强关联多体问题是凝聚态物理中最为困难也是最为重要的问题。这其中有强相互作用的费米子体系一直是人们关注的焦点之一,这些体系中蕴含着如高温超导、分数霍尔效应等等极为重要的物理现象。在强关联体系中,粒子(电子,自旋)间的相互作用不可忽略,传统的基于平均场思想(将关注的粒子以外的所有粒子近似为背景场)的处理方法在这类体系中不再如此有效。这其中很重要的原因就是量子纠缠的存在。双自旋组成的自旋单态就是一个简单的例子,它无法用两个单自旋波函数的直积来描述,因为它是一个纠缠态。正是这个原因,平均场类的处理方法很难描述强关联体系中的纠缠。因此,人们迫切需要新的数值方法来处理这类问题。
将体系的哈密顿矩阵对角化,这种严格求解的方法是处理强关联问题的有效途径之一。然而众所周知的指数墙问题使得严格对角化方法的应用被局限在相对较小的体系中。几十个格点组成的体系由于有限尺寸效应,其表现出来的性质往往与人们想要的热力学极限下体系的性质有不少差距,这是严格对角化方法处理强关联体系的局限。
量子蒙特卡罗(quantum Monte Carlo)方法是一种非常强大有效的数值模拟方法,它通过随机采样来精确模拟体系的配分函数,在对许多的强关联模型(尤其是量子自旋模型,玻色体系)的研究中取得了非常好的结果。遗憾的是量子蒙特卡罗方法受到“符号”问题的困扰,也就是说,如果随机采样过程中权重出现负数,则其误差迅速增大,结果也变得不再可信了。而费米子体系中,费米子的交换就会带来符号问题,因此量子蒙特卡罗方法在此有严重的局限性。可喜的是伴随着量子蒙特卡罗的发展,目前在许多强关联电子体系的研究中(比如半满状态下的Hubbard 模型),人们发现了可以有效回避符号问题的方法。但是这类办法目前仍是有一定的局限性的。
如果人们对所研究体系的基态性质有一些合理的猜测,那么我们也可以先构建出波函数的基本形式,然后通过能量最小化的变分方法来定出波函数的具体参数。这类变分方法历史悠久,也有各种不同的形式,在强关联体系的研究中也是一类重要的手段。但是传统变分法的缺点也非常明显,那就是它带有偏见,有人为的假设在暗含其中,失去了公正性与普适性。这样的代价是当我们研究未知的体系,或者有多种物相激烈竞争的临界现象,变分法很难给我们明确的答案(当然对这类体系的研究本身就是非常困难的问题)。
以上就是处理强关联(费米)体系的常用数值手段。可以看到,它们都有着严重的局限性。在近十多年来迅猛发展起来的一类新的数值方法逐渐成为了数值模拟研究强关联问题的主流方法。这一大类算法有各种各样不同的变种,它们的具体操作甚至出发点都不尽相同,但其背后都有着共同的基础,那就是矩阵乘积态思想(matrix product state ansatz,MPS)。简单地说,就是用一系列矩阵的乘积态来描述体系的波函数,而矩阵的元素就是我们的参数。矩阵可以很好的描述量子纠缠,比如说前面说到的自旋单态就可以很简单的用一个2×2 的矩阵来描述;同时这样构建的波函数带有普适性,没有输入人为的猜测,因此MPS类方法非常适合用来研究存在着大量量子纠缠的强关联体系。MPS方法最成功例子就是密度矩阵重整化群方法(density matrix renormalization group,DMRG),这类方法在对一维(以及一些二维)的强关联体系的研究中都取得了很好的结果,尤其在一维,它是目前精度最高的数值方法。
在二维或更高维体系中,MPS类方法很自然的推广到张量矩阵乘积态(tensor product state,TPS)或称张量矩阵网络态(tensor network,TN)。与MPS类似,我们用矩阵为元素来构建波函数,只是在二维或高维中,每个矩阵往往需要与多个相邻矩阵连接,因此构成了一个网络,而其本身也变成了张量。由于其网络型结构,在描述二维以上体系的纠缠上,TPS 天生比MPS具有更大的优势,能更好的满足纠缠熵的面积定理。但是同时其相对复杂的网络也带来了计算量的提升。在相同计算量的情况下,MPS类方法保留的虚拟维度(越大则越精确)通常要比TPS类方法大1 到2 个数量级。因此在较小体系或是准二维体系的模拟中,TPS 类方法在现有计算机能力的限定下,就优化所得的基态能量来说,对比MPS类方法并没有明显的优势。但是我们相信,对于真正的大尺度二维体系性质的研究,TPS 类方法是未来发展的趋势。目前已经有多种发展成熟的TPS类计算方法,如PEPS(projected entanglement pair states),TERG(tensor entanglement renormalization group),MERA(multi-scale entanglement renormalizationansatz),等等。它们的出发点,优化方式和原理,计算技巧等等都各不相同,也有各自的优缺点。笔者在这里仅对自己熟悉的MERA方法进行简单的介绍。
从其英文名就可知道,MERA方法用到了重整化的思想,其网络结构也类似于一棵倒过来的树,又称树状张量矩阵网络(tree tensor network,TTN)。这与一般的TPS 类方法很不相同, 如PEPS方法,其所有的矩阵都在原有体系格点的位置上,因此研究二维模型的PEPS 张量网络也是二维的;但MERA 方法额外引进了重整化的尺度,所以形成了树状结构。在TTN中,每一层张量矩阵所起的作用类似于粗粒化(coarse graining)的过程,随着层数的增加,我们从张量矩阵所得到的波函数所包含的信息就是粗粒化之后体系在更大尺度所表现出来的性质。但是TTN 类方法在二维或更高维有很大的局限性,那就是面积定理要求TTN 矩阵所保留的虚拟维度随着重整化尺度的增加而指数增加,否则其精度就会迅速下降。为了解决/缓解这一问题,MERA 方法的提出者G.Vidal 与G. Evenbly 提出了在网络中加入一种新的张量矩阵:disentangler 的想法。引入disentangler 的目的是去纠缠,即减少/削弱体系的在短程的纠缠,以帮助重整化的张量矩阵(isometry)能够更好的描写体系中重要的长程纠缠,以更少的代价(矩阵的虚拟尺度,等效于计算量)来更好的描写强关联体系的性质。图1 中给出了一张一维MERA 的简单示意图,其中方形矩阵是去纠缠子,而三角型矩阵代表的是重整化子。
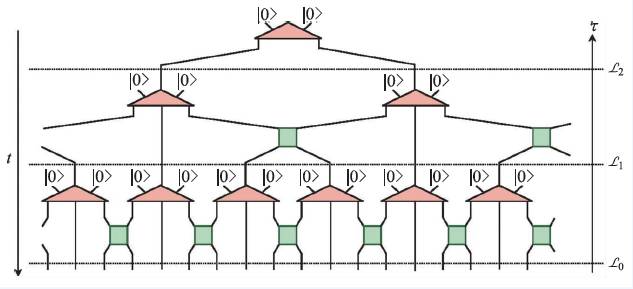
图1 一维MERA的张量网络的简易示意图。其中绿色方形代表去纠缠子(disentangler),负责去纠缠化,红色三角形代表重整化子(isometry),负责重整化/粗粒化。该图中有三种不同的尺度,从下到上不断增大,图摘自文献
TPS 类方法目前已经有了许多成功的应用,其中主要的研究结果是对带阻挫的量子自旋模型的研究(寻找量子自旋液体),以及对一些有拓扑性质的模型的模拟,等等。这其中MERA方法与其他TPS 类方法相比,有以下特点:通过多层重整化能研究较大的体系,属于严格的变分方法,没有采取做截断的近似,能够灵活处理各种边界条件,等等;其缺点是树状的网络结构会一定程度上干扰体系原有的平移对称性。关于MERA方法中张量矩阵的具体优化方法以及其他技术细节,笔者就不在此赘述,感兴趣的读者可以阅读参阅文献。
MPS/TPS 类方法是研究强关联体系的非常有效的新手段,但是在推广到费米子体系中时,我们仍需要克服一个小小的困难,那就是费米子与玻色子截然不同的统计性质。费米算符是反对易的,交换一对费米算符会得到额外的-1 因子。为了正确的描述费米子的这种统计性质,常用的处理方法是Jordan—Wigner 变换,即人为引进粒子的排序,然后利用一条由计数算符(number operator)组成的算符链将费米算符转化为玻色算符(也可反向进行):
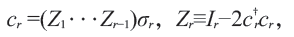
如此一来,我们又可以用熟悉的处理玻色/自旋体系的数值方法模拟费米体系了。这种处理方法很好的从算法层面解决了MPS类方法处理费米体系的问题。
但是对于TPS 类方法,这个问题要复杂不少。因为Jordan—Wigner 变换引入了一串算符,那么这些算符都需要和网络中的其他张量做缩并(张量矩阵的缩并是我们优化矩阵,以及求解波函数,测量物理量的必要工序),这就大大增加了计算的复杂程度。很快P. Corboz,G. Vidal 等人找到了一个巧妙的办法解决了这个问题。他们把张量网络(双层或多层)投影到一张纸上,于是矩阵与矩阵之间的连接线不可避免的会相交,而两条连接线的交点正意味着一对费米算符的交换。这些交点可以通过类似电路简化的方法移动、重排,并最终被矩阵所吸收。这之后所得到的张量矩阵中已经包含了费米算符交换的信息,而剩下的张量网络与玻色网络并没有什么区别,又能够用我们熟悉的方法处理了。
对于张量网络结构比较简单的数值算法(如PEPS),这种方法非常有效,但是对于MERA这种多层网络结构的算法来说就要更加麻烦一些。如果将这种复杂网络投影到一张纸上,则其矩阵连线的交点密密麻麻,想要通过手动来对其进行简化极其费时费力。实际上,如果想要研究更高维度的晶格(比如面心立方(FCC)),即使用PEPS类方法也会遇到类似的问题。更糟糕的是,如果我们改变张量网络的结构,则上述步骤又要推倒重来,从头开始。可以看到上述方法其本质还是用到了全局排序的思想,因此是一个全局性的复杂问题。那么有没有办法进一步将这个问题简化呢?
顾正澄等提出的将Grasmann 代数与张量网络相结合的办法很好的解决了这个问题。Grassmann 代数是场论中常用的一套数学工具,能非常有效的处理费米子统计问题,其最大的特点是,通过局域的Grassmann 代数(以下简称G数)操作就可以得到费米统计的性质。将Grassmann代数与张量网络方法结合后,我们只需要在两个局域矩阵做缩并时,对相关的G数进行操作,就能得到正确的费米统计,这大大简化了我们的程序,也使得计算更加简便,有效。这种思想可以运用推广到各种TPS 类算法中,得到GPEPS,GTERG以及笔者主要研究的GMERA算法。
GTPS 类算法其实非常容易理解。我们现在给张量矩阵的每个角标(连接)的每个自由度都赋予一个G数(图2)。这个自由度可以满足费米统计(我们叫它费米通道),也可以满足玻色统计(玻色通道),它所对应的G 数的指数分别为1 或者0。指数为1 的G数之间满足费米算符的反对易关系(0 则满足玻色对易关系)。这些G数必须在矩阵缩并的过程中通过Grassmann 积分消去。以图2 为例,我们要对角标i 进行缩并,相应的G 数G
a
,G
b
就是我们要积去的目标。而积分的前提准备是将一系列G数重排,将G
a
与G
b
移动至所有角标的最前端(当我们写下一个矩阵的角标时,总是有一定顺序的,而现在就是要改变这个顺序)。这个过程当中就会发生G数的交换,这也就是实现了费米统计的关键。可以看到在张量缩并的过程中,每次我们都只需要考察两个待缩并矩阵,与其它矩阵无关;而张量网络的计算主要就是通过矩阵的缩并完成的!因此利用GTPS 算法后,原来复杂的全局性费米统计问题转化为了简单的局域化问题,这使得该方法非常的简单、普适、高效。从另一个角度思考的话,我们可以认为,原来是费米统计性质的那些通道,在被配以G数以后,满足的是玻色算符的对易关系。因此此时所有的张量矩阵都可以视为满足玻色统计,因此我们在对矩阵网络进行缩并和计算的过程中,可以自由决定缩并结合的顺序,而不再用担心全局性的排序问题。这就是引入Grassmann代数带来的巨大优势。
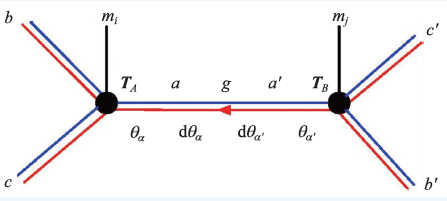
图2 GTPS 原理的简易说明图。张量矩阵角标上的每一个自由度被赋予了Grassmann 数θ(以下用G代替),而两个张量角标的连接上被赋予dθ。在做矩阵缩并时,我们需要将两者移动至一处并配对,才可通过积分将它们消去。在这个过程中必然会发生G数顺序的交换,实现费米统计。图中T 为张量矩阵,a-c,a'-c'为矩阵角标。红蓝两色表征角标的自由度可以是费米或玻色性质的
当然要在结构复杂的张量网络中引入Grassmann代数并非如此简单,一个可能遇到的问题就是,在缩并的过程中,可能会出现一些有特别多角标/连接的大型张量矩阵。此时G数的重排也会浪费大量的计算时间。对此,我们采用了预排序和存储符号矩阵的方式来解决这一困难,这里就不再展开了。由此得到的数值算法,其计算速度与玻色系统的模拟(当保留相同的虚拟维度时)是基本一样的。而且这种算法可以自由应用到各种不同结构的晶格模型或者张量网络中,无需再对程序进行针对性的修改。因此我们得到了一个非常普适、高效、严格的模拟强关联费米子体系的数值方法。
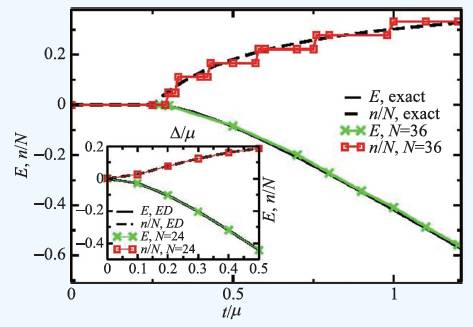
图3 (外)正方晶格的紧束缚模型与(内)六角晶格上的自由费米子模型的计算结果(绿色曲线为基态能量,红色曲线代表填充。对紧束缚模型,黑色曲线为严格解析解。对自由费米子模型,黑色曲线为严格对角化结果。图中exact 为精确解/解析解,纵坐标中E 是模型中相互作用强度J 的单位,n/N是载流子填充率,单位为百分比)
我们对GMERA 方法进行了大量的验证,也进行了一系列的benchmark计算。以六角晶格上的自由费米子模型(只有配对相互作用)及正方晶格上的紧束缚模型(只有跃迁项,有严格解)为例(图3),我们得到的结果都与预期的相符。它们的哈密顿分别写为:
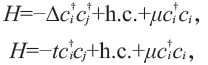
其中需要特别指出的是,对于GMERA方法(或者说GTPS 类方法),我们所描述的体系处于巨正则系综,也就是说粒子数通过调节化学势是连续可变的。这与固定粒子填充数的DMRG算法有些不同,因此对于研究会发生配对自发对称破缺的超导模型有自己的优势。结果如图3 所示,在紧束缚模型中,在调节化学势时,我们得到的是一个个费米子填充的整数(偶数)平台。这是因为紧束缚模型中粒子数是守恒的,而费米子与玻色子不同之处在于其每个能级只能填充一个粒子,且满足宇称守恒(粒子成对产生湮灭),因此在有限大小的体系中,其填充数必定呈现出平台的形式。我们也模拟了类似形式的硬核玻色子模型,所得到的填充数—化学势图就是一条连续平滑的曲线。因此整数平台的出现意味着GMERA算法正确的抓住了费米统计的性质。与之相对的,在只有配对相互作用的自由费米子模型中(图4 内嵌),填充数是连续演化的。这是因为配对相互作用导致体系基态波函数是不同(偶数)填充数状态的叠加,因此总填充粒子数可以表现为非整数。









