选自venturebeat
作者:MARIYA YAO, TOPBOTS
机器之心编译
深度学习较其他机器学习方法在各类任务中都表现优异,各个机构或院校也花了巨大的精力和时间投入到深度学习,并取得了令人惊叹的成就。但深度学习近来也暴露出其内在缺陷,很多学界领军人物都在积极探讨解决办法和替代方案。因此本文力图阐述深度学习的局限性,引发更多对深度学习的思考。
人工智能已经达到了炒作的顶峰。新闻报告称有的公司已经使用 IBM Watson 取代了工人、算法在诊断上击败了职业医生。每天都会有新的人工智能创业公司出现,宣称能使用机器学习取代你的私人和商业难题。
榨汁机、Wi-Fi 路由器这样普通的物品也忽然宣称是「由人工智能驱动」。智能的站立式桌子不仅能记住你调节的高度,也能为你点餐。
许多有关人工智能的喧哗都由那些从未训练过神经网络的记者,创业公司或者从未真正解决过商业难题却想要被高价聘请的编程人才所发出的。所以,有关人工智能的能力与限制,难免有如此多的误解。
深度学习无疑使人兴奋
神经网络创造于上世纪 60 年代,但近年来大数据和计算能力的增加使得它们在实际上变得有用。于是,一种名为「深度学习」的新的学科出现,它能使用复杂的神经网络架构以前所未有的准确率建模数据中的模式。
结果无疑使人惊讶。计算机如今能比人类更好地识别图像和视频中的物体以及将语音转录为文本。谷歌就用神经网络取代了谷歌翻译的架构,如今机器翻译的水平已经很接近人类了。
深度学习在实际应用中也令人兴奋。计算机能够比 USDA 更好的预测农作物产量,比医师更准确的诊断癌症。DARPA 的主任 John Launchbury 曾这样描述人工智能的三个浪潮:
-
像 IBM 的深蓝或 Watson 这样的人工编码知识或专家系统;
-
统计学习,包括机器学习与深度学习;
-
环境自适应,涉及到使用稀疏数据为真实的世界现象构建可靠的、可解释的模型,就像人类一样。
作为目前人工智能浪潮的第二波,深度学习算法因为 Launchbury 所说的「流形假设(manifold hypothesis)」(见下图)而更加有效。简单解释,它指代不同类型的高维自然数据如何聚成一块,并在低维可视化中有不同的形状。
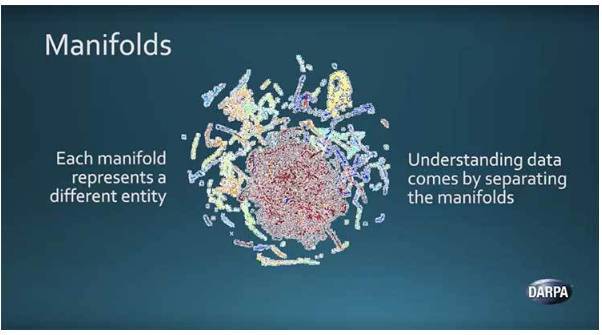
通过数学运算并分割数据块,深度神经网络能区分不同的数据类型。虽然神经网络能够取得精妙的分类与预测能力,它们基本上还是 Launchbury 所说的「spreadsheets on steroids」。

深度学习也有深度难题
在最近的 AI By The Bay 大会上,Francois Chollet 强调深度学习是比以前的统计学和机器学习方法更为强大的模式识别方法。「人工智能如今最重要的问题是抽象和推理,」Google 的人工智能研究员 Chollet 解释到,他是著名的深层学习库 Keras 的构建者。他说:「目前的监督感知和强化学习算法需要大量的数据,在长远规划中是很难实现的,这些算法只能做简单的模式识别。」
相比之下,人类「从很少的案例中学习,可以进行长远规划,他们能够形成一种情境的抽象模型,并 [操纵] 这些模型实现极致的泛化。
即使是简单的人类行为,也很难教授给深度学习算法。例如我们需要学习在路上避免被汽车撞上,如果使用监督学习,那就需要巨量的汽车情境数据集,且明确标注了动作(如「停止」或「移动」),然后你需要训练一个神经网络来学习映射不同的情况和对应的行动。
如果采用强化学习,那你需要给算法一个目标,让它独立地确定理想的行动。为学习到在不同情况下躲避汽车,计算机可能需要先被撞上千次。Chollet 警告说:「仅仅通过扩大今天的深度学习技术,我们无法实现通用智能。
躲避汽车,人类只需要告知一次就行。我们具有从简单少量的例子中概括出事物的能力,并且能够想象(即模拟)操作的后果。我们不需要失去生命或肢体,就能很快学会避免被车撞上。








