作者:仁基,元涵,仁重
本文选自:《尽在双11:阿里巴巴技术演进与超越》
近十年,人工智能在越来越多的领域走进和改变着我们的生活,而在互联网领域,人工智能则得到了更普遍和广泛的应用。作为淘宝平台的基石,搜索也一直在打造适合电商平台的人工智能体系,而每年双11大促都是验证智能化进程的试金石。伴随着一年又一年双11的考验,搜索智能化体系逐渐打造成型,已经成为平台稳定健康发展的核动力。
演进概述
阿里搜索技术体系目前基本形成了offline、nearline、online三层体系,分工协作,保证电商平台既能适应日常平稳流量下稳定有效的个性化搜索及推荐,也能够满足电商平台对促销活动的技术支持,实现在短时高并发流量下的平台收益最大化。搜索的智能化元素注入新一代电商搜索引擎的各个环节,通过批量日志下的offline离线建模,到nearline下增量数据的实时建模,解决了大促环境下的数据转移机器学习(Data Shift MachineLearning)能力,基本实现了搜索体系从原来单纯依靠机器学习模型做高效预测进行流量投放,到从不确定性交互环境中探索目标的在线学习、预测和决策能力进化。
2014年,我们首先实现了特征数据的全面实时化,将实时数据引入搜索的召回和排序中。2015年,我们在探索智能化的道路上迈出了第一步,引入排序因子在线学习机制,以及基于多臂机学习的排序策略决策模型。2016年在线学习和决策能力进一步升级,实现了排序因子的在线深度学习,和基于强化学习的排序策略决策模型,使得搜索的智能化进化至新的高度。
演进的背景
运用机器学习技术来提升搜索/推荐平台的流量投放效率是目前各大互联网公司的主流技术路线,并仍然随着计算力和数据的规模增长,持续地优化和深入。这里主要集中阐述阿里搜索体系的实时化演进之路,是什么驱动我们推动搜索的智能化体系从离线建模、在线预测向在线学习和决策方向演进呢?概括来说,主要有以下三点。
首先,众所周知,淘宝搜索具有很强的动态性,宝贝的循环搁置,新卖家加入,卖家新商品的推出,价格的调整,标题的更新,旧商品的下架,换季商品的促销,宝贝图片的更新,销量的变化,卖家等级的提升,等等,都需要搜索引擎在第一时间捕捉到,并在最终的排序环节,把这些变化及时地融入匹配和排序,带来结果的动态调整。
其次,从2013年起,淘宝搜索就进入千人千面的个性化时代,搜索框背后的查询逻辑,已经从基于原始Query演变为“Query+用户上下文+地域+时间”,搜索不仅仅是一个简单的根据输入而返回内容的不聪明的“机器”,而是一个能够自动理解、甚至提前猜测用户意图,并能将这种意图准确地体现在返回结果中的聪明系统,这个系统在面对不同的用户输入相同的查询词时,能够根据用户的差异,展现用户最希望看到的结果。变化是时刻发生的,商品在变化,用户个体在变化,群体、环境在变化。在搜索的个性化体系中合理地捕捉变化,正是实时个性化要去解决的课题。
最后,近几年电商平台也完成了从PC时代到移动时代的转变,随着移动时代的到来,人机交互的便捷、碎片化使用的普遍性、业务切换的串行化,要求我们的系统能够对变幻莫测的用户行为及瞬息万变的外部环境进行完整的建模。基于监督学习时代的搜索和推荐,缺少有效的探索能力,系统倾向于给消费者推送曾经发生过行为的商品或店铺。真正的智能化搜索和推荐,需要作为投放引擎的Agent有决策能力,这个决策不是基于单一节点的直接收益,而是当作一个人机交互的过程,将消费者与平台的互动看成一个马尔可夫决策过程,运用强化学习框架,建立一个消费者与系统互动的回路系统,而系统的决策建立在最大化过程收益基础上。
演进的过程
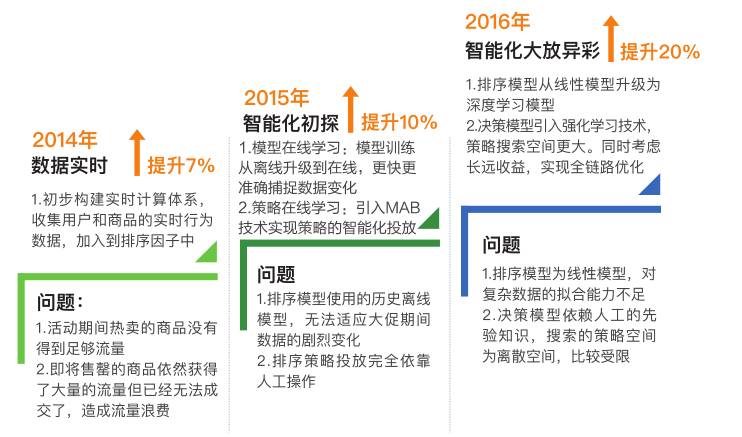
图1 搜索智能化演进过程
1. 2014年双11,实时之刃初露锋芒
技术的演进是伴随解决实际业务问题和痛点发展和进化的。
2014年双11,通过BI团队针对往年双11的数据分析,发现即将售罄的商品仍然获得了大量流量,剩余库存无法支撑短时间内的大用户量。主售款(热销SKU)卖完的商品获得了流量,用户无法买到商品热销的SKU,转化率低;与之相对,一些在双11期间展露出来的热销商品却因为历史成交一般没有得到足够的流量。针对以上问题,通过搜索技术团队自主研发的流式计算引擎Pora,收集预热期和双11当天全网用户的所有点击、加购、成交行为日志,按商品维度累计相关行为数量,并实时关联查询商品库存信息,提供给算法插件进行实时售罄率和实时转化率的计算分析,并将计算结果实时更新同步给主搜、商城、店铺内引擎、天猫推荐平台、流量直播间等下游业务。第一次在双11大促场景下实现了大规模的实时计算影响双11当天的流量分配。
2014年双11当天,Pora系统首次经受了双11巨大流量的洗礼,系统运行可以说是一波三折。10号晚上,Pora系统和算法工程师早早守候在电脑前,等待这场年度大戏的到来。晚上9点,流量开始慢慢上涨,Pora系统负责人毅行盯着监控系统上的QPS逐步上涨,心情是复杂的。有担心和紧张,害怕系统出问题,但更多的是期待,期待一年的努力能接受一次真正的考验。随着时针跨过12点,流量风暴如期而至。Pora QPS飙升到40万/秒,接近日常QPS的10倍。Pora整体运行还算稳定,但延时增加到30秒,30分钟后,随着流量的回落,延时开始下降,暴风雨来得快,去得也快,大家松了一口气。本以为最难的一关都挺过了,后面将一路平坦,但上午9点半,意外来了。9点半突然接到负责引擎的同事的通知,由于Pora更新引擎的消息量太多,造成引擎的增量堆积,无法正常更新了,要我们马上停止更新。而停止更新将会让算法实时效果大幅打折,虽然一万个不愿意,但还是不得不妥协。一停就是3小时,下午13:00重新打开更新,当天累计更新6亿条实时增量索引。算法效果上,第一次让大家感受到了实时计算的威力,PC端成交金额提升5%,移动端提升7%多。
2. 2015年双11,双链路实时体系大放异彩
2014年双11,实时技术在大促场景上实现了商品维度的特征实时,表现不俗。2015年搜索技术和算法团队继续推动在线计算的技术升级,基本确立了构筑基于实时计算体系的“在线学习+决策”搜索智能化的演进路线。之前的搜索学习能力是基于批处理的离线机器学习。在每次迭代计算过程中,需要把全部的训练数据加载到内存中计算。虽然有分布式大规模的机器学习平台,在某种程度上批处理方法对训练样本的数量还是有限制的。在线学习不需要缓存所有数据,以流式的处理方式可以处理任意数量的样本,做到数据的实时消费。
接下来,我们要明确两个问题。
问题1:为什么需要在线学习?
回答:在批量学习中,一般会假设样本独立服从一个未知的分布,但如果分布变化,模型效果会明显降低。而在实际业务中,很多情况下,一个模型生效后,样本的分布会发生大幅变化,因此学到的模型并不能很好地匹配线上数据。实时模型能通过不断地拟合最近的线上数据解决这一问题。因此效果会较离线模型有较大提升,特别是在大促这种实时数据极为丰富的情况下。
问题2:为什么实现秒级的模型更新?
回答:相比离线长期模型,小时级模型和纯实时秒级模型的时效性都有大幅提升。但在双11这种成交爆发力强、变化剧烈的场景下,秒级实时模型时效性的优势会更加明显。根据2015年双11实时成交额情况,前面1小时已经大概完成了总成交的1/3,小时模型就无法很好地捕获这段时间里面的变化。
我们基于Pora开发了基于Parameter Server的在线学习框架,如图2所示,实现了在线训练,开发了基于Pointwise的实时转化率预估模型,以及基于Pairwise的在线矩阵分解模型。并通过Swift输送模型到引擎,结合实时特征,实现了特征和模型双实时的预测能力。
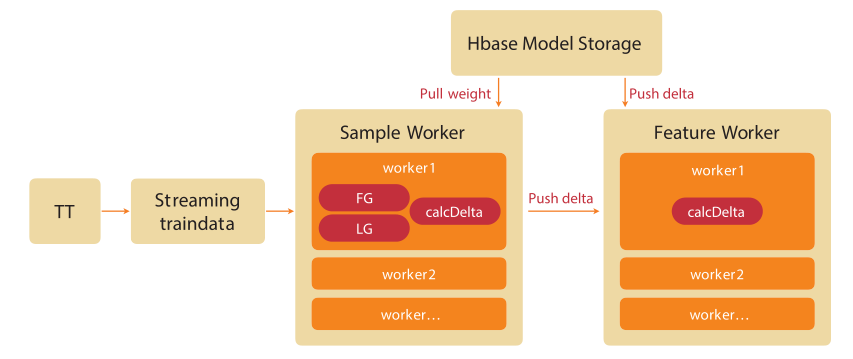
图2 在线学习框架
但是,无论是离线训练还是在线学习,核心能力都是尽可能提高针对单一问题的算法方案的准确度,却忽视了人机交互的时间性和系统性,从而很难对变幻莫测的用户行为及瞬息万变的外部环境进行完整的建模。典型问题是在个性化搜索系统中容易出现反复给消费者展现已经看过的商品。
如何避免系统过度个性化,通过高效的探索来增加结果的丰富性?我们开始探索人工智能技术的另一方向 — 强化学习,运用强化学习技术来实现决策引擎。我们可以把系统和用户的交互过程当成在时间维度上的“state,action,reward”序列,决策引擎的目标就是最优化这个过程。2015年双11,我们首次尝试了运用MAB和zero-order优化技术实现多个排序因子的最优融合策略,取代以前依靠离线Learning to rank学到的排序融合参数。其结果是显著的,在双11当天我们观察到,通过实时策略寻优,一天中不同时间段的最优策略是不同的,这相比于离线学习一套固定的排序权重是一个很大的进步。
2015年双11双链路实时计算体系如图3-17所示。双11当天,在线学习和决策使得成交提升10%以上。
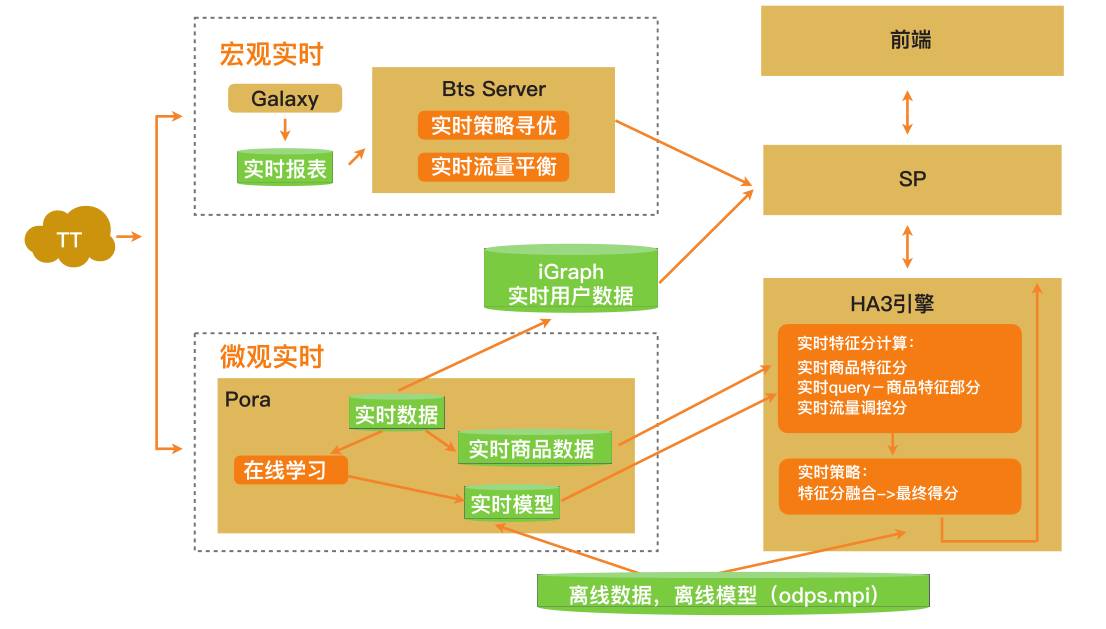
图3 2015年双11的实时计算体系
3. 2016年双11,深度学习+强化学习独领风骚
2015年双11,在线学习被证明效果显著,然而回顾当天观察到的实时效果,也暴露出一些问题。
-
在线学习模型方面:在线学习模型都过度依赖从零点开始的累积统计信号,导致后场大部分热销商品无法在累积统计信号得到有效的差异化表示,模型缺少针对数据的自适应能力。
-
决策模型方面:2015年双11,宏观实时体系中的MAB(Multi-Armed Bandit)实时策略寻优发挥了重要作用,通过算法工程师丰富经验制定的离散排序策略集合,MAB能在双11当天实时选择出最优策略进行投放;然而,同时暴露出MAB基于离散策略空间寻优的一些问题,离散策略空间仍然是拍脑袋的智慧。同时为了保证MAB策略寻优的统计稳定性,几十分钟的迭代周期仍然无法匹配双11当天流量变化的脉搏。
2016年双11,实时计算引擎从istream时代平稳升级到blink/flink时代,实现24小时不间断、无延迟运转,机器学习任务从几个扩大到上百个job。首次实现大规模在线深度学习和强化学习等前沿技术,并取得了非常显著的业务成果,成交额提升20%以上。
在线学习方面,针对2015年的一些问题,2016年双11搜索排序借鉴了Google提出的Wide & Deep Learning框架,在此基础上,结合在线学习,研发了兼备泛化和记忆能力的online large scale wide and deep learning算法。直观看,它的最大优势是它兼具枚举类特征的记忆能力和连续值特征及DNN隐层带来的泛化能力。
针对2015年遗留的两个问题,我们在2016年双11中也进行了优化和改进。对于从零点的累积统计信号到后场饱和及统计值离散化缺少合理的抓手的问题,参考Facebook在AD-KDD的工作,在此基础上,结合在线学习,我们研发了Streaming FTRL stacking on DeltaGBDT模型(分时段GBDT +FTRL),如图4所示。分时段GBDT模型会持续为实时样本产出其在双11当天不同时段的有效特征,并由online FTRL去学习这些时效性特征的相关性。
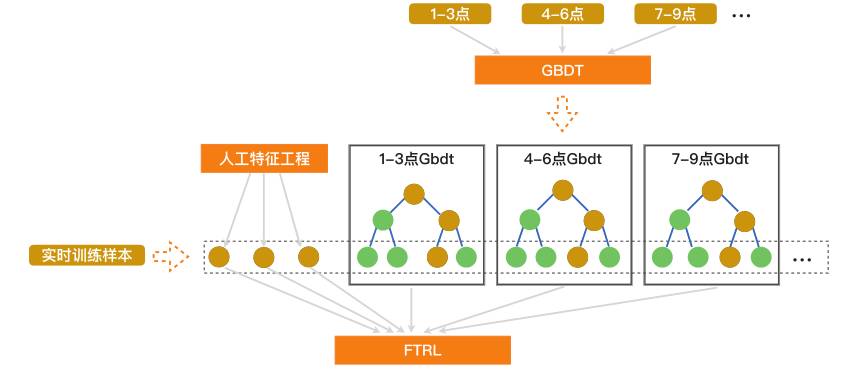
图4 Streaming FTRL stacking on DeltaGBDT模型
对于在决策智能化方面欠下的旧账,我们进行了策略空间的最优化探索,分别尝试了引入Delay Reward的强化学习技术,即在搜索中采用强化学习(Reinforcement Learning)方法对商品排序进行实时调控优化,很好地解决了之前的困惑。
总结
经过三年大促的技术锤炼,围绕在线人工智能技术的智能框架初具规模,基本形成了在线学习加智能决策的智能搜索系统,为电商平台实现消费者、卖家、平台三方利益最大化奠定了坚实的基础。这套具备学习加决策能力的智能系统也让搜索从一个简单的找商品的机器,慢慢变成一个会学习、会成长、懂用户、体贴用户的“人”。我们有理由相信,随着智能技术的进一步升级,这个“人”会越来越聪明,实现人工智能的终极目标。
编者按:本文节选自图书
《尽在双11:阿里巴巴技术演进与超越》
第三章,本书由电子工业出版社于2017年4月出版,内容涵盖在双11背景下阿里技术架构八年来的演进,如何确保稳定这条双11生命线的安全和可靠,技术和商业交织发展的历程,无线和互动的持续创新与突破,以及对商家的赋能和生态的促进与繁荣。








