9
2 a
dtype: object
In[15]:
s.replace([None],9)
Out[15]:
0 9
1 9
2 a
dtype: object
和Series.map的情况类似,指定了None的替换值后,NaN会被替换掉;反之亦然。
对函数的支持
numpy有不少函数可以自动处理NaN。
In[16]:
np.nansum([1,2,NaN])
Out[16]:
3.0
但是None不能享受这些函数的便利,如果数据包含的None的话会报错
In[17]:
try:
np.nansum([1,2,None])
except Exception as e:
print(type(e),e)
unsupported operand type(s) for +: ‘int’ and ‘NoneType’
pandas中也有不少函数支持NaN却不支持None。(毕竟pandas的底层是numpy)
In[18]:
import pandas as pd
pd.cut(Series([NaN]),[1,2])
Out[18]:
0 NaN
dtype: category
Categories (1, object): [(1, 2]]
In[19]:
import pandas as pd
try:
pd.cut(Series([None]),[1,2])
except Exception as e:
print(type(e),e)
unorderable types: int() > NoneType()
对容器数据类型的影响
混入numpy.array的影响
如果数据中含有None,会导致整个array的类型变成object。
In[20]:
np.array([1, None]).dtype
Out[20]:
dtype('O')
而np.NaN尽管会将原本用int类型就能保存的数据转型成float,但不会带来上面这个问题。
In[21]:
np.array([1, NaN]).dtype
Out[21]:
dtype('float64')
混入Series的影响
下面的结果估计大家能猜到
In[22]:
0 1.0
1 NaN
dtype: float64
下面的这个就很意外的吧
In[23]:
Series([1, None])
Out[23]:
0 1.0
1 NaN
dtype: float64
pandas将None自动替换成了NaN!
In[24]:
Series([1.0, None])
Out[24]:
0 1.0
1 NaN
dtype: float64
却是Object类型的None被替换成了float类型的NaN。 这么设计可能是因为None无法参与numpy的大多数计算, 而pandas的底层又依赖于numpy,因此做了这样的自动转化。
不过如果本来Series就只能用object类型容纳的话, Series不会做这样的转化工作。
In[25]:
Series(['a', None])
Out[25]:
0 a
1 None
dtype: object
如果Series里面都是None的话也不会做这样的转化
In[26]:
Series([None,None])
Out[26]:
0 None
1 None
dtype: object
其它的数据类型是bool时,也不会做这样的转化。
In[27]:
Series([True, False, None])
Out[27]:
0 True
1 False
2 None
dtype: object
等值性判断
单值的等值性比较
下面的实验中None和NaN的表现会作为后面的等值性判断的基准(后文称为基准)
In[28]:
None == None
Out[28]:
True
In[29]:
NaN == NaN
Out[29]:
False
In[30]:
None == NaN
Out[30]:
False
在tuple中的情况
这个不奇怪
In[31]:
(1, None) == (1, None)
Out[31]:
True
这个也不意外
In[32]:
(1, None) == (1, NaN)
Out[32]:
False
但是下面这个实验NaN的表现和基准不一致
In[33]:
(1, NaN) == (1, NaN)
Out[33]:
True
在numpy.array中的情况
In[34]:
np.array([1,None]) == np.array([1,None])
Out[34]:
array([ True, True], dtype=bool)
In[35]:
np.array([1,NaN]) == np.array([1,NaN])
Out[35]:
array([ True, False], dtype=bool)
In[36]:
np.array([1,NaN]) == np.array([1,None])
Out[36]:
array([ True, False], dtype=bool)
和基准的表现一致。
但是大部分情况我们希望上面例子中, 我们希望左右两边的array被判定成一致。这时可以用numpy.testing.assert_equal函数来处理。 注意这个函数的表现同assert, 不会返回True, False, 而是无反应或者raise Exception
In[37]:
np.testing.assert_equal(np.array([1,NaN]), np.array([1,NaN]))
它也可以处理两边都是None的情况
In[38]:
np.testing.assert_equal(np.array([1,None]), np.array([1,None]))
但是一边是None,一边是NaN时会被认为两边不一致, 导致AssertionError
In[39]:
try:
np.testing.assert_equal(np.array([1,NaN]), np.array([1,None]))
except Exception as e:
print(type(e),e)
<class 'assertionerror'="">
Arrays are not equal
(mismatch 50.0%)
x: array([ 1., nan])
y: array([1, None], dtype=object)
在Series中的情况
下面两个实验中的表现和基准一致
In[40]:
Series([NaN,'a']) == Series([NaN,'a'])
Out[40]:
0 False
1 True
dtype: bool
In[41]:
Series([None,'a']) == Series([NaN,'a'])
Out[41]:
0 False
1 True
dtype: bool
但是None和基准的表现不一致。
In[42]:
Series([None,'a']) == Series([None,'a'])
Out[42]:
0 False
1 True
dtype: bool
和array类似,Series也有专门的函数equals用于判断两边的Series是否整体看相等
In[43]:
Series([None,'a']).equals(Series([NaN,'a']))
Out[43]:
True
In[44]:
Series([None,'a']).equals(Series([None,'a']))
Out[44]:
True
In[45]:
Series([NaN,'a']).equals(Series([NaN,'a']))
Out[45]:
True
比numpy.testing.assert_equals更智能些, 三种情况下都能恰当的处理
在DataFrame merge中的表现
两边的None会被判为相同
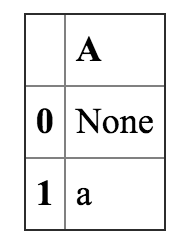
In[46]:
a = DataFrame({'A':[None,'a']})
b = DataFrame({'A':[None,'a']})
a.merge(b,on='A', how = 'outer')
Out[46]:
两边的NaN会被判为相同
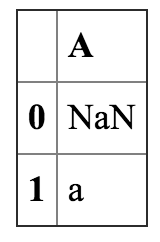
In[47]:
a = DataFrame({'A':[NaN,'a']})
b = DataFrame({'A':[NaN,'a']})
a.merge(b,on='A', how = 'outer')
Out[47]:
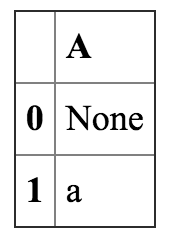
无论两边都是None,都是NaN,还是都有,相关的列都会被正确的匹配。 注意一边是None,一边是NaN的时候。会以左侧的结果为准。
In[48]:
a = DataFrame({'A':[None,'a']})
b = DataFrame({'A':[NaN,'a']})
a.merge(b,on='A', how = 'outer')
Out[48]:
In[49]:
a = DataFrame({'A':[NaN,'a']})
b = DataFrame({'A':[None,'a']})
a.merge(b,on='A', how = 'outer')
Out[49]:

注意
这和空值在postgresql等sql数据库中的表现不一样, 在数据库中, join时两边的空值会被判定为不同的数值
在groupby中的表现
In[50]:
d = DataFrame({'A':[1,1,1,1,2],'B':[None,None,'a','a','b']})
d.groupby(['A','B']).apply(len)
Out[50]:
A B
1 a 2
2 b 1
dtype: int64
可以看到(1, NaN)对应的组直接被忽略了
In[51]:
d = DataFrame({'A':[1,1,1,1,2],'B':[None,None,'a','a','b']})
d.groupby(['A','B']).apply(len)
Out[51]:
A B
1 a 2
2 b 1
dtype: int64
(1,None)的组也被直接忽略了
In[52]:
d = DataFrame({'A':[1,1,1,1,2],'B':[None,NaN,'a','a','b']})
d.groupby(['A','B']).apply(len)
Out[52]:
A B
1 a 2
2 b 1
dtype: int64
那么上面这个结果应该没啥意外的
总结
DataFrame.groupby会忽略分组列中含有None或者NaN的记录
支持写入数据库?
往数据库中写入时NaN不可处理,需转换成None,否则会报错。这个这里就不演示了。
相信作为pandas老司机, 至少能想出两种替换方法。
In[53]:
s = Series([None,NaN,'a'])
s
Out[53]:
0 None
1 NaN
2 a
dtype: object
方案1
In[54]:
s.replace([NaN],None)
Out[54]:
0 None
1 None
2 a
dtype: object
方案2
In[55]:
s[s.isnull()]=None
s
Out[55]:
0 None
1 None
2 a
dtype: object
然而这么就觉得完事大吉的话就图样图森破了, 看下面的例子
In[56]:
s = Series([NaN,1])
s
Out[56]:
0 NaN
1 1.0
dtype: float64
In[57]:
s.replace([NaN], None)
Out[57]:
0 NaN
1 1.0
dtype: float64
In[58]:
s[s.isnull()] = None
s
Out[58]:
0 NaN
1 1.0
dtype: float64
当其他数据是int或float时,Series又一声不吭的自动把None替换成了NaN。
这时候可以使用第三种方法处理
In[59]:
s.where(s.notnull(), None)
Out[59]:
0 None
1 1
dtype: object
where语句会遍历s中所有的元素,逐一检查条件表达式, 如果成立, 从原来的s取元素; 否则用None填充。 这回没有自动替换成NaN
None vs NaN要点总结
在pandas中, 如果其他的数据都是数值类型, pandas会把None自动替换成NaN, 甚至能将s[s.isnull()]= None,和s.replace(NaN, None)操作的效果无效化。 这时需要用where函数才能进行替换。
None能够直接被导入数据库作为空值处理, 包含NaN的数据导入时会报错。
numpy和pandas的很多函数能处理NaN,但是如果遇到None就会报错。
None和NaN都不能被pandas的groupby函数处理,包含None或者NaN的组都会被忽略。
等值性比较的总结:(True表示被判定为相等)
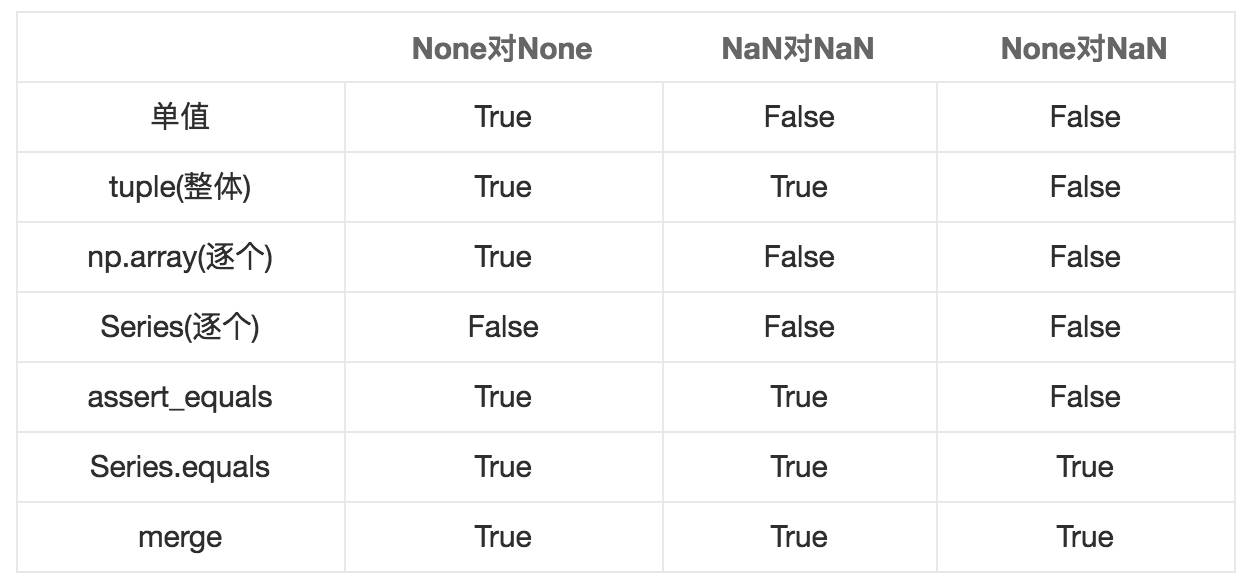
由于等值性比较方面,None和NaN在各场景下表现不太一致,相对来说None表现的更稳定。
为了不给自己惹不必要的麻烦和额外的记忆负担。 实践中,建议遵循以下三个原则即可
在用pandas和numpy处理数据阶段将None,NaN统一处理成NaN,以便支持更多的函数。
如果要判断Series,numpy.array整体的等值性,用专门的Series.equals,numpy.array函数去处理,不要自己用==判断 *
如果要将数据导入数据库,将NaN替换成None
看完本文有收获?请转发分享给更多人
关注「Python开发者」,提升Python技能











