前面有一篇文章形象解析了Yarn的工作原理,这一篇文章通俗解析一下当前最火的大数据框架Spark。
通俗说基于Yarn的Map-Reduce过程
听说过Spark 的人常听到他强于Hadoop 的原因是他是基于内存的计算,因而比Hadoop快,可是数据量如此之大,怎么可能都放在内存里面呢?
当然不是所有的都在内存里面,Spark比hadoop快而是由Spark全新的运行机制决定的。
一提Spark 的大数据处理能力,有一个抽象的概念叫RDD,其实用户可以逻辑地认为数据全在内存中,仅仅关注数据处理的逻辑即可,这有点像客户提的需求,往往是抽象的,需要在实现的过程中慢慢的落地。(这里接着延续通俗说Yarn里面接项目的模式)
客户开始口若悬河的描述他们想怎么处理这些数据,例如每个都加一(map),过滤掉一些(filter),合并一下(union),按照key做个汇总(reduceByKey),最后处理完了,写入HDFS。
好了,你作为需求分析师开始记录客户想要做的改进,一一记下来,最后形成了一张如下的有向无环图。
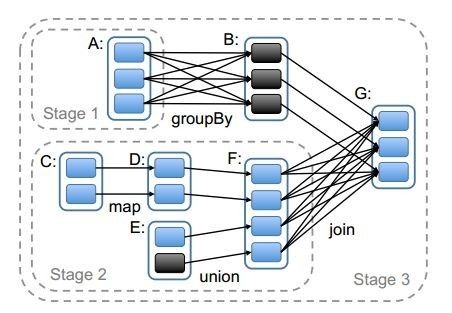
好了,接到需求了,开始干吧!等等,咱们统筹规划一下,先别着急动手。
这是Spark和hadoop编程模型不同的地方,上述的所有的操作,map-reduce看到一条就做一条,例如每个都加一,构成一个map-reduce,读一次磁盘,写一次磁盘,同理过滤,构成另一个map-reduce,以此类推,所以整个处理过程比较慢。
Spark当看到一个需求的时候,判断这是一个中间状态的转换(Transformation),还是客户要的最后结果,如果是中间状态,则等等看,如果是客户要结果了,才开始真正的行动(Action)。
当要行动的时候,客户的需求已经完全清楚了,可以统筹规划。
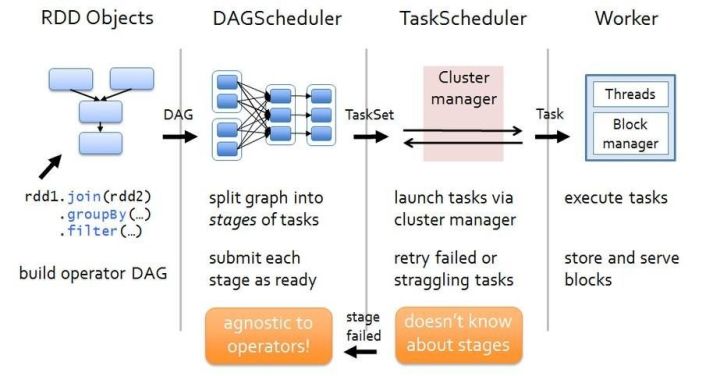
这个做统筹规划的人叫DAGScheduler,他不真正的执行任务,也不调度任务的执行,既不是程序员,也不是项目经理,而是需求分析师,给出来的常称为High Level Design。
DAGScheduler中的DAG是Directed Acyclic Graph,有向无环图,他讲客户的需求画成一个图,这样看起来清晰多了,然后从最后客户想要的结果入手进行分析。
客户想要的结果肯定是最后一步finalStage,然后看要得到这个结果的上一步的数据是什么,因为数据量很大,就像上一次讲Yarn一样,需要分成多个团队并行处理,但是有时候并行不起来,还需要汇总一下结果,在Spark里面也是这样的,如果上一步的数据到这一步子团队内部就能搞定,就不需要开会汇总,互相交换资源,例如上一步的数据是每个省的高考分数,这一步要求得到每个省的最高分数,这样自己省里面自己就能搞定,这叫做窄依赖,可以在一个Stage里面搞定,这就是Spark比较好的一个模式,只要是窄依赖,不需要启动另外的map-reducce,在一个子团队一直做,如果每个子团队处理数据量不大,就不用落盘,直到需要汇总的那个时候。
什么时候需要汇总呢?例如上一步是每个省的高考分数,这一步求全国的文科和理科状元,这样一个省内就搞不定了,需要大家开会汇总,每个省将自己的文科状元和理科状元报上来,分别在理科处理子团队和文科处理子团队进行排序处理,这个过程各个省之间的数据需要交换,因而这个过程往往成为数据处理的瓶颈,称为宽依赖,宽依赖会将处理过程分成两个Stage,因为一个子团队内部搞不定了,需要人统筹开会,交换资源,这个过程叫做shuffle,专门组织会议,统筹这件事情的叫做shuffleManager
就是按照这种思路,DAGScheduler从最后的输出结果往前推,凡是窄依赖的算作一个Stage,凡是宽依赖的算作另外的Stage,于是将整个处理的图划分为多个Stage,规划阶段就算可以了。
接下来是要执行了。DAGScheduler会创建一个Job,对于每一个Stage,因为Stage内部都是窄依赖,因而可以分成多个团队并行处理的,当一个Stage处理完毕,进入下一个Stage的时候,会进行一次Shuffle,也即集中开会交换数据,然后下一个Stage同样多个团队并行处理,直到输出结果。





