本文主要讨论的是前端可用性相关话题,以在美团点评移动端网页收银台的实践为例,讲解收银台前端是如何保障可用性的。

在美团点评,收银台是一个横向的业务基础服务,所有业务的闭环环节。所有线上业务最终完成交易全部由收银台来完成,它的重要性不言而喻,对于收银台来说,有三点需要保障,这三点分别是『可用性』、『体验』、『安全』,他们都共同为一个重要指标服务,那就是『支付成功率』,而对支付成功率影响最大的就是可用性。可用性对支付成功率的影响有多大?一个小小的 Bug 上线后即使及时发现并回滚,可能也会造成几百上千万的营业额损失,这对于整个团队来说是无法接受的。所以,对于收银台来说,保障可用性是第一优先级。
一般可用性都是说后端服务的可用性,都说我们的服务可用性到了几个 9,很少有人把可用性放到前端来。其实对于任何一个有 UI 交互流程的业务,都会有前端服务可用性,后端的可用性做的再高,前端一个按钮写的有问题点击不起作用也会导致用户无法完成流程。
前端服务可用性包含三个部分:
-
前端代码可用性(测试质量,线上异常)
-
静态资源服务可用性
-
网络链路可用性(DNS 劫持,网络性能)
既从业务后台服务往上,一直到用户界面,一切都是前端服务,这里面一切用户可能遇到的问题都是前端可用性的范畴。
这就是我们认为的前端可用性,收银台的可用性建设就是围绕着这三个部分展开的。
前端服务的可用性衡量和后端的衡量方法相类似,既不考虑影响范围大小,只考虑存在故障的时常,最大化考量可用性。可用性指标不是为了让我们通过复杂的算法来减小事故对可用性计算的影响,而是为了激励我们在可观测范围内做到没有问题,越做越好。影响用户数,影响订单数,影响 GMV 等指标更多的是用于做事故定级。
前端代码可用性:
-
空指针
问题是困扰前端的一个大问题,由于 JS 本身是弱类型动态语言,无法在开发及编译过程中通过工具推导出可能出现问题的点,进而在前端研发过程中很容易疏忽造成空指针问题;
-
业务逻辑覆盖率
指的是在业务项目当中,代码对动态逻辑的处理能力,往往在一些复杂的业务项目当中,逻辑混乱交错,前端的展示和进一步的动作由后端控制,这种情况下复杂的逻辑交织在一起产生无数分支,逻辑环境难以模拟,进而很容易在逻辑的处理上产生疏忽;
-
兼容性
问题困扰着各个端的研发,对于前端来说,要面临的环境更多,包括平台、系统版本、浏览器版本、WebView 版本、Hybrid 桥版本等等,很难从测试角度全部覆盖;
静态资源服务可用性:
网络链路稳定性:
大块的问题就是上述几种,细枝末节的问题就不在这里一一细表,那么具体我们是怎么解决的呢?
记得刚刚开始负责支付业务的时候,老板 (rank) 经常问一个问题:“收银台稳定性怎么保障?”,我当时想的就比较简单,无非就是流程保障、测试保障等等,但这不是老板想听的,不然他也不会老问我,显然是当时没有回答出他想要的答案。现在想想真是 "too young too simple, some times naive"。
支付这样一个特殊的业务有它对可用性独到的要求,对于可用性保障上必然不是任何业务都会用到的那老几样儿。老板想听的是对稳定性保障的独到见解,可复制的方法,有可用性保障的理论基础,让任何一个日后负责这个业务的人都能够照方抓药,保障前端服务的稳定性。
现在总结起来可用性的保障分为三个阶段:
保障手段分为三个大类:
「软的」是指用“人”来保障的部分:
「硬的」是指用“工程工具”来保障的部分:
-
静态代码检查
-
单测
-
Web 自动化测试
-
持续集成
-
线上前端异常监控
-
业务异常监控
-
前端服务异常监控
-
网络异常监控
-
…
「根源的」是整个可用性保障的核心,是指通过“技术选型” 来让系统更健壮。这里面有两个核心点:
要求在具备伸缩性的基础下避免任何复杂的不可控技术方案。核心链路上的所有代码团队要具备维护能力,要减少外部依赖;
这里面有一个关键的选型概念就是
「场景契合度」
,技术选型不是你愿意用什么,你熟悉用什么,是在这个业务场景和团队规模下需要你用什么。
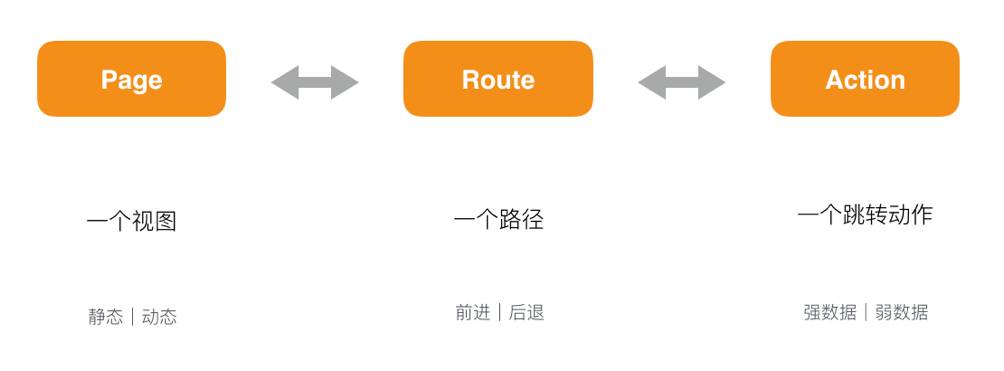
举个例子,收银台是一个单页应用,之所以设计成单页应用是因为它涉及到的视图跳转和数据传递太多,单页应用相比多页更具优势。那么在选型的时候我们当时有 React, Angular, Ember 等一线前端 SPA 框架可以选,但最后我们还是自己做了一个简单的视图生命周期管理工具,为什么?
-
「场景契合度」,React Angular 等前端框架更适合极端复杂的大型单页应用,为了能够更好的处理这种复杂度采用了一系列厚重的工具去约束研发的过程,其中还包含一些这个项目不会遇到的问题的优化,例如渲染优化等等。对于收银台来讲,单个视图中的复杂度并没有那么高,可以遇到前端渲染性能瓶颈的项目并不多;
-
「源码维护能力」,收银台作为核心链路中的核心业务,在技术上绝对不允许被动,团队必须具有核心代码的维护能力,而依照我们当时的团队规模,这是不现实的;
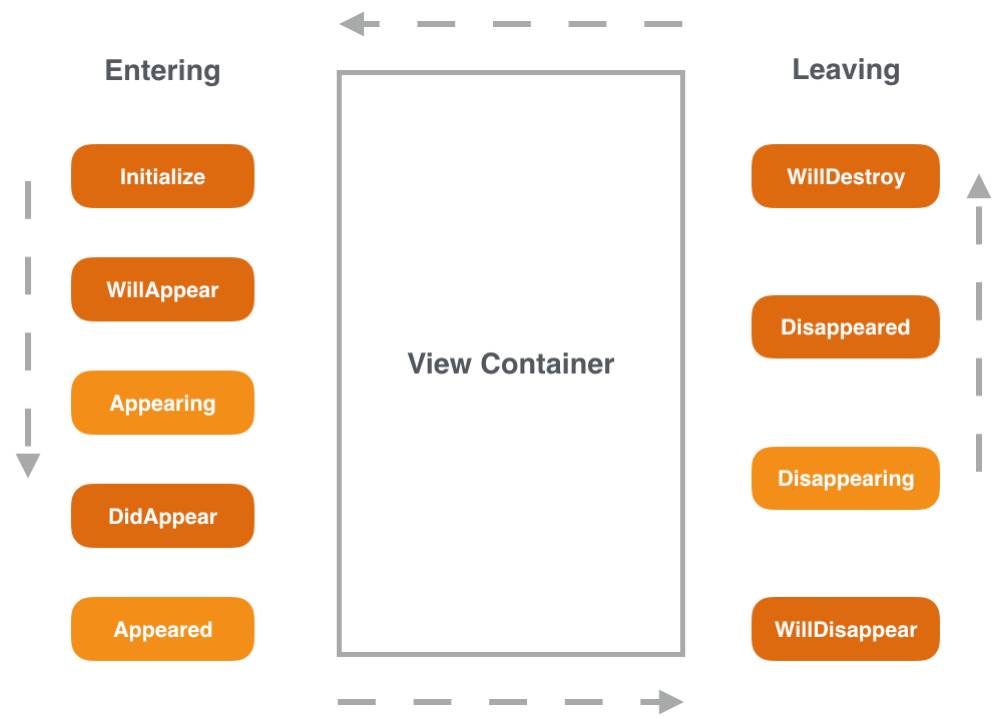
在收银台这个 SPA 场景里,我们只需要视图生命周期管理这个功能。所以,我们参考 Cocoa ViewController 的生命周期设计实现了一个简单的单页视图工具
「Cyra」
,它只负责视图生命周期的管理,简单、拓展性高、源码可维护无外部依赖。
举个例子,网页首帧渲染优化有三种常见方式:
其优化的核心内容就是把尽可能多的首帧渲染所需信息在第一个请求的响应中给出,也就是主文档请求。让用户能够尽可能快的看到内容。
从优化效果上来讲,SSR 的效果最好,它可以把 JS、CSS、HTML 以外的动态的数据一起通过第一个响应返回回来。
但是,最后我们选择的是编译预渲染,为什么?
先说什么是 SSR,SSR 这个概念是新提出来的,但原理上很早就存在,早年间一直都是 SSR,有服务器端把页面拼装好传递给客户端,类似 JSP、ASP 这种技术,和佛家的人生三境界一样,禅中彻悟后又回去了,就像现在的前端服务化很难做到当年微软 ASP.NET Web Form 那个水平。
后来前端行业发展迅速,发生了两个大的变化:
这时就用到了 SSR,通用做法是增加一个 Node 层,在服务器端做首屏内容的拼接,包含静态数据,这样能够保障首帧渲染不仅快,还包含首屏所需要的数据。其结构如下图:
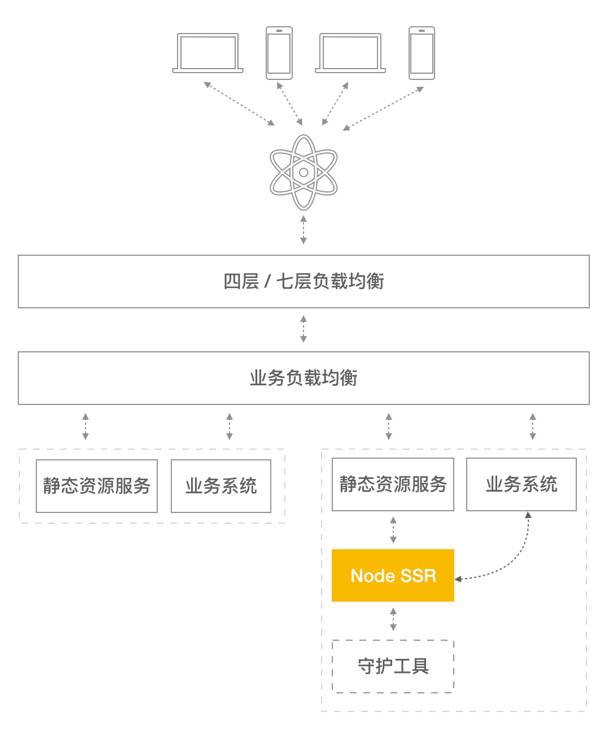
可以看到,Node 这一层在我们界面请求的核心链路上,那么 Node 本身的可用性和上下游的服务相比要差很多,其自身的稳定性需要许多其他工具去保障,那么对于这块业务来说,Node 这一层成为了「核心链路上的可用性短板」,这样即使背后的各个后端系统可用性再好,只要 Node 这一层挂掉就会造成用户无法访问的问题。
所以基于「避免出现核心链路上的可用性短板」这一层考量,我们退而求其次选用「编译预渲染」,在编译期间把首屏结构全部拼装好,这样可用性就得到了保障。
关于 Node 在服务端的应用上,我认为其实大多数情况下,不用要比用要难得多,关于这方面的一些思考可以详见后续文章《服务端为什么不能用 Node》。
理论有了,我们是怎么做的?
「软的」流程规范部分就不展开讲了,各个团队都差不多,只不过是完善不完善的差异。这个部分我主要讲一下「硬的」部分。
前文提到,「硬的」保障主要指的是工程工具的保障手段,工程工具很多,这里对应前文的几大问题顺序讲一讲我们的解决方案。
前端代码可用性部分主要有三个容易出问题的点:空指针、业务逻辑覆盖率、兼容性。
「空指针」部分的问题解决只能从语言本身来解决,JS 本身是弱类型动态语言,无法在开发及编译过程中通过工具推导出可能出现问题的点。针对这一点我们从 15 年开始实践 TypeScript ,当时也看了 Facebook 的 Flow ,没有选用 Flow 的原因是当时 Flow 还不够成熟。







