Introduction
If you have spent some time in machine learning and data science, you would have definitely come across imbalanced class distribution. This is a scenario where the number of observations belonging to one class is significantly lower than those belonging to the other classes.
This problem is predominant in scenarios where anomaly detection is crucial like electricity pilferage, fraudulent transactions in banks, identification of rare diseases, etc. In this situation, the predictive model developed using conventional machine learning algorithms could be biased and inaccurate.
This happens because Machine Learning Algorithms are usually designed to improve accuracy by reducing the error. Thus, they do not take into account the class distribution / proportion or balance of classes.
This guide describes various approaches for solving such class imbalance problems using various sampling techniques. We also weigh each technique for its pros and cons. Finally, I reveal an approach using which you can create a balanced class distribution and apply ensemble learning technique designed especially for this purpose.
Table of Content
-
Challenges faced with Imbalanced datasets
-
Approach to handling Imbalanced Datasets
-
Illustrative Example
-
Conclusion
1. Challenges faced with Imbalanced datasets
One of the main challenges faced by the utility industry today is electricity theft. Electricity theft is the third largest form of theft worldwide. Utility companies are increasingly turning towards advanced analytics and machine learning algorithms to identify consumption patterns that indicate theft.
However, one of the biggest stumbling blocks is the humongous data and its distribution. Fraudulent transactions are significantly lower than normal healthy transactions i.e. accounting it to around 1-2 % of the total number of observations. The ask is to improve identification of the rare minority class as opposed to achieving higher overall accuracy.
Machine Learning algorithms tend to produce unsatisfactory classifiers when faced with imbalanced datasets. For any imbalanced data set, if the event to be predicted belongs to the minority class and the event rate is less than 5%, it is usually referred to as a rare event.
Example of imbalanced classes
Let’s understand this with the help of an example.
Ex:
In an utilities fraud detection data set you have the following data:
Total Observations = 1000
Fraudulent Observations = 20
Non Fraudulent Observations = 980
Event Rate= 2 %
The main question faced during data analysis is – How to get a balanced dataset by getting a decent number of samples for these anomalies given the rare occurrence for some them?
Challenges with standard Machine learning techniques
The conventional model evaluation methods do not accurately measure model performance when faced with imbalanced datasets.
Standard classifier algorithms like Decision Tree and Logistic Regression have a bias towards classes which have number of instances. They tend to only predict the majority class data. The features of the minority class are treated as noise and are often ignored. Thus, there is a high probability of misclassification of the minority class as compared to the majority class.
Evaluation of a classification algorithm performance is measured by the Confusion Matrix which contains information about the actual and the predicted class.
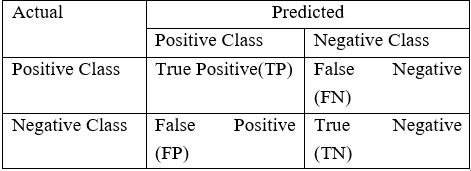 Accuracy of a model = (TP+TN) / (TP+FN+FP+TP)
Accuracy of a model = (TP+TN) / (TP+FN+FP+TP)
However, while working in an imbalanced domain accuracy is not an appropriate measure to evaluate model performance. For eg: A classifier which achieves an accuracy of 98 % with an event rate of 2 % is not accurate, if it classifies all instances as the majority class. And eliminates the 2 % minority class observations as noise.
Examples of imbalanced classes
Thus, to sum it up, while trying to resolve specific business challenges with imbalanced data sets, the classifiers produced by standard machine learning algorithms might not give accurate results. Apart from fraudulent transactions, other examples of a common business problem with imbalanced dataset are:
-
Datasets to identify customer churn where a vast majority of customers will continue using the service. Specifically, Telecommunication companies where Churn Rate is lower than 2 %.
-
Data sets to identify rare diseases in medical diagnostics etc.
-
Natural Disaster like Earthquakes
链接:
https://www.analyticsvidhya.com/blog/2017/03/imbalanced-classification-problem/
原文链接:
http://weibo.com/1402400261/EAjgf6np3?ref=home&rid=9_0_8_2669678905944369239&type=comment#_rnd1489830664327




