为了用python实现高效的数值计算,我们通常会使用函数库,比如NumPy,会把类似矩阵乘法这样的复杂运算使用其他外部语言实现。不幸的是,从外部计算切换回Python的每一个操作,仍然是一个很大的开销。如果你用GPU来进行外部计算,这样的开销会更大。用分布式的计算方式,也会花费更多的资源用来传输数据。
TensorFlow也把复杂的计算放在python之外完成,但是为了避免前面说的那些开销,它做了进一步完善。Tensorflow不单独地运行单一的复杂计算,而是让我们可以先用图描述一系列可交互的计算操作,然后全部一起在Python之外运行。(这样类似的运行方式,可以在不少的机器学习库中看到。)
使用TensorFlow之前,首先导入它:
import tensorflow as tf
我们通过操作符号变量来描述这些可交互的操作单元,可以用下面的方式创建一个:
x = tf.placeholder(tf.float32, [None, 784])
x
不是一个特定的值,而是一个占位符
placeholder
,我们在TensorFlow运行计算时输入这个值。我们希望能够输入任意数量的MNIST图像,每一张图展平成784维的向量。我们用2维的浮点数张量来表示这些图,这个张量的形状是
[None,784 ]
。(这里的
None
表示此张量的第一个维度可以是任何长度的。)
我们的模型也需要权重值和偏置量,当然我们可以把它们当做是另外的输入(使用占位符),但TensorFlow有一个更好的方法来表示它们:
Variable
。 一个
Variable
代表一个可修改的张量,存在在TensorFlow的用于描述交互性操作的图中。它们可以用于计算输入值,也可以在计算中被修改。对于各种机器学习应用,一般都会有模型参数,可以用
Variable
表示。
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
我们赋予
tf.Variable
不同的初值来创建不同的
Variable
:在这里,我们都用全为零的张量来初始化
W
和
b
。因为我们要学习
W
和
b
的值,它们的初值可以随意设置。
注意,
W
的维度是[784,10],因为我们想要用784维的图片向量乘以它以得到一个10维的证据值向量,每一位对应不同数字类。
b
的形状是[10],所以我们可以直接把它加到输出上面。
现在,我们可以实现我们的模型啦。只需要一行代码!
y = tf.nn.softmax(tf.matmul(x,W) + b)
首先,我们用
tf.matmul(X,W)
表示
x
乘以
W
,对应之前等式里面的
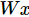 ,这里
,这里
x
是一个2维张量拥有多个输入。然后再加上
b
,把和输入到
tf.nn.softmax
函数里面。
至此,我们先用了几行简短的代码来设置变量,然后只用了一行代码来定义我们的模型。TensorFlow不仅仅可以使softmax回归模型计算变得特别简单,它也用这种非常灵活的方式来描述其他各种数值计算,从机器学习模型对物理学模拟仿真模型。一旦被定义好之后,我们的模型就可以在不同的设备上运行:计算机的CPU,GPU,甚至是手机!










