近日,南京大学计算机科学与技术系教授、MINIEYE 首席科学家吴建鑫所在团队的一篇论文《ThiNet: 一种用于深度神经网络压缩的滤波器级别剪枝算法》被计算机视觉领域顶级国际会议 ICCV 2017 收录。论文中提出了滤波器级别的剪枝优化算法,利用下一层的统计信息指导当前层的剪枝,能够在不改变原网络结构的前提下,让卷积神经网络模型在训练与预测阶段同时实现加速与压缩。ThiNet 框架具普适性,可无缝适配于现有的深度学习框架,有助于减少网络的参数与 FLOPs,同时保留原网络的精度级别。为此,机器之心对吴建鑫教授进行了采访,进一步解读 ThiNet 框架的设计思路以及背后的研究工作。
目前,参数冗余是神经网络领域公认的一个重要问题。如何在保持神经网络的精确度、迁移能力等各方面特性的基础上,减小神经网络模型参数的数目,也是学术界与工业界的热门研究方向。「由于网络模型过大的原因,很多情况下深度学习模型无法适用于终端用户的使用场景之中,例如 VGG 模型的硬盘空间就达到 500M 以上,应用场景也会受到相应的限制。所以,模型压缩对深度学的实际应用具有非常大的价值。」吴建鑫举例解释道。
除此之外,模型压缩在科研方面也具备较大的研究价值。在硬件资源普及之前,卷积神经网络并非计算机视觉领域的首选。吴建鑫回忆,在他学生时代参加学术会议时,曾与卷积神经网络之父 Yann LeCun 研究组的学生进行过交流。那时训练一个神经网络模型的代价非常高,有时甚至需要几个月的时间才能完成整个网络的训练及应用过程,那名学生还因此担心没有办法按时毕业。而随着 GPU、FPGA 等硬件计算资源与大数据资源的崛起,神经网络模型可以最大程度发挥作用,逐渐大放异彩。与此同时,业界有观点认为,快速发展硬件资源是解决神经网络问题的根本,针对模型压缩本身进行研究的科研意义不大。对此,吴建鑫持不同观点,他解释道,今年 CVPR 会议上,Uber 公司的研究人员提出的网络模型 UberNet 可以把识别、检测、分割等任务集中在一个模型里实现。不过,UberNet 对资源的消耗非常大,哪怕是在最新型 GPU 上进行单张图片的处理也需要搭配使用减少资源消耗方面的先进技术成果。「这个领域对资源消耗方面的索求速度将高于硬件发展的速度。新技术、新资源出现的同时也会带来新的问题,针对压缩网络进而降低资源消耗的研究应该齐头并进。」
压缩网络模型通常有两种思路:一是利用稀疏性对模型进行剪裁,从而达到减少模型参数数目的效果;二是由卷积神经网络的通道(channel)入手进行选择性取舍,去掉通道中的噪声或是可以被其他通道代替的部分,进而降低计算代价。ThiNet 框架的设计思路就是从通道选择的角度展开,提出了一种滤波器级别的剪枝算法,并将其定义为一个优化问题,结果在性能方面有较大的提升。据吴建鑫介绍,2014 年团队就曾针对基于熵的特征选择算法进行研究,结果发现相较模型压缩方法,在同压缩比的情况下具有更高的准确率,发表于 CVPR2015。在这个熵算法的基础上,团队在 2015 年底开始不断做出尝试和改进,最终设计出了效果更优的 ThiNet 框架。
在下图的 ThiNet 剪枝框架图中,先根据图中的虚线框部分判断哪些通道及其相对应的滤波器性能较弱(第一行中用黄色高亮的部分)或可以被其他通道代替。然后丢弃对网络的性能影响较小的通道及其对应的滤波器从而得到一个剪枝模型。之后再对剪枝后的模型进行微调以恢复其精度。
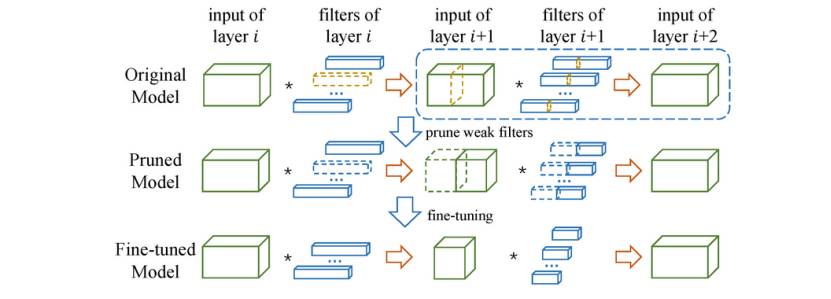
ThiNet 框架
ThiNet 框架的核心是通过上一层的统计信息来指导当前层的剪枝,这也是区别于其他现有模型压缩方法的亮点。以模型的第五层为例,在针对网络模型的第五层进行压缩时,为了尽可能不影响网络模型的效果,要尽量保持第五层的输出通道不变或改变较小。由于卷积层是一种线性算子,所以可以看成是用第五层的输入(即第四层的输出)模拟其输出的线性过程。在这里,第五层的输入是可以缩减的,如果可以通过优化方法找到第五层的输入中线性组合等于零的部分并将相应的第四层输出的卷积核舍弃掉,就可以利用较少的输入得到相似的输出,换言之,在不牺牲模型效果的前提下实现压缩模型。探索线性组合的值接近于零的具体过程涉及采样训练样本、贪心算法、最小化重构误差等优化方法。
在这之后的微调步骤对于恢复模型的精准度也相当重要,从实验数据可以看出 ThiNet 具有相当的鲁棒性能。
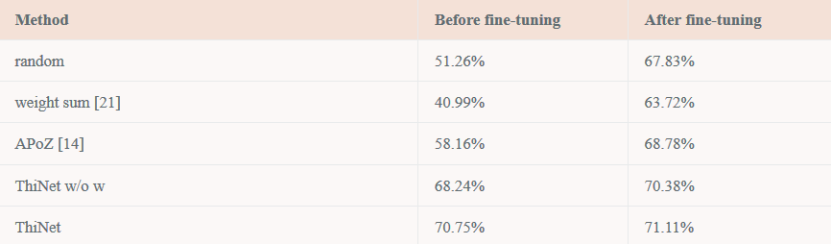
在 CUB-200 数据集上,微调前后的精度变化情况。
实验结果验证了 ThiNet 算法的有效性,其性能超过了现有的剪枝算法。
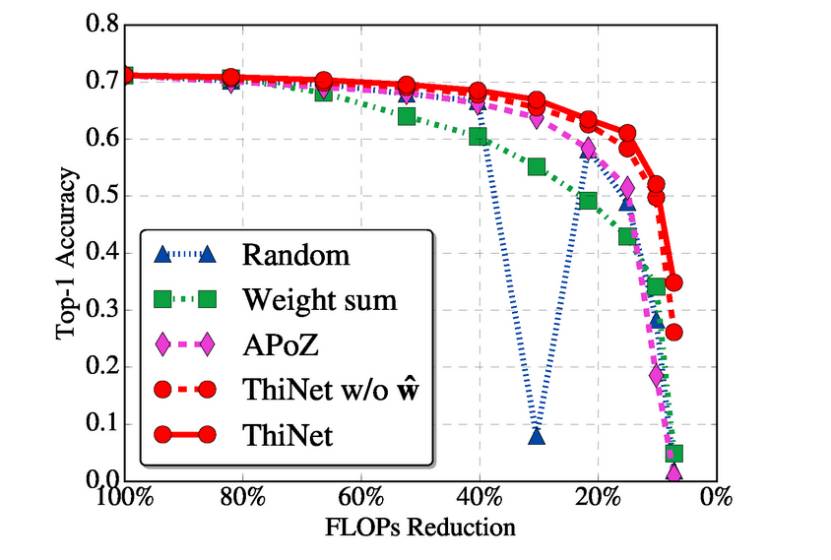
不同选择算法的性能比较:VGG-16-GAP 模型以不同的压缩率在 CUB-200 数据集上的剪枝效果。









