
去年,我们曾经问过“大数据还是一件值得关注的大事吗?”,注意,因为大数据在很大程度上是一种“管道式工程”,所以受制于企业的接受周期,往往要落后于整个业界的炒作周期。因此,大数据技术需要几年的时间才能从一种看起来很酷的新技术,演变成企业在生产环境中实际部署的核心企业级系统。
2017年,我们已经很好地适应这种部署阶段 。“大数据”一词正在逐渐淡出我们的视野,但这种技术本身还在蓬勃发展。我们看到各行各业的轶事和证据证明相关产品越来越成熟,越来越多的“财富1000强”企业开始广泛部署,借助此类技术的许多初创企业的收入也开始快速增长。
同时,宣传炒作的泡沫已经无可争议地转移到生态系统中的机器学习和人工智能等领域。过去几个月里,AI领域经历了集体意识的“大爆炸”,这一情况与几年前大数据技术的“遭遇”几近相同,除了其发展速度更快。
从另一个角度来看,2017年也是令人兴奋的一年:翘首以盼的IPO 。今年前几个月里,大数据初创公司在这方面频繁出击,并获得了公开市场的广泛青睐。
总而言之,2017年数据生态系统正在开足马力。接下来小编将为大家介绍2017大数据全景回顾,将该行业的关键趋势进行综合整理,奉献给大家。
一 高层趋势
1、大数据+ AI =新栈(Big Data + AI = The New Stack)
2016年无疑是“机器学习年”,任何目睹过众多融资方案的VC都应该能够感受到这一点:每个初创公司都在变身成为“机器学习公司”的一年,“.ai”成为必备的域名,而“等等,我们会通过机器学习技术解决这个问题”开始频繁地出现在各类集资活动的演示PPT中。
有关人工智能的报道、座谈会、新闻邮件和微博信息扑面而来,对于许多早已对机器学习感兴趣的人而言,就好像发现自己当地的某个品牌突然开始了全球化扩张:一方面,感到骄傲;另一方面,又对这些装腔作势的“后来者”表示明显的厌烦,同时做好了不可避免会感到失望的心理准备。
虽然很容易认为这些趋势的发展非常和缓,但该领域的演变是不可避免且影响深远的:机器学习正在快速成为很多应用程序的关键组成部分。
我们正在目睹一个新技术栈的涌现 ,在这个技术栈中,大数据技术被用于处理核心数据工程挑战,而机器学习技术被用来从数据中提取价值(以分析见解或操作等形式)。换句话说:大数据提供管道,AI提供智能 。
当然,这种共生关系已经存在了很多年,但只有少数人能够真正实现它。
这些技术正在真正开始变的“大众化”。“大数据+ AI”成为许多现代化应用程序(无论针对消费者还是企业)正在构建的默认技术栈。其中将大数据与人工智能结合运用最好的当属Google和Apple。
Google提供优化的搜索引擎服务,后台的人工智能随着用户的使用而不断进化,使用的用户越多,搜索引擎也将越优化,优化之后,用户自然也就更多。除了搜索引擎,Google还通过Gmail、GoogleDocs等获取大量的“非结构化数据”。这样一来,Google的“大脑”就变得更加聪明了。
此外,Google还研发了“语义搜索”的进化系统;Apple的语音识别技术Siri也是基于最新人工智能理论(深度学习)构建的。
人们多年来一直在谈论“大数据”,但随着AI技术的飞速发展,这一天正在更快速地到来。

2、企业预算:逐利(Enterprise Budgets:Follow the Money)
过去一年,在我们与大数据技术的买家和卖家的交谈中发现,“财富1000强”公司中,核心基础设施的分析和升级方面的预算正在大幅增长,其核心关注点正是大数据技术。分析机构IDC 预计,到2020年,大数据和分析市场将从2016年的1300亿美元市场规模增长至2030亿美元。
“财富1000强”公司的许多买家在大数据技术方面正变得越来越成熟和挑剔。过去多年里,他们做了很多相关方面的功课,现在正处于全面部署模式中。这种情况不仅适用于技术型行业,目前许多其他行业都是如此。
在大公司每隔几年就要发生的旧技术替代自然周期的推动下,这种情况得到进一步加速。大数据技术从以前的逆风(难以剔除或取代原有基础架构)逐渐转化为顺风。当然,许多大企业(“晚期从众者”)依然处于大数据部署的早期阶段,但这种情况似乎正在加速演变。
3、企业数据向云端迁移(Enterprise Datamoving to the Cloud)
就在几年前,如果建议企业将数据迁移到公有云中,大型企业的CIO通常给出的回应是“除非我死了”,当时他们可能只愿将开发环境,或各种稀奇古怪,非关键的对外应用程序迁移至云端。
但现在画风开始变化了,根据商业分析软件 Tableau 发布的最新《云端数据报告》指出,越来越多的企业数据重心开始向云端集中。我们听到更多开放性的声音——大家逐渐认识到“我们的客户数据已经保存在Salesforce的云中”,或者“我们永远做不到像AWS一样的网络安全预算投入”,而讽刺的是,过去多年来,对安全性的顾虑曾是企业反对云计算的主要原因之一,但云供应商在安全与合规(HIPAA)等方面的努力最终得到了证明和回报。
毫无疑问,我们还远远未能实现将大多数企业数据转移到公有云中这一目标,部分原因在于遗留系统和管控制度等问题。但是,演变的趋势是显著的,并将继续加速。云供应商会尽一切努力促进这一过程,包括提供搬运海量数据的卡车。

【亚马逊提出利用卡车将大公司客户数据中心的数据转移至其公有云计算设施】
二、2017年大数据全景剖析
言归正传,下面我们就一起回顾一下2016年和2017年的大数据领域全景图:
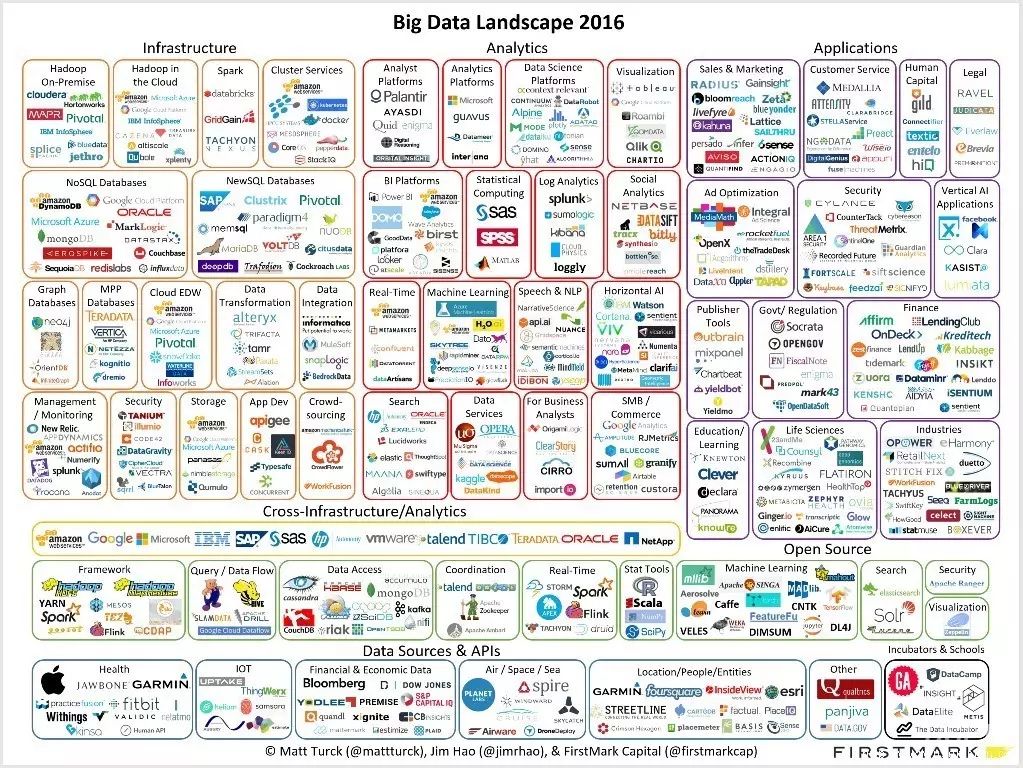
【2016年大数据全景,点击查看大图】

【2017年大数据全景图,点击查看大图】
1、合并风潮来了吗?
对比两年的大数据全景图,我们发现这张图正在变得越来越热闹,那么问题来了:这个行业是否迎来了大规模并购的风潮?答案是:至少目前看起来还没有这种趋势。
首先,风投们会继续乐于为新老公司提供资金支持。2017年Q1成长阶段的大数据初创公司获得了不少融资记录,包括:Looker(D轮,8100万美元)、InsideSales(F轮,5000万美元)、DataRobot(C轮,5400万美元)、Confluent(C轮,5000万美元)、Collibra(C轮,5000万美元)、Uptake(C轮,4000万美元)、WorkFusion(D轮,3500万美元),以及MapD(B轮,3500万美元)。
全球大数据初创公司在2016年创下了总计148亿美元的投资,其中10%由全球性的技术VC提供。
第二,2016年全景中曾提到,并购活动一直很稳定,但没有特别显著的案例,或许部分原因在于私营公司的估值一直保持高涨。2016年大数据全景中共有41家公司被并购,2017年并购的活动大体上会与去年持平。
另一方面,截至目前,2017年已经出现了一些大型的并购活动,包括Mobileye(被Intel以153亿美元收购)、AppDynamics(思科,37亿美元)、Nimble Storage(HPE,12亿美元)、Kaggle (Google收购)以及Dextro(Taser收购)等。
第三,一些大型大数据初创公司正在变成自主的上市公司。SNAP可以说是带动了技术公司IPO市场的复苏,但迄今为止,只有大数据企业成功抓住了这一机会。
虽然2016年,只有Talend一家大数据公司成功上市,但2017年到目前为止,该领域内满是 IPO机遇。Mulesoft和Alteryx成功上市且表现出色,发行价均超过了IPO价格。
在撰写本文时,Cloudera也即将上市,该公司最新预估价(41亿美元)与营收(2016年2.61亿美元)之间的空缺对于“独角兽”的估价现象将造成不小的考验。此外MapR以及位置智能公司Yext也正在准备上市。
谁会是下一个?Palantir多年来一直是业内最神秘的公司之一,目前也表示有公开上市的兴趣。鉴于Palantir最新的预估价为200亿美元,如果其公开估价能够接近这一水平,将可能成为IPO领域的一枚重磅炸弹。
2、打响云端战争
虽然大规模并购尚未出现,但业界另一股趋势需要注意,就是“功能性合并”,尤其是在云计算领域。该领域内一些关键玩家正在通过自研产品和开源计算引擎的实现,逐渐构建整合式的“大数据+ AI”服务,这种服务距离很多买家所期待的“一站式服务”越来越近了。
尤其是 AWS在产品发布的速度和幅度方面继续给人留下深刻印象。目前AWS几乎提供了大数据和AI方面的所有服务,包括分析框架、实时分析、数据库(NoSQL、图形等)、商业智能,以及日益丰富的AI能力,并且在深度学习方面颇有建树。按照这种速度,AWS很快将具备我们的大数据全景中所涉及的几乎所有基础架构和分析产品。
虽然 Google 涉足云计算的时间较晚,但它也在围绕大数据积极主动地构建一系列产品(BigQuery、Dataflow、Dataproc、Datalab、Dataprep等),并且已将AI视作超越竞争对手的杀手锏 。过去一年Google在AI方面做了很多事情,包括推出新的转换引擎,雇佣了两名出色的AI专家Fei-Fei Li和JiaLi来领导新成立的Cloud AI and Machine Learning部门,推出视频识别的机器学习API,并且收购了数据科学家社区Kaggle。
其他大型的IT供应商,如Microsoft、IBM、SAP、Oracle以及Salesforce等也在努力推出大数据/AI产品(包括云端和本地)。除了自行开发和进行收购外,他们的合作意愿也在逐渐加强,合作重点为手里“有数据的”和“有AI的”公司。例如IBM和Salesforce以及SAP与Google的合作都是其中的典型案例。
按照企业IT行业的标准来说,云供应商还比较小,但这些公司的野心(其中包括从企业栈底层的IaaS向应用发展的意图)与企业数据迁往云端的趋势相结合,意味着与传统IT供应商的全面战争已经打响,大家在争夺庞大的企业级技术市场的控制权,而大数据和AI将是核心战场。
三、2017年数据生态系统概览
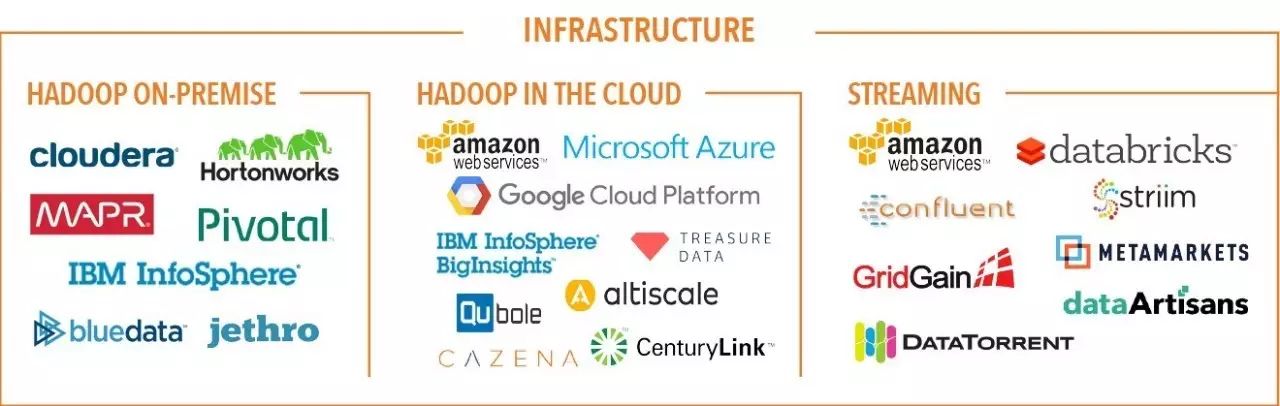
1、基础设施
去年的许多趋势仍在延续,例如流处理的重要性日益增加,Spark仍高居榜首,不过像Flink这样的有趣竞争者正在涌现。此外还有一下一些趋势:
在被NoSQL技术“打压”了10年之后,SQL数据库技术现已正式回归。Google最近发布了Spanner数据库的云端版。Spanner和 CockroachDB(Spanner的开源版)都提供一种高存活性、强一致性,可伸缩的SQL数据库。Amazon推出的Athena与Snowflake 等产品类似,是一种大型的SQL数据引擎,可直接查询S3 Bucket中存储的数据。Google BigQuery、SparkSQL以及Presto在企业逐渐获得采用——这些都是SQL产品。
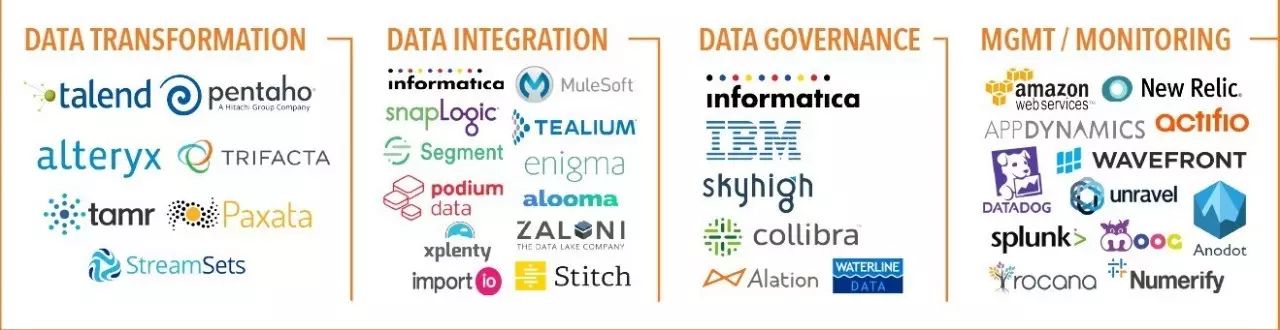
与公有云采用相关的一个有趣的趋势是数据虚拟化的迅速崛起。旧的ETL流程需要移动大量数据(通常需要为数据集创建副本)和创建数据仓库,数据虚拟化使得企业可以在数据保持不动的情况下对其进行分析,借此提高速度和敏捷性。许多下一代数据分析产品供应商,现在都可以同时提供数据虚拟化和数据准备服务,借此帮助客户更轻松地访问存储在云端的数据。
随着大数据在企业中的深入发展,以及数据的多样性和数量的不断增加,数据管控之类的话题变得越来越重要。许多企业选择了一种“数据湖”的方式,创建一个中央仓库,用于保存自己的所有数据。但除非人们知道数据湖中到底有什么,并且能按需访问分析工作所需的恰当数据,否则数据湖将全无用处。
但想让用户轻松找到自己需要的数据,同时管理好数据访问权则是非常棘手的。除了数据湖以外,治理的另一个集中的主题是以安全的、可审计的方式为任何人提供对可靠数据的便捷访问。Informatica、 Collibra、Alation等大小供应商提供了数据目录、参考数据管理、数据字典以及数据帮助台等服务。
2、分析
几年前,数据科学家还被誉为“21世纪最性感的职业”。就算到现在,Glassdoor的“美国最佳职位”排行榜中,“数据科学家”依然高居榜首。
但是,这个才出现没几年的职业现在似乎陷入了困顿。部分原因在于其必要性,虽然学校和程序员课程依然在批量制造出新的数据科学家军团,但这个岗位依然有很大空缺。在某些组织中,数据科学部门已经从原本的促进者演变为瓶颈。
与此同时,随着AI技术的大众化和自服务工具的飞速涌现,现在无论数据科学技能极为有限的数据工程师 ,甚至非技术型的数据分析师 ,都已经可以承担原本只能由数据科学家负责的基本任务。企业的大量数据工作,尤其是枯燥乏味的简单工作,将由数据工程师和数据分析师通过自动化工具来处理,而不再需要具备深厚技能的数据科学家参与。
也就是说,数据科学最终可能会完全由机器来处理。一些初创公司已经明确将自己的产品定位为“数据科学自动化”,其中最值得一提的包括刚刚获得5400万美元融资的DataRobot,SalesforceEinstein也宣称自己可以提供能自动生成的模型。
毫无疑问,这些趋势在数据科学社区不受欢迎,且存在一些争议。然而,数据科学家目前还不需要对此过于担心。在可预见的将来,自服务工具和自动化模型选择将会“强化”数据科学家的能力,而非彻底取代他们,他们可以将更多精力用于需要进行判断、创新、社交技能,或需要具备垂直行业知识的任务中。
在大多数大型企业中,大数据的运用通常都是从少数相对独立的项目开始的(这里部署个Hadoop集群,那里部署个分析工具),并且会产生一些新的职位(数据科学家、首席数据官)。
但现在异质性已经开始发展,各种各样的工具在整个企业范围内得到了使用。在大型企业中,集中化的“数据科学部门”正在让位于更加“去中心化的组织”,通常会有数据科学家、数据工程师,以及数据分析师组成的跨职能群体,正深入地融入到不同业务部门中。因此,对于平台来说,需求已经变的更加明确,那就是需要让所有人都能协作到一起来,因为大数据项目能否成功,主要取决于能否将不同技术、人员和流程完美融合在一起。
因此,一个全新的协作平台类型正在加速出现,并催生出一种所谓的“DataOps” (类似于DevOps)的概念。该领域值得关注的重大投资包括Knime(A轮,2千万美元)以及Domino Data Lab(A轮1千万美元)。Cloudera刚刚发布了一款基于所收购的Sense技术开发的工作台产品。这一领域的开源活动也很强劲,Jupyter和Anaconda就是例子。
3、应用程序
AI驱动的垂直应用程序的已经出现了好多年,但原本的溪流何时演变成了现在的滔天巨浪 ?突然之间,似乎每个人都开始开发AI应用程序,无论是新成立的,还是已经取得重大进展的初创公司,都开始在AI领域押注,希望能为自己创造下一轮增长点(例如InsideSales)。
在这种状况和趋势影响下,尽管有一些初创公司提出了很多激动人心的技术,但仍然存在挂羊头卖狗肉纯粹蹭热度的企业。在某些领域使用了某种机器学习技术的公司,并不算人工智能公司。
总地来说,AI初创公司的创建并不容易。而其中最关键的第一步在于选择一个垂直领域所面临的问题。除了要有深厚的技术DNA外,还需要深思熟虑的定位和策略。但是AI带来的无限可能性是很难不让人着迷的。
尤其是去年,把任何数据问题用AI来解决显然已成趋势,无论是企业一样还是垂直行业都是如此。考虑到现实情况,今年我们在图表的应用程序分类中添加了交通运输、房地产、保险业等垂直行业。同时还将一些非常活跃的行业拆分为两个类别,例如营销应用(拆分为B2B和B2C)以及生命科学(拆分为医疗健康和生命科学)。
除了这些领域外,还有一些非常新潮的应用(例如无人车),今天的AI技术正在缺乏想象力的企业应用领域发挥着作用,从人员流失预测到后端办公室自动化,再到安全,以不同形式提供了切实可行的收效。
AI导致人类失业的问题也许还没有得到政府部门的重视,但将来没有任何一个职业会不受影响。这些问题已得到很多白领职业的证明,例如医生或律师等。(参见 Ben Thompson:AI 已来,你最应该担心的不是生命,而是存在的意义)
尤其是金融领域,似乎一直在思考着AI的可能性和威胁。多年来艰难度日的对冲基金正在为自己的算法寻找合适的替代数据。由AI驱动的全新对冲基金(如Numerai、Data Capital Management 等)尽管还处在发展的早期阶段,但已经实现了快速发展。华尔街一些著名的事务所都在使用AI取代人力(BlackRock、 Goldman Sachs等)。
无论是爱是恨,2016年都可谓是“机器人元年”。很多消息交流服务都提供全自动化的实时对话代理程序。聊天机器人尽管出现的时间不长,但已经经历了好几个炒作周期,从一开始的承诺,到Tay所面临的灾难(译注:Tay是微软提供的一种基于人工智能技术的聊天机器人),再到迷你复兴,乃至于Facebook在其Messenger平台推出的AI机器人错误率达到70%之后缩减了这方面的努力。
现在看来对于机器人程序的热情似乎有些早,原因可能是人们因为机器人程序在亚洲的崛起,或者Slack等底层基础架构的快速增长而得出了过于乐观的信号。当然,这种机器人程序有着巨大的潜力,但其真正成熟还需要很长的时间。
目前,无论是“生产商”(初创公司需要专注于每个具体的业务领域,少作承诺)还是“消费者”(我们都需要习惯于机器人程序可以和不能做到的事情,Alexa正在帮助我们意识到这些!)都需要调整我们的期待值。
现在,最美好的未来可能属于重要领域需要人类介入的服务,或者完全采取不同于机器人程序的定位,使用AI技术来增强人类能力的技术(我们得出这一结论的依据来自frame.ai)。
四、结论
大数据与AI强强联合,我们即将进入大数据技术的“收获”季节。忽略所有的炒作,其潜能将非常巨大。
随着核心基础设施以及应用程序端的不断成熟,AI驱动的应用正在蓬勃发展,2017年,大数据/AI生态将开足马力,驶向美好未来。
附录1:2016年大数据版图推出以来的完整收购清单(被收购者/收购者/收购金额)
2017年第一季度 (5家)
Mobileye / Intel / $15.3B
AppDynamics / Cisco / $3.7B
Nimble Storage / HPE / $1.1B
Kaggle / Google
Dextro / Taser
2016 年(36家)
Qlik / Thoma Bravo / $3B
Cruise Automation / GeneralMotors / $1B
Apigee / Google / $625M
OPower / Oracle / $532M
Tapad / Telenor / $360M
Nervana Systems / Intel /$350M
SwiftKey / Microsoft / $250M
Withings / Nokia / $191M
Circulate / Acxiom (LiveRamp)/ $140M
Altiscale / SAP / $125M
Viv Labs / Samsung / $100M
Connectifier / LinkedIn /$100M
Recombine / Cooper / $85M
MetaMind / Salesforce / $32.8M
Livefyre / Adobe
TempoIQ / Avant
DataHero / Cloudability
Sense / Cloudera
io / GE
ai / Google
EagleEye Analytics / Guidewire
Attensity / inContact
RJMetrics / Magento Commerce
Placemeter / Netgear
Kimono Labs / Palantir
Tute Genomics / PierianDx
Statwing / Qualtrics
PredictionIO / Salesforce
Roambi / SAP
Visually / ScribbleTechnologies
Preact / Spotify
Nuevora / Sutherland GlobalServices
Geometric Intelligence / Uber
Platfora / Workday
Driven / Xplenty
Gild / Citadel
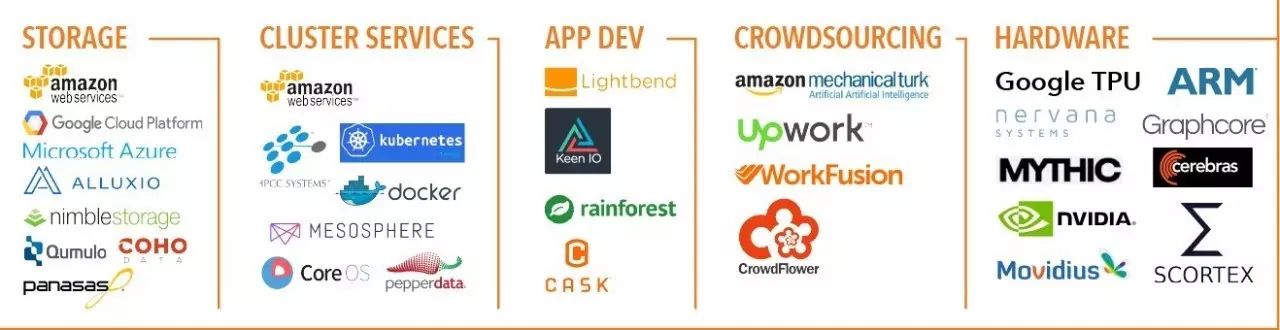
附录2. 2017年大数据全景分块放大版


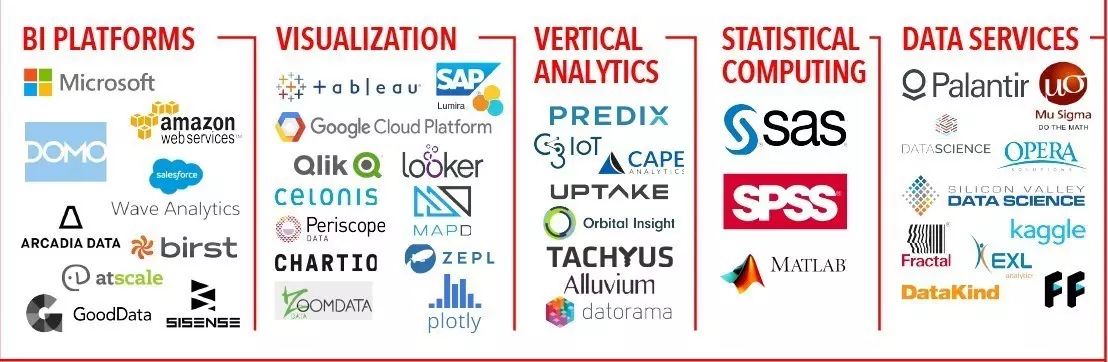




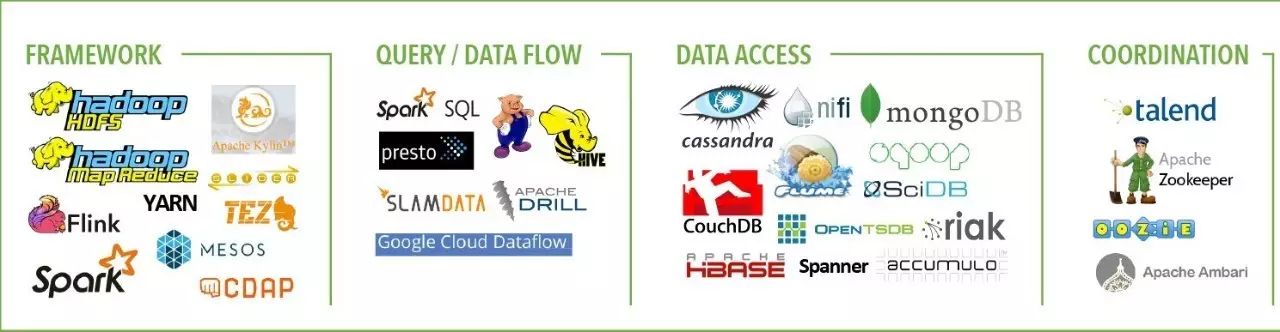
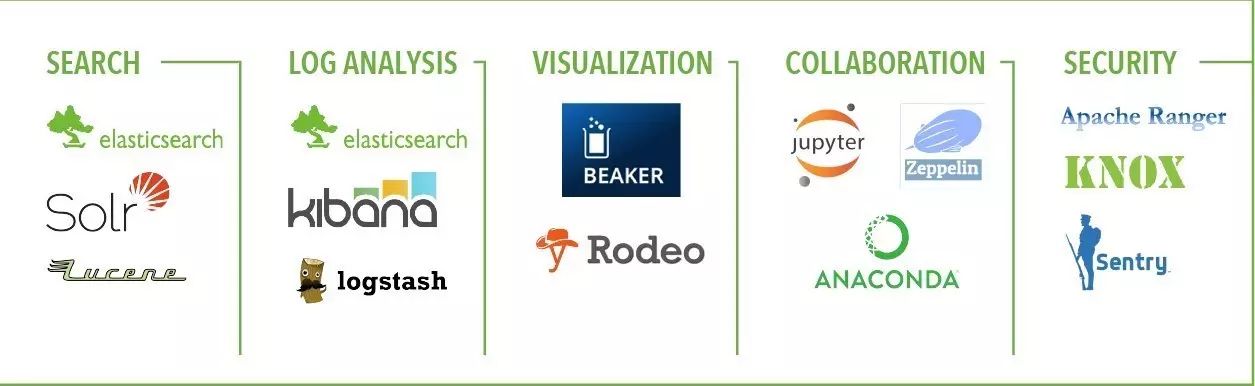
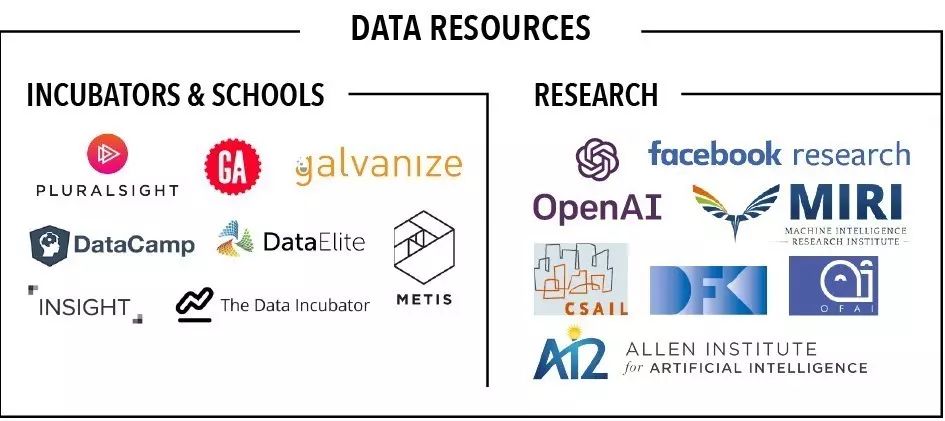













作者简介

Matt Turck,FirstMark投资创始合伙人。
在FirstMark之前,他是彭博投资的董事总经理以并帮助启动彭博资讯孵化器。Matt是TripleHop技术创始人之一,TripleHop是由风险投资支持的企业搜索软件公司,后被Oracle收购。
Matt热衷于社区建设,并组织每月两大事件:数据驱动的纽约(侧重于数据驱动的初创公司和大数据)和硬纽约(其中重点的东西,互联网,3D打印,和可穿戴计算)。
Matt毕业于巴黎科学院,并持有耶鲁大学法学院法学硕士学位(硕士学位)。










