作者:王争,前Google工程师
公众号:小争哥
前段时间,网上疯传这样一个段子,”写完这个排序算法之后,我就被开除了“。我们一块来看看,他到底写了什么样的代码,能让主管一怒之下,把他开除了。
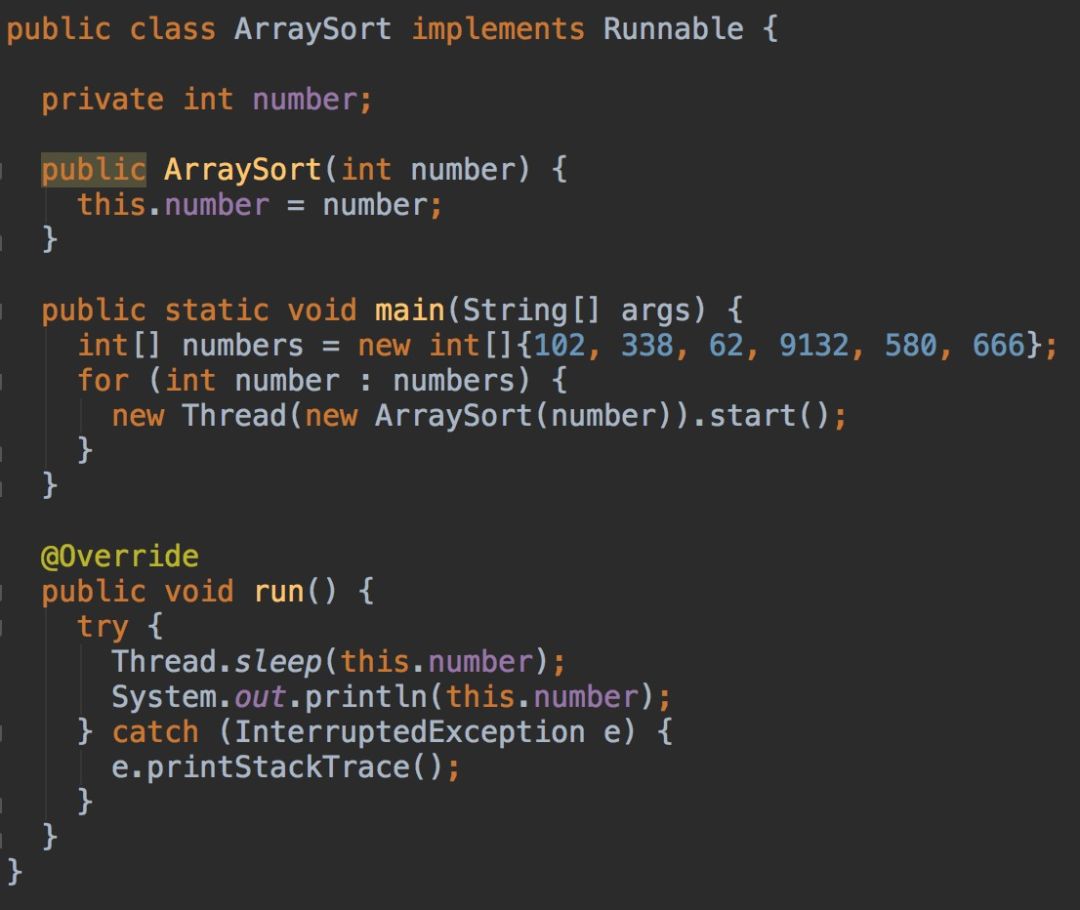
当我看到这段代码的时候,首先感叹的是,作者真的脑洞大开啊。不过,你还真先别嘲笑作者的智商。如果你去查一下资料的话,你就发现,这是一个经典的排序算法,叫做”睡眠排序“。哈哈,是不是很形象呢?
为了防止你写个排序算法被开除,又或者作为主管,一怒之下,开除员工,我今天就带你看看,历史上那些脑洞大开、有趣又奇葩的排序算法。
1. 睡眠排序算法(Sleep Sort)
我们要讲的第一个脑洞大开的排序算法,就是上面被开除的同学写的那个,睡眠排序算法。实际上,它的原理非常简单,你看代码就应该能看懂的。
如果对6个数据进行大小排序,我们创建6个线程,每个线程处理一个数字,数字对应的线程sleep的时间。比如,我们要排序{102, 338, 62, 9132, 580, 666}这样一组数据,我们就让这6个线程分别sleep 102ms、338ms、62ms、9132ms、580ms、666ms。当线程唤醒之后,最先唤醒的线程,打印出来的数据最小。以此类推,最后唤醒的线程,打印出来的数据最大。
这个排序算法,总的耗时,就是最大那个数字对应的线程sleep的时间。你可能会说,如果最大的数字很大,那等待最后一个线程睡醒,是不是要花很长时间呢?你说的没错。不过,我们可以让线程以更小的时间粒度来睡眠,比如我们把上面的睡眠时间的单位从毫秒(ms)换成微妙(us)。
而且,你可别小看这个看起来不切实际的排序算法。如果我们在未来的哪一天,真的能造出速度极快的量子计算机,那这个排序算法可能就真的切合实际了。
2. 猴子排序算法(Bogo Sort)
如果说刚刚那个排序算法还有点用的话,现在马上要讲的这个排序算法就是一个既不实用又非常低效的排序算法了。
这个排序算法的名字来自于无限猴子理论。这个理论实际上也很简单,意思就是,如果我们有无限只猴子,给他们无限的时间,让他们在键盘上随便乱敲,也可能敲出一本莎士比亚。这实际上是一个概率问题。
看明白了无限猴子理论,我们再来看下什么是猴子排序算法。猴子排序算法也很简单。它利用的也概率论知识。针对要排序的数据集合,我们每次随机生成一个排列,看是否完全满足从小到大排列,如果不满足,我们就继续再随机生成一个排列,直到随机出一个排好序的排列。总有一天会歪打正着,正好遇到一个有序的排列。
while not isInOrder(deck): shuffle(deck)
3. 慢速排序算法(Slow Sort)
这个排序算法是1986年由Andrei Broder和Jorge Stolfi发表。从名字上就能看出很慢的排序算法:慢速排序算法。它从结构上,看起来有点类似归并排序算法,伪代码如下。
procedure slowsort(A,i,j) if i >= j then return m := ⌊(i+j)/2⌋ slowsort(A,i,m) slowsort(A,m+1,j) if A[j] < A[m] then swap A[j] and A[m] slowsort(A,i,j-1)
从代码上实现上看,这个排序算法看似很牛逼的样子,分治思想、递归实现都用上了。我们想要排序下标是i到j之间的数据,算法先排序好前半段,再排序好后半段,然后把最大值放到下标为j的位置,最后还要再把除了最大值之外的下标是i到j之前的数据,再重新排序。
算法是正确,可以实现将一个无序数据集合排序的效果。但如果我们把时间复杂计算的递归公式写出来,你就知道,它的时间复杂度很高了。
T(n) = 2*T(n/2) + T(n-1) + C(C表示常量时间)
这个时间复杂度的公式推导很复杂,我直接给出结论:





