引言
随着信息科技的在人类生活中的不断渗透,数据规模和计算规模也与日俱增
,某些
问题已经无法在单机系统上进行处理
,
只能寻求分布式系统的解决方案。
分布式系统用多个设备来处理特定问题
,
但是如何保证这样的处理结果像单机系统那样
正确?
这里的
正确
指的是:以相同的顺序进行相同的一系列操作,分布式系统能得到和单机系统相同的结果。
概要
本文主要介绍了分布式系统中 Linearizability 概念
,
以及它与 Serializability 的区别
,
并介绍了 Spanner 中是如何通过 TrueTime 来实现 Linearizability。
Linearizability 的概念
如果一系列的操作并发交叉进行,最终形成的 history(可以理解为运行记录)与顺序执行这些操作形成的 sequential history 相同,而且这些操作的先后顺序仍然得到保留,那么这个 history 我们就称之为是 Linearizability 的 [1]。
我们假设现在有一个寄存器,具有 W 和 R 两个操作,比如 W(0)A 表示进程 A 往寄存器写入 0 这个值,R(0)B 表示进程 B 从寄存器读到 0 这个值。
现实中,操作从开始到结束是具有时延的,我们用 start[W(0)] 表示发起操作,end[W(0)] 表示请求结束。
假设现在有如下图所示的场景一:
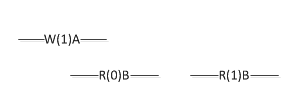
该场景共有三个操作:
-
A 进程执行 W(1);
-
操作 1 进行的过程中, B 读取到 0 这个值, 用 R(0) 表示;
-
操作 1 和操作 2 都结束后, B 进程再次读取, 得到了 1 这个值, 用 R(1) 表示。
注意这三个操作中隐含的先后顺序:操作 1 先于操作 3,操作 2 先于操作 3。
这个并发执行的场景对应的 history 如下:
start[W(1)]A
start[R(0)]B
end[W(1)]A
end[R(0)]B
start[R(1)]B
end[R(1)]B
这个 history 可以找到一个等价的 sequential history:
start[R(0)]B
end[R(0)]B
start[W(1)]A
end[W(1)]A
start[R(1)]B
end[R(1)]B
而且这个 sequential history 中仍然保持了操作 1 与操作 3,操作 2 与操作 3 的先后顺序。
因此场景一可以认为是 Linearizability 的。
再看如下的场景二,该场景并不满足 linearizable 的限制:

在这个场景中,当 B 执行 W(1) 的同时,A 已经读取到了 1 这个值,之后 C 执行 W(0),再之后 B 读取这个值,竟然还读取到 1 这个值。
分布式系统中,如果可以按照操作发生的先后顺序,构造一个 Linearizability 的运行记录,那么这个特性就称之为的 Linearizability。
举例来说,假设现在有一个全球部署的分布式存储系统,
先后
发生以下 4 个操作:
a. x = 1, 在中国发生
b. read x, 在美国发生
c. x = 2, 在日本发生
d. read x, 在美国发生
按照直觉来想, 操作 b 读取到的 x 值肯定是 1, 操作 d 读取到的 x 值肯定是 2。但这一切都是建立在系统能够感知这些操作的先后顺序之上, 比如在操作 b 中, 坐落于美国的 server 可以意识到操作 a 已经先发生。
但是在现实的分布式场景中, 我们的系统并不能像上帝一样, 可以清楚的知道世界各角落中, 每个操作的先后顺序, 除非我们为每一个操作都标记上统一的单调递增的 id, 这个 id 的功能一般由 timestamp 来充当。
但是对于 Spanner[2] 这样全球部署或者跨地域部署的系统, 如何来为事务分配 timestamp, 才能保证系统的响应时间在可接受的范围内? 如果整个系统采用一个中心节点来分配 timestamp, 那么系统的响应时间就变得非常不可控, 对于离中心节点隔了半圈地球的用户来说, 响应时间估计会是 100ms 级别。
所以, 本文会着重介绍 Spanner 分配 timestamp 的原理, 也即是 TrueTime API。
Linearizability 与 Serializability
需要注意的是 Linearizability 其实是无关于并发控制的, 它只是关于操作顺序的一种限制。与 Linearizability 很容易混淆的一个术语是 Serializability, 这个特性才是关于并发控制的一个限制。
如果一个系统可以将并发的
事务
按照某种调度,达到的效果和某种串行执行的效果一样(也就是各事务的操作不会相互交错),那么这个特性就叫 Serializability。
Serializability 着重于保证编程模型中的一些约束, 这些约束大部分是人为规定的. MySQL 的默认 RR 隔离级别是没有保证 Serializability, 因为 RR 并不能防止 Lost Update 和 Write Skew 的发生, 这两种情况都会破坏一些约束, 具体请参考 Weak Isolation in Relational Databases[4]。
对于单机数据库系统,单机数据库系统维持一个统一的、递增的事务 id 是轻而易举的事情, 所以可以认为它们天生就是具有 Linearizability 特性。另外有些数据库系统, 比如 MySQL 所支持的 Serializable 隔离级别便是本文所说的 Serializability 的特性。
所以, 我们可以看到所谓的 Serializability 便是 ACID 中的 I, 至于 Linearizability, 是针对于分布式系统而言的一个难点。
Linearizability 的意义
现在的数据库系统, 都具有 Snapshot read 的概念, 所谓 Snapshot read 指的是对于系统的读操作, 只是过去某一时刻的一个快照, 也就是对应于该事务 id 所能看到的一份历史数据, 在 Spanner 的场景来说, 也就一个指定的 timestamp 所能看到的一份历史数据。
如果一个分布式系统能够对"历史"有所感知的话, 也就意味着能够感知操作的前后顺序, 也就是说这个系统支持 Linearizability。
如果一个分布式系统无法支持 Linearizability, 那么对于指定一个 timestamp 所能看到的历史数据, 每次可能是不一样。
举例来说, 假设现在有一个全球部署的分布式存储系统,
先后
发生以下3个操作:
a. x = 1, 分配的 timestamp 为 s1
b. 指定 timestamp s2 执行 read x
c. x = 2, 分配的 timestamp 为 s3
d. 指定同一个 timestamp s2 执行 read x
假设 s2 > tabs(a),意思是 s2 是在操作 a 之后一个 timestamp,按照直觉来想, 肯定满足 s2 > s1 的关系式, 但是对于不支持 Linearizability 的系统来说, 可能存在 s2 < s1, 导致操作 b 这个 Snapshot read 无法看到 a 操作的结果。
类似, 还假设 s2 < tabs(c), 但是可能存在 s2 > s3, 导致操作 d 这个 Snapshot read 看到了 c 操作的结果。
注意, 操作 b 和 d 的都指定同一个 timestamp = s2 进行 Snapshot read,但是 b 和 d 看到的历史数据却是不一样的, 也就是说, 对于同一个 timestamp 对应的快照竟然不一样。
到这里可以看出来, 不支持 Linearizability 的分布式系统, Snapshot read 便无从谈起, Snapshot Isolation 也就是不可能的事情。
有些系统实现了"部分顺序", 也就是在单个节点(或者说单个分区)内的 Linearizability, 也就是能做到单机 Snapshot, 但是没有全局的 Snapshot。
实现 Linearizability 的难点
从上述描述中, 可以看到, 实现 Linearizability 首先需要对系统中每个事务分配一个统一的、单调递增的 id, 一般来说是 timestamp。那么, 在分布式系统中, 如何协调这个 timestamp 呢?
对于这个问题, 我们可能会很迅速的想到一个方案:引入一个专门生成 timestamp 的中心节点, 每次事务提交时, 访问该中心节点来获得 timestamp。TiDB 使用的便是这种方案, 它利用 TimeStamp Oracle 模块来提供授时服务。
但是这种方案引入了中心节点, 也意味着整套系统的部署不可能在地理位置上过于分散, 否则事务延时将会令人难以忍受。
需要指出的是,逻辑时钟(比如 Lamport 时钟和 Vector 时钟)无法实现 Linearizability, 因为它只能区分有"因果关系(也就是有通信)"的事件间的顺序。所以, 类似于" 事务 T2 在事务 T1 提交后才开始提交"这样的场景, 当节点间没有发生通信时,逻辑时钟无法区分这两个事务的顺序。
本文着重讲解 Spanner 是如何在这种全球部署的分布式系统中, 保证 Linearizability 的。在全球分布式系统中,真实世界里两个事务, 先后在不同的地方 commit, 系统怎样去如实反映事务的 commit 顺序?
首先我们先了解下 Spanner 的特性和它的整体架构。
Spanner 简介
Spanner 是由 Google 公司设计开发的一套可扩展、高可用、可全球部署的分布式数据库系统,具有如下特性:
-
提供了基于 SQL 的查询接口, 使用强类型的 schema, 提供了类型 RDS 的体验;
-
一定程度上支持垂直 sharding, 用户可以通过 INTERLEAVE 语法定义相关的两个 table 的记录存放在同一个 spanserver,带来的好处是形成了数据的 Locality, 对于查询中的一些操作(比如 join, group by)可以进行下推[3];
-
可以自动对数据进行水平 sharding, 并对每个 shard 维护一定的数量的副本, 通过 Multi-Paxos 保证一致性, 这些副本可以分散在全球不同地域;
-
支持 Snapshot Isolation, 通过 2PL 保证多个并发事务的 Serializability。另外, 对于涉及多个 shard 的 xa 事务, 通过 2PC 保证 Serializability;
-
保证 External Consistency(等价于 Linearizability, 下文不再区分), 也就是说如果事务 T1 提交后, 事务 T2 才开始提交, 那么 T2 的 timestamp 一定大于 T1 的 timestamp。
整体架构
Spanner 是由一系列的 zone 组成, zone 是 Spanner 中的部署的单元, 一般会在某 datacenter 部署一个 zone, 但是也可以有多个 zone。数据副本就是存放在这一系列的 zone 中, zone 之间的物理距离越大, 数据的安全性越高。

-
universemaster:
是一个控制台, 监控universe里所有zone状态信息, 用于debug;
-
placement driver:
帮助维持特定副本数量,自动搬迁数据,实现负载均衡;
-
zonemaster:
管理 spanserver 上的数据;
-
location proxy:
作用不详, 可能是为 client 提供数据的位置信息, client 要先访问它来定位需要访问的 spanserver;
-
spanserver:
对 client 提供服务, 包括读写数据。
Spanserver 架构

每个 spanserver 负责管理 100 ~ 1000 个 tablet。
一个 tablet 是维护某个表的一部分数据, 比如一个表有 10,000 行数据, 分成 100 个 tablet, 那么第 1 个 tablet 维护第 1 ~ 100 行数据, 第 2 个 tablet 维护第 101 ~ 200 行数据。
tablet 维护的数据是一系列的 KV:
(key, timestamp) ---> value 。
可以看出, Spanner 的 KV 数据是和 timestamp 绑定的, 所以自然就是支持 multi-version。
为了支持数据复制, spanserver 在每个 tablet 上层实现了 paxos group, 这个 group 中 replica 分布在不同的 zone 中。
每个 leader replica 还维护了一个 lock table, 也就是一系列的 KV:
key--->lock-states。
lock-states 指的是对应的数据在2PL过程中的锁状态。
spanserver 在每个 leader replica 上都实现了 transaction manager, 这个模块是用来支持分布式事务的。
如果事务涉及到多个 paxos group, 那么每个 leader replica 此时就是 participant leader 的身份, 其中一个 participant group 会被 client 选作 coordinator, 通过 2PC 的方式来实现 Serializability。
如果事务只涉及一个 paxos group, 那么 transaction manager 的功能可以被忽略, 只依赖 lock table 就可以实现 Serializability。
事务 commit 的过程
简单的实现(但是有问题)
现在假设让我们来实现事务的 commit 过程, 有一种简单的方法如下图所示, 这种方法简单的从 local clock 分配 timestamp 给事务:
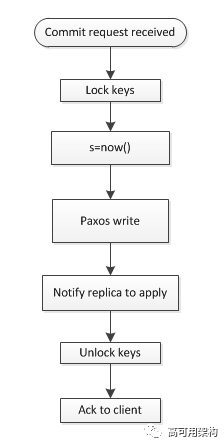
假设现在有先后两个事务 T1 和 T2, 分别在不同的 spanserver 上执行, T2 在 T1 提交后, 才开始提交, 使用这个方法会导致真实世界中后提交的 trx 反而具有较小的 timestamp。










