Less than 10% of the code has to do with the ostensible purpose of the system; the rest deals with input-output, data validation, data structure maintenance, and other housekeeping.
— Mary Shaw "Software Architecture"
偶然的两次,有人问我:“请问巴贝奇先生,如果将错误的数字输进机器里,它能得出正确的结果吗?” 我完全无法明白,思维何等混乱的人才能提得出这样的问题。 —— 查尔斯·巴贝奇, 《哲学家的生命旅程》
计算机领域有句大俗话,是:Garbage in, garbage out,垃圾进,垃圾出。如果将错误的,无意义的数据输入给一个系统,你也将会得到错误的结果。软件架构领域的先驱者 Mary Shaw 在她的《软件架构》一书里提到,一个系统只有 10% 的代码用于其看得见的目的,而剩下的逻辑都花在处理输入输出,数据校验,数据结构的维护和其它的琐事。这就如同漂浮在海面上的冰山一样,软件开发过程中隐藏的,任何系统都不得不做的事情占到了绝大多数:

如何让开发者把精力都用在有实际产出的业务逻辑上,所谓「好钢用在刀刃上」呢?水下的部分属于不得不做的部分 —— 业务逻辑做得再漂亮,系统没有足够的健壮性,不能容错,也无法捕获用户的芳心 —— 所以我们要将水下的部分尽可能地自动化:找出其中可以生成的代码的部分并自动生成代码。
然而,自动生成的代码往往是有额外开销的,节省开发者效率和时间的东西往往会影响机器的效率。对此,C++ 之父 Bjarne Stroustrup 提出了一个伟大的「零成本抽象」的愿景:
What you don’t use, you don’t pay for. And further: what you do use, you couldn’t hand code any better.
这成为很多 C++ 库的一个行为准则,也很大程度地影响了 Rust。一个好的「零成本抽象」是没有全局开销的,你不用,对系统不会产生任何负面影响;如果你要用,你自己手写的代码并不能比生成的代码效率更高。这里 Bjarne 没说但是隐含的另一点是:
零成本抽象必须提供比其它抽象更好的用户体验
,否则,也不会有人用。
零成本抽象这个思想在 Rust 上到处开花,比如所有权和借用(史无前例成功把运行时的诸多内存安全检查和处理放在编译时完成),async/await 的状态机实现(精妙绝伦,性能卓绝且使用如 typescript 般丝滑),以及近乎 python/elixir 使用体验的迭代器(性能却和手写的 C 相当)。关于 Rust 零成本抽象的故事,和本文无关,我们且放下不表。
所以,在考虑自动生成代码这件事上,Quenya 关注的核心是:如何能够自动化生成一些代码,减少开发者对冰山以下部分的工作,同时这些代码又足够高效,使其接近「零成本抽象」的目标?
对此,我首先选择的是请求和响应数据的校验和正规化 —— 这是所有 API 系统极其重要不得不去做的功夫;同时对开发者而言,它纯粹是重复机械的体力劳动。
为什么输入输出的数据校验和正规化如此重要?
因为软件开发的第一条准则是:
永远不要相信用户输入的数据
。
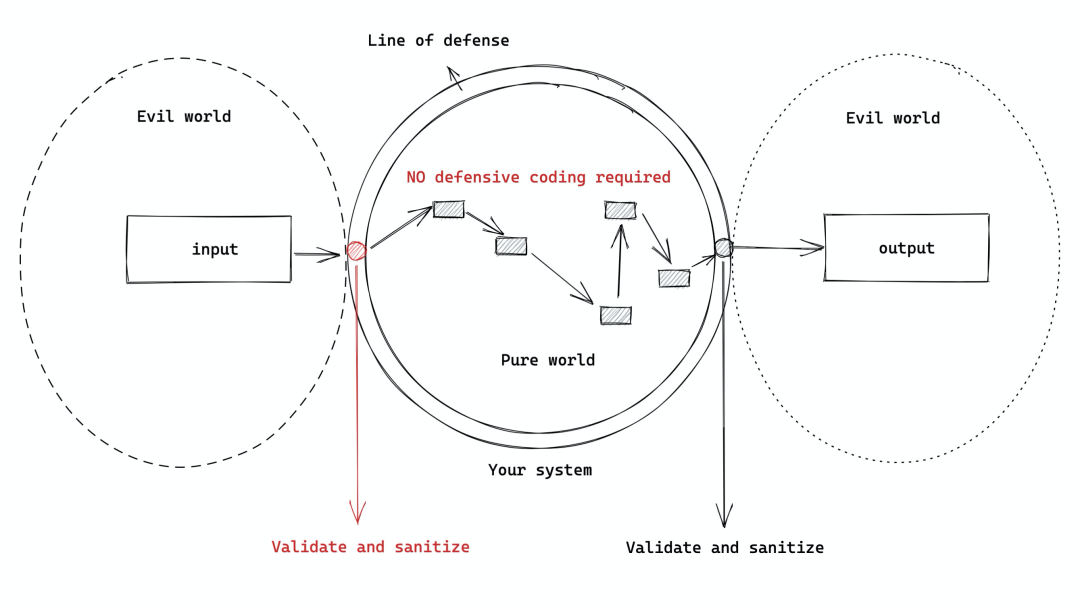
我们需要把我们自己的系统(纯洁如婴孩)和外界(邪恶如撒旦)通过一层类似皮肤的防御体系隔离开来(对这个话题的展开讨论见我三年前的文章:
谈谈边界
)。任何跟外界打交道的过程,都需要经过这条防线的验证(validation)和正规化处理(normalization)。所谓验证,就是保证数据合乎我们期待的结构,或者说 "type safety";所谓正规化,就是将数据转换成我们内部所需要的样子 —— 比如设置缺省值,数据结构的转换等。如果这条防线构建得好,那么,整个内部系统就可以信任任何在内部流动的数据,而无需做 defensive coding。我曾经跟这样一个程序员共事过:但凡他写的代码,全篇,从输入一路到输出,历经的所有函数,在入口处都做各种各样的校验(比如 null 检查),看得我头都大了。我跟他说不能这么写代码,你一定要把系统内外之间的这个边界(boundary)定义清楚,然后只做必要的检查。这哥们不听,觉得唯有 defensive coding 才足够安全,能让他晚上睡个安稳觉。直到今天,我一想起他写的代码还直摇头。
我们写代码,有所为,有所不为。就像老子说的:
知其雄,守其雌,为天下溪,为天下溪,常德不离,复归于婴儿
。一定要
回到事物的本原去解决问题
:
之前做 UAPI(见:
再谈 API 的撰写 - 架构
)时,我通过把 joi 库(nodejs 的一个 data validator 库)融进了 route API,使得开发者可以在定义路由的时候就定义好 schema,运行时,用户传入的参数就会被校验和正规化,构筑起一道严密的防线:
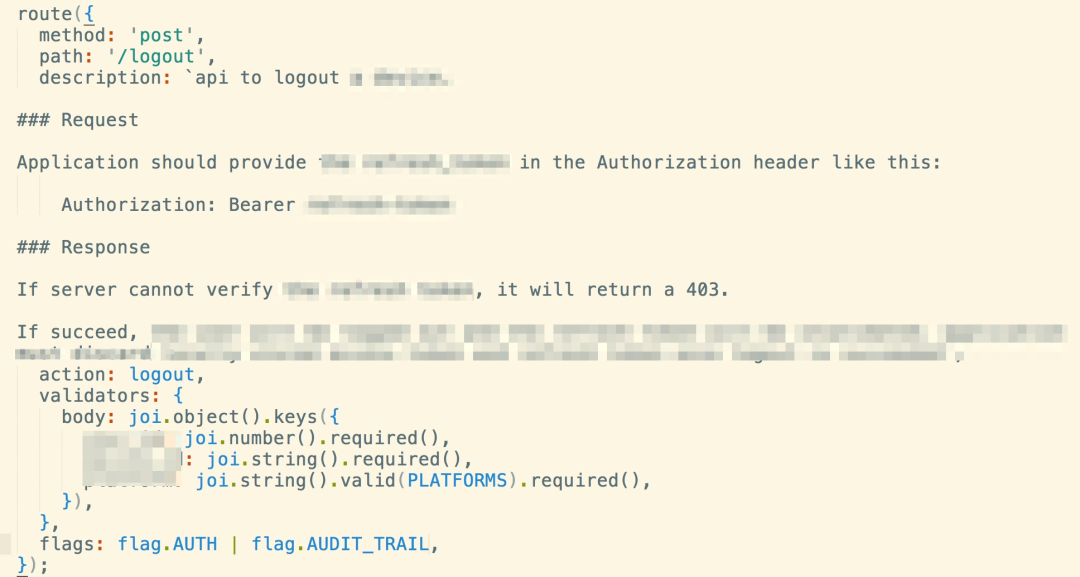
美中不足的是,这个方案虽然很大程度上解放了开发者手写代码去对请求的各个部分做数据校验,但他们依旧需要声明数据校验是如何进行的,因而只是自动化了 50%。
在 Quenya 中,一切都以 OpenAPI spec 为核心,所以我们可以直接使用 spec 里定义好的 schema 进行自动化处理。我们以 Quenya 代码中所带的例子 todo API 中的
createTodo
为例,其 requestBody 是这么定义的:
requestBody: description: todo item to be posted required: true content: application/json: schema: type: object properties: title: type: string minLength: 3 maxLength: 64 body: type: string minLength: 3 maxLength: 140 required: [title] example: title: "hello world"
在生成的代码中,我们将其转化成 ExJsonSchema 的数据结构:
def get_body_schemas do %{ "application/json" => %ExJsonSchema.Schema.Root{ custom_format_validator: nil, location: :root, refs: %{}, schema: %{ "properties" => %{ "body" => %{"maxLength" => 140, "minLength" => 3, "type" => "string"}, "title" => %{"maxLength" => 64, "minLength" => 3, "type" => "string"} }, "required" => ["title"], "type" => "object" } } }end
然后在生成的
Todo.Gen.CreateTodo.RequestValidator
模块(它实现了 Plug 接口)中,执行的代码如下:
def call(conn, _opts) do context = conn.assigns[:request_context] || %{}
content_type = Quenya.RequestHelper.get_content_type(conn, "header") schemas = get_body_schemas()
data = case(Map.get(conn.body_params, "_json")) do nil -> conn.body_params
v -> v end
schema = schemas[content_type] || raise( Plug.BadRequestError, "Unsupported request content type #{content_type}. Supported content type: #{ inspect(Map.keys(schemas)) }" )
case(ExJsonSchema.Validator.validate(schema, data)) do {:error, [{msg, _} | _]} -> raise(Plug.BadRequestError, msg)
:ok -> :ok end
context = Map.put(context, "_body", data)
assign(conn, :request_context, context)end
稍微解释一下这段代码:
-
所有验证和清洁过的输入都会放在
conn.assigns[:request_context]
中,所以我们先要将其取出来
-
然后我们从 content-type 头中拿到请求的 content-type(比如:
application/json
),把上一段代码中展示的 schema 取出来,从 request body 中取出数据,准备验证
-
如果 schema 里不包含请求的 content-type,就报错
-
否则根据 schema 验证请求的数据,如果出错,则报错
-
如果一切正确,把验证过的数据存回到
conn.assigns[:request_context]
中
这段代码非常简单直接,如果同样用 ExJsonSchema 做验证,自己手写也差不多是这个思路,甚至,新手可能不会考虑从 content-type 头里取当前请求所用的 content-type。
如果除了验证 requestBody,还要验证 request header / query string / path variable,那么,Quenya 会在刚才那段代码第一行之后生成这样一段代码:
context = Enum.reduce(data, context, fn {name, position, required, schema}, acc -> v = Quenya.RequestHelper.get_param(conn, name, position, schema.schema)
if(required) do Quenya.RequestHelper.validate_required(v, required, position) end
v = v || schema.schema["default"]
case(ExJsonSchema.Validator.validate(schema, v)) do {:error, [{msg, _} | _]} -> raise(Plug.BadRequestError, msg)
:ok -> Map.put(acc, name, v) end end)
它会对所有在 spec 里定义的 parameters 进行 reduce,取出每一个 param,验证其是否存在,如果不是必须存在,schema 里又有缺省值,设置缺省值,然后验证其 schema。最后,把验证和处理过后的每个 param 存入
conn.assigns[:request_context]
中。
这段代码和手写代码大部分时候效率相当,只有当 spec 有且仅有一个 param 时,开发者手写的代码可以省却 reduce 的操作,效率略微高一点点(可忽略不计)。










