来源:langlotzlab.stanford.edu,知乎
整理:刘小芹
【新智元导读】
斯坦福大学医学院与 Langlotzlab 合作创建的一个 PB 级的大型医疗影像数据集 Medical ImageNet 最近发布,从官方网页的介绍中可以看到,该数据集包含近万张临床X光片,以及超过440万斯坦福的检测即将公开。如此大规模的医疗数据集有望解决医疗影像数据不足问题,助推利用机器学习分析医学图像方面的进步。

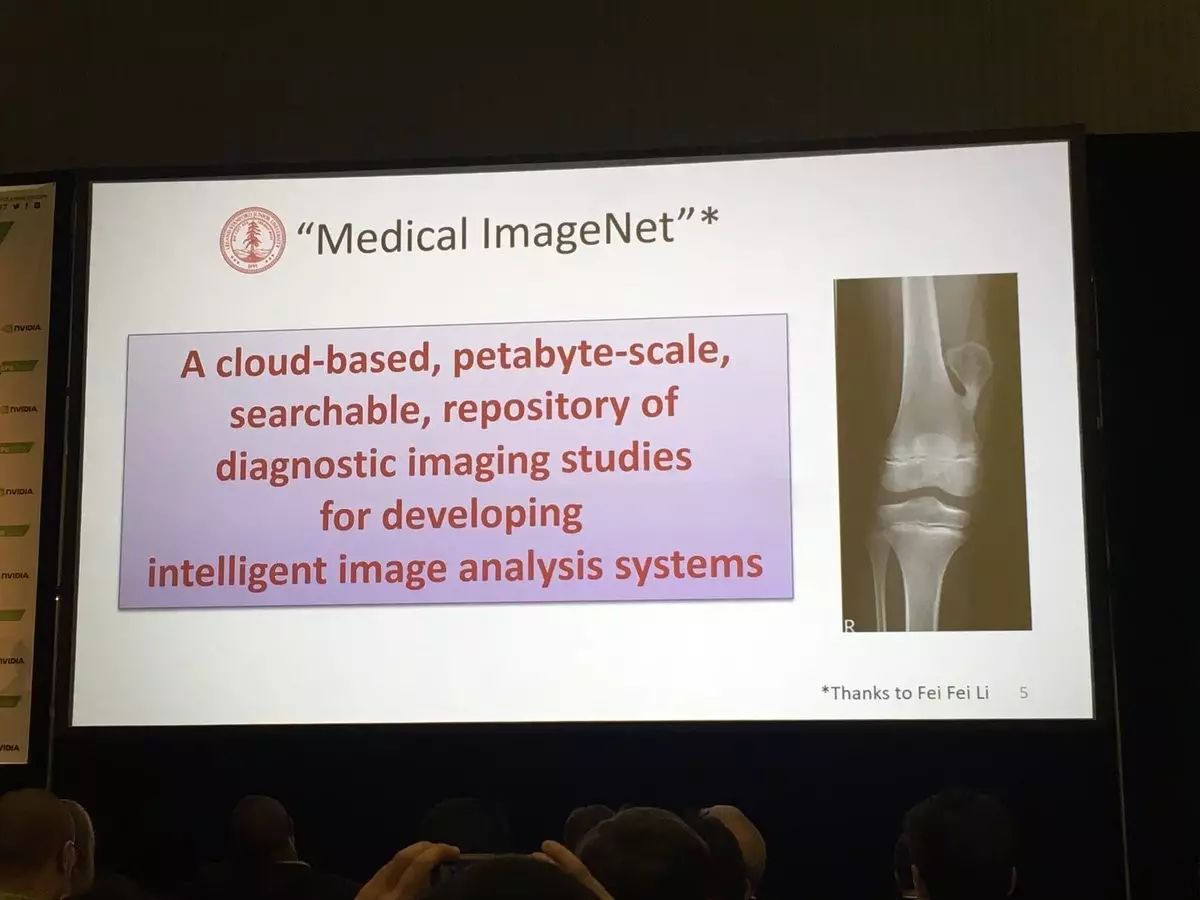
这是一个PB级规模的,基于云,多机构,可搜索,开放的诊断影像研究库,目的是开发智能影像分析系统。
主要目标
这个大型医疗数据集是 Langlotzlab 与斯坦福大学医学院内外合作建的,内容包含:
当然,还有很多公共数据集和挑战,特别是在共享数据方面。我们希望通过新的基础架构和共享方法来增加对这些数据集的开放获取。如果你想了解更多或提供协作,请联系实验室。
 图来自James Wang @jwan584 Twitter
图来自James Wang @jwan584 Twitter
斯坦福大学放射学和生物医学信息学教授 Curtis Langlotz 在正在举行的 2017 GPU 技术大会(GTC)上进行“Medical ImageNet:A Resource for Machine Learning for Medical Images”的talk,介绍了这个大型医疗影像数据集的内容、目的和进展等。
Talk 简介:
由于医学影像的复杂性,以及缺乏可用的有注释大型图像数据集,医学影像方面的机器学习研究相比一般图像的类似研究滞后。为了解决这个局限,斯坦福大学的研究人员正在创建一个大型临床影像研究资源,其中包含所有斯坦福大学放射学影像的去识别化版本,并从医学成像学本体的概念进行注释,而且与基因组数据,组织库和患者电子病历的信息相关联。
该数据集包含0.5 PB的临床放射学数据,包括450万项研究,超过10亿张影像。这一资源的长期目标是通过以下方式大幅度减少影像诊断的误差:(1)通过医学影像机器学医研究的数据和算法的标准化,促进可重复的科学实验;(2)让患者能够通过为这些实验自愿贡献数据的方式参与科学事业;(3)通过举办利用临床验证的图像数据集的比赛来激发创新;以及(4)将最终的数据,信息学工具,以及决策支持算法传播给尽可能广泛的研究人群。在这个演讲中,我们将回顾斯坦福Medical ImageNet 的进展情况,包括数据库结构和内容的详细信息,以及利用其包含的数据的深度学习实验的最新结果。
如何评价 Medical ImageNet?它将对医疗行业造成冲击吗?
Medical ImageNet 的公布引起了从
医学生,医科专家到机器学习研究者的较为广泛的关注,
以下介绍来自一名医学生的评论,欢迎读者留言交流看法。(来源:知乎 喜乐抱 ):
作为一个医学生,比较关注这类话题,以下是个人的一点浅见。
从两方面回答:1、根据题目,如何看待图像大数据;2、延伸,AI在医疗中可能的前景。
首先是第一个问题,斯坦福公布了大量的医疗图像,相信每个图像都已经对应了相应的诊断,否则光有图像没有太大意义,那么我觉得这是一件造福大家的事情。了解过相关信息的人或多或少都知道好的AI都是用数据喂出来的,一下有了这么大的数据量对于推进图像诊断在更广范围内的进步是十分有利的。所以直接回答原问题较为简单,这是一件造福世界的事。
当然,我想大家更想讨论的是第二个问题,也就是由原题目延伸出的问题,AI在医疗中可能的前景。我不讨论AI是否会取代医生这样的话题,因为凡是走“学习-练习-精进”过程的技术性工种将来都必然会被替代,区别只是时间,可能很长,就像人肯定会死,但具体到哪一天就说不定了。所以,我想讨论的是,假设想让人工智能帮助医疗行业,可能会是怎样的一条路径。
现在医疗相关领域最火的就是计算机图像诊断(本人不是计算机专业的,用词不专业请见谅),以我的理解,和人脸识别、图像识别的技术应该是类似甚至一致的,而应用起来最主要的区别有两点:
1、通过图像识别及深度学习算法训练后的AI对一张图片做出诊断后给出的是一连串十分具体的每种疾病的概率,这其中连极小概率也不会忽略,最终导致的现实问题就是检查报告单上打出来一大堆的问题,现在有些医院尝试用机器诊断心电图,结果就是如此,所以每张图还是要由心电图室的医师检查后才能发报告。虽然结果似乎不尽如人意,但是我认为识别图像并判断结果这件事机器可以做的很好或者说已经做的很好。这里我们应该把传统的心电图诊断分为两个部分,第一是通过读图得到途中的信息,第二是通过信息结合学习的整体医学体系和医学逻辑进行诊断。每个医生读图都是真么一个步骤,先把图读懂,再来抓重点。就这一点来说,我认为AI完全可以替代重复性读图,但诊断是我后面一部分要说的内容,暂且不表。之所以说是重复性的读图,因为计算机目前还只能识别出自己学过的表型,而不能进行更新研究,所以一旦出现新的表型,仍然需要科研人员。作为我们平时看病诊断来说,90%以上已经是重复的了。
2、更重要的一个区别在于责任划分,我觉得这是AI进入医疗的一个极大的绊脚石。由于医学的局限性,我们所能治愈的疾病是极少极少的,绝大多数疾病都是靠人的自愈能力恢复的。甚至曾经在美国还是英国(不记得了)有明确的统计数据表明,在就医人员中,由于医源性因素致病的人的数量远远高于被治愈人的数量。所以医疗过程中存在纠纷在所难免,如果是一个医生给你看病,谁看错了就找谁,不管是疏忽的还是系统性的,最终都能找到责任主体,要个说法。可是计算机呢,人们对他的要求是完美,出了错谁来承担责任,把电脑砸了?有人会说走保险这个方案确实可行,可对于真的被小概率的屎砸中的人来说,一般不会认栽,那他要起诉谁呢?要让谁撤职呢?那就是AI这个系统了,那一切就又回到了原点。
接着我想说的是诊断,这是我认为下一个适合AI进入的区域。不论是记忆力还是枚举排除能力还是概率计算能力,人都远不如计算机。人目前的绝对优势在于各类感受器丰富,所以可以采集病情,比如感受一下骨折患者的骨擦音,感受一下结核患者的握雪感等等,这些细微的感受需要及其灵敏的感受器,那就是人了。但是当病情与病史资料采集完全之后,判别、排除、诊断的计算过程,人就远不如计算机了。从两方面说:一,当医生拿到一个病人的情况后,在脑子里飞速的过一遍,看看这些症状和什么疾病相匹配,然后提出相应的检查方案。实际就是记忆与调取记忆的过程,这方面计算机是最擅长的。之所以不同医生会得出不同的结果,我认为是因为医生作为人,学习能力也是有限的,每个人知识的覆盖范围也是不同的,所以一些疑难杂症才需要众多医生会诊(这也是目前大型三甲医院的一大优势,好医生多,相互帮助),而对于计算机,尤其云计算实现后,存储量基本等于无上限,那么一个系统能学习的知识就可以是全部已有的知识了,甚至包括患者的生活环境、职业、生活习惯、地域等等对患者疾病所带来的影响,这样一来,机器是完全可以做出更全面的判断;二,IBM最近做了一件事情,给一个深度学习的程序喂了一种疾病方面的所有文献,然后给出一个患者的病情,让AI给出诊疗意见,最后得出的结果给众多医学专家看都无法辩驳。
这里我还想说一点,我们在说AI的时候往往都会要求它不犯错,正确率达到几个9,可是,我们这么做的原因究竟是真的认为这样的正确率是必须的还是仅仅由于不愿被取代的人之常情在作怪?如果是我,只要AI的正确率比专业人员的平均水平高,我就愿意使用;只要AI的正确率比顶尖专业人员的水平高,我就愿意信任。如果将来人工智能越训练出错越多,那我就要担心了,因为机器是不会犯错的,除非它进化了。
综上,在时间不定的未来,医生的职业方向可能也会发生改变,一种是专门采集病情的(其实这一种有完全可能在很久的将来被替代),另一种就是不断拓新,研究新的疾病、新的理论、新的治疗方法等新的事物。对于后一种我不认为也不希望能被取代,因为一旦达到这样的智能,它一定也会意识到人才是地球的病毒,后果就比较严重了。
最后顺带一句给各种深度学习大神的玩笑话,给每个深度学习的程序都喂一个牢不可破的数据:“以人为本”。嘿嘿。。。行文仓促,还请大家纠错。
作者:喜乐抱
链接:https://www.zhihu.com/question/59642245/answer/167575100





