张瑞
,研究生毕业于北京邮电大学,毕业后一直从事搜索引擎及自然语言处理方向的研发工作。曾就职于百度及豌豆荚。现任知乎机器学习团队负责人。
特约记者丨杨润琦(南京大学),刘冲(北京邮电大学)

杨润琦:
能否和我们介绍一下知乎的机器学习团队?目前主要负责哪些方面的工作和任务呢?
张瑞:
我们团队是一个横向的功能团队,也就是说整个知乎平台上用到的机器学习场景都会交给我们团队负责,也包括建设一套完整的机器学习栈。我们将所有的应用场景分为两大模块,六大方向。两大模块分别是基础数据和基础技术,另一个是和业务相关的,用于改善内容流通和产品体验。
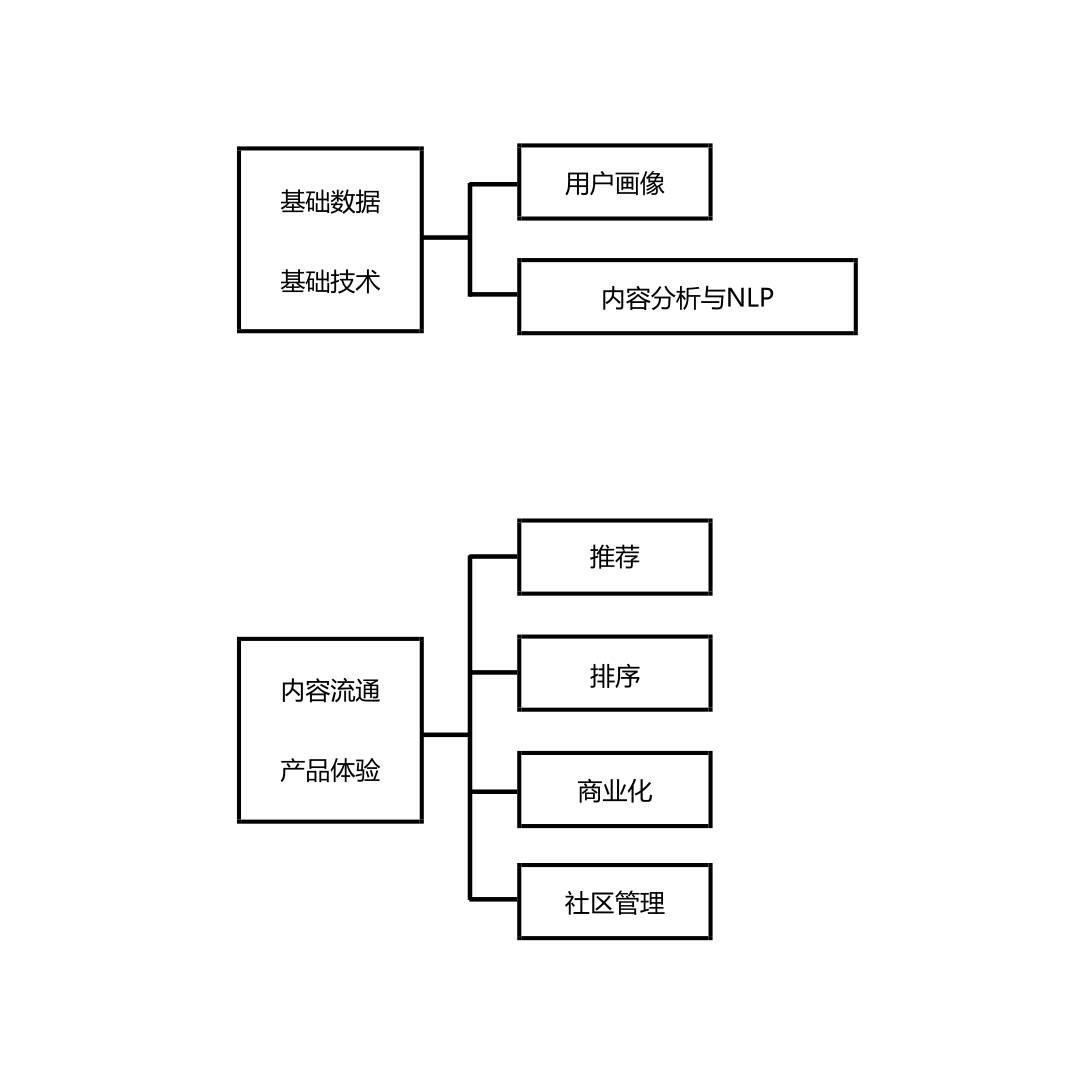
基础数据和基础技术主要包含用户画像和内容分析两部分工作。首先用户画像我们会根据用户的交互行为、回答问题、自身资料等数据挖掘其社会学属性、兴趣爱好等等,也会根据其问答行为对其在某个领域的权威度进行分析。其次内容分析部分主要是针对知乎上面所有的内容(包括文本、图像、音视频等)建立一套完善的内容分析流水线。
一般所有发送到知乎上面的内容都会在发布的第一瞬间通过该实时计算框架,结合自然语言处理、图片识别、或者音视频降噪等技术进行一个基础但是很重要的分析工作。比如说文本类内容,会进行实体抽取、词语切分、topic 建模、分类等。另一个模块就是与业务密切相关的,主要是用于改进用户体验,提升内容在知乎平台上的流通效率,根据业务场景可以划分为推荐、排序、商业化、社区管理四个方面。
首先我们会有一个统一的推荐引擎负责公司所有的推荐场景,进行千人千面的推荐。这里会结合上面提到的用户画像技术和一些比较先进的比如深度学习等方法提升推荐效果。
其次,排序相对而言更横向一点,会用在推荐、首页信息流、搜索等其他模块之中,会针对性的根据各个业务不同情况收集不同数据,提取特征,再训练排序的模型。
第三个是商业化,主要包括广告和机构号,这里会在推荐和排序的基础上做一些更有特点的工作,比如针对广告主做竞价、流量预估、物料推荐等等。
最后一个就是社区管理,这部分工作与内容分析和用户画像的对接比较紧密,会做一些最基本的工作,比如色情图片检测等,以及根据用户画像和内容分析得到的一些数据,结合社区管理层面的业务需求做一些更上层的事情。
以我们正在做的“潜在权威创作用户挖掘”举例,在知乎平台上有很多优秀的答题者,他们在自己的专业领域积累了一定知识,具备很强的能力,所以我们需要在第一时间发现他,并邀请他创作高质量的内容,从而提升用户产生优质答案的生产效率。所以整个来讲,我们机器学习团队的工作主要分为两个大的模块,六个方向。
杨润琦:
您觉得从技术层面上来讲,团队成立以来解决过的最大的一个困难是什么?
张瑞:
从我个人的角度上来讲,目前我们所遇到的问题、正在做的事情大都还是能够想得很清楚,很少遇到从一开始就不知道该怎么做的情况。而且有些我们在做的东西我感觉还是不错的,甚至还超出了我们的预期效果。就像爬山一样,在爬之前可能会觉得很难爬甚至爬不上去,但是等你过去了之后你就会觉得其实一步一步走上来也没有那么艰难。
以我们首页的产品举例,过去半年首页的转化率提升了将近 70%,同时首页的停留时长也增加了 40% 多。也就是说配合上用户留存率的提升,用户在首页的内容消费大概翻了一番。
但是在我们做这个工作之前,我们想的只是一步一步踏实的推进,一步一步地把能想到的特征提取出来,比如说用户的兴趣、实时兴趣、答案本身质量好坏、用户兴趣与答案所属领域交叉、用户本身的社交关系、与发布答案者的社交关系交叉等等,这些都是一点一点添加到模型中的,欣慰的是在做的过程中发现提取的这些特征都能够转化成比较好的效果,每一次都有比较好的提升,经过半年的迭代,最终收获了比较不错的效果。
刘冲:
前面提到的两大模块六个任务,是如何进行分配和组织的呢?整个工作耗费了多长时间?
张瑞:
我们在去年年初的时候刚刚建立团队,目前团队已经接近 20 个人规模,初期团队主要是把精力集中在基础数据和基础技术的工作上,比如用户流量场景优化、知识的商业化、社区管理等工作也会有所涉及。到今年,我们结合了一些深度学习领域的研究成果,搭建了完善的推荐系统。
目前来讲六个方向上都会安排人去做,大家齐头并进,具体到某一个方向还是会根据具体的工作场景决定工作的方法。其实我们还有很多项目想要开展,也一直在招募工作伙伴中。
杨润琦:
刚才说到在推荐系统中会用到深度学习相关的技术,可以具体的聊一下吗?
张瑞:
其实深度学习用在推荐也好、排序也好、搜索也好,本质上说解决的是用户信息需求和信息之间的匹配关系。在拥有足够数据量的情况下,深度学习可以更好的解决这些问题。
比如说推荐,之前可能先把内容划分到一个具体的领域,体育、商业等,然后再看用户喜欢哪个领域的内容,将很多交叉特征去组合起来做推荐。这样的缺点是,首先领域信息是人工设计的,可能和用户真实需求有一定差距,比如说用户喜欢体育,但并不代表所有体育的东西都会喜欢,可能只喜欢乒乓球、篮球,不喜欢足球,另外一个就是特征会比较稀疏,很难找到其关联性,比如一个人喜欢商业,那大概率也会喜欢金融,这就需要一个非常复杂的规则或者补充模型来解决。
所以说浅层学习,比如 LR 这种模型,当你用到一定程度之后就会考虑向深度学习上转移,使用深度学习来解决信息需求和信息本身之间的匹配程度问题。这里用户的信息需求可能表现成其历史行为中体现出来的兴趣,用户的资料也会体现他喜欢的东西,把这些东西全部拿过来当做用户信息需求表征的一部分,通过这种上下文信息以及海量的用户行为来预测用户会看什么内容,今天看了什么,明天会看什么等等。
目前我们使用了四层的神经网络,融合了 CNN、word embedding、userembedding 等预训练的嵌入式表示,使用这样的网络去做匹配。那么通过这个网络推荐出来的东西,相对来讲可以搞定传统机器学习解决不了的问题。所以我们开始用深度学习来解决推荐推荐、排序等问题,比如说搜索下面我们会做 query 和内容文本之间的匹配。
刘冲:
我记得之前谷歌发过一篇用深度学习做视频推荐的文章,那么您在做这个方向的时候会参考他们的论文,使用他们的模型还是自己会尝试修改?另外就是当从传统机器学习转型到深度学习时,你们专门招一些深度学习的人才还是让技术人员进行转型去学习这方面的东西呢?
张瑞:
第一个问题的话,我们肯定会参考业界最先进的技术,比如说谷歌的两个 DNN 网络做视频推荐这种,不过我们最后用到的东西并不会完全按照他们提出的模型进行部署,但实际上讲,大家用到的技术从本质上讲都是差不多的,思路也是一样的。
我们会参考他们论文里提出的先进的经验,比如说 wide and deep 网络结构,wide 负责 memory,deep 负责推理和泛化;YouTube 使用多个神经网络进行推荐,将用户和内容进行 embedding 的思想我们都会进行借鉴和参考,把一些好的特征加入到我们的网络中,所以说最后在技术层面上来讲是融合各家之长。
第二个问题,我觉得传统的机器学习和深度学习之间并没有很深的鸿沟,其实是可以跨越的。像我们现在在做推荐系统的很多同学,他们之前是使用 GBDT、LR 等传统机器学习方法去做,但大家学习、接触深度学习的知识还是挺快的,因为本身来讲,深度学习和传统机器学习之间的优化思想、理论基础还是比较类似的。
刘冲:
那你们会不会找一些这方面的大牛来带着做还是就靠自己去学习?
张瑞:
知乎有很多比较有经验的工程师,也会有一些刚入门的同学,他们之间肯定会存在技术上的差距,所以经常会举办一些技术分享、新人与老人之间的传帮带等等,大家会经常坐在一起分享和讨论。比如说我刚才说到的那些深度学习方面的项目,都是我们在技术分享周会上面参考了很多同学的调研结果,然后大家一起讨论,总结出一个适用于知乎的一个架构出来。
至于说会不会找这方面的大牛,可以透露一点就是我们会有比较新的或者前沿的产品探索去做,涉及到自然语言处理和智能问答方向,这块我们想找一个资深科学家去做前沿的探索,这也是对我们团队本身技术能力、人员梯队的一种补充。
杨润琦:
能不能跟我们分享一下知乎机器学习挑战赛的相关内容,为什么想要办这样一个比赛?
张瑞:
知乎机器学习挑战赛的初衷是想激发一下大家对于自然语言理解这个领域的兴趣。这个题目其实当时我们也是考虑了很久,然后比较慎重地去选择的。首先我们觉得它比较能够体现知乎的特色,这个题目跟知乎的产品结合得还是比较紧密的。
另外我们在设计这个题目的时候也考虑了它的难易度和区分度,一方面对于刚入门的同学来说,想要借助这个题目去尝试、去实践一些很传统的方法,甚至很简单的一些方法也是 OK 的;另一方面它不是一个可以非常容易就被很好地解决的问题,做到一定阶段之后如果想要提高,可能就需要设计一些创新的点或者引入一些更前沿的技术,所以题目也会存在一个区分度。
比如我们提供的数据里面,包含标签之间的结构信息和标签本身的意义的信息,这个对应的是现在多标签分类里面的比较前沿的方向,就是包含结构信息的标签的多分类问题。我们希望比较优秀的队伍能够把这些信息利用起来,去做一些不错的创新。
刘冲:
那您觉得现在比赛的进度可以达到你们的预期吗?
杨润琦:
以及您怎么评价那些排名靠前的团队目前达到的程度?
张瑞:
我们记得当初我们做这个规划的时候,是说我们大概会有七八百支队伍这个样子。现在比赛进程大概到一半,已经有快九百支队伍参加,所以从进程上来讲还是不错的。
从选手提交的结果上看——其实我们有定期的周报收集,收集一些已经做出来比较优秀的结果的队伍的代码和说明文档。我看了一下,其实里面还是有一些比较闪光的点。整体上来讲,大家在把一些最前沿的技术运用进来,或者说是在比较复杂的模型上面去调整模型的效果,在这方面的能力其实还是非常棒的。
如果要说还有什么缺憾的话,我觉得可能是目前虽然看到了很多小的闪光点或者创新点,但是还没有一个比较大的跨越式创新出现。不过归根结底创新本来就也不是一个很容易出现的事情,所以其实到现在为止,我觉得整个比赛的进度,包括大家的结果,从我自己来看,还是比较超出预期的。
刘冲:
您觉得最后预计最后得分能做到多少?
杨润琦(坏笑):
会超过当前线上模型的表现吗?
张瑞:
从得分公式的设计上来看,最后如果你能做到 100% 的准确的话,满分是 0.8 多一点,但是数据本身存在一定的噪声或者说缺失,因为我们的产品有个限制,对问题打的标签不能超过一定的个数,而一个问题可能和十几个标签都相关。刨除掉这个因素,我们预计最理想的结果可能可以到 0.5 往上一点。
目前提交上来前三的同学在测试数据上的表现已经做到相当不错的程度(注:截至采访时间 A 榜最高分数在 0.42 左右),当然和我们的线上还是有一定的差距,但是这个对比本身可能有一定的不公平性,因为我们线上拿到的数据可能会更多,而且都是明文(注:指比赛数据经过了隐私保护和脱敏处理),所以直接这样去对比还是不公平的。
刘冲:
在做算法的时候,准确度和计算效率目前你们会更看重哪一点?
张瑞:
在绝大部分场景下,我们追求的是准确度,然后计算效率。
刘冲:
是因为实时性的要求并不高吗?
张瑞:
并不是这样,其实是说计算资源相对于准确性来讲还是比较容易去解决的。比如说我们做深度学习的模型,四层网络的预测,基本上在 CPU 机器上面对一个 batch 的数据,例如 50 条进行预测,耗时是两毫秒左右,换用 GPU 的话还会更快。互联网工业界有一个比较流行的说法,就是说你能够通过升级机器或者加机器来解决,就不要去改动模型和算法,因为机器总是比人要便宜很多的。所以在绝大部分时候,我们确实是更追求准确度,也就是说最后线上产品的效果。
我觉得你这个问题可能可以升级一下,就是说算法的效果和算法的整体架构哪个会更重要一点。比如说你是希望一个比较清晰的架构,它的效果稍微差一点;还是拼凑了很多乱七八糟的东西,最后产生的效果比较好,但是你也很难去修改它?
这个时候,从一般的实践上来讲,我们会更倾向于那种优秀的架构,因为它往往能够带来迭代效率的提高。可能从第一版来看,它的算法的效果确实不如其他的堆起来来得那么快,但是一般来说算法不是一版就可以来完成,一个比较优秀清晰的架构为算法的迭代带来便利是比较大的。如果可以做到两天三天就完成一个迭代,那么就可以把效果一点一点提升起来。所以这种情况下来讲,算法的架构上的清晰和优美到最后仍然还是为了这种算法的准确度去服务的。
杨润琦:
所以可能它最终还是保持了一个良好的架构,但是准确度已经超过了之前的那种七拼八凑的?
张瑞:
对。
杨润琦:
这让我想到了一个很有意思的问题,我某个师兄去某互联网公司做算法的时候遇到了一些麻烦,就是他引入了一个比较新的技术范式,这个范式做成以后以前做的一些模块就显得比较累赘了,从算法效率来看应该去掉,但最后却保留在了系统里,因为其他工程师会觉得那是他们做了几年的东西,如果整个去掉就是否定了他们的工作成果,对于这个现象您怎么看?
张瑞:
就是说技术更新换代,可能会……
杨润琦:
遇到这种非技术的阻力。
张瑞:
知乎基本不存在这个问题。其实不光是我们团队内,也包括我们这个团队和其他技术团队之间的沟通,或者说我们这个技术团队和业务团队之间的沟通,大家在做事情的时候其实还是会以最后的效果为目标,很少遇到这种非技术的、或者纯粹从这种抢事儿或者划地盘这种方面来的阻力。
我觉得做数据的同学,最后都会有一个比较强的 sense,就是数据驱动。如果最后拿不出明确的数据来支持你的观点的话,那这种吵架,或者说抬杠,其实都没有意义。在知乎我们还是比较倾向于用这种方式去做沟通和交流的,以最后客观的标准去看哪种技术,或者说哪种方案会更好一点。
杨润琦:
在最后能不能给年轻人一些建议,尤其是对未来想要应聘机器学习岗位的博士生或者硕士生?
张瑞:
我觉得对于一个机器学习工程师来讲,工程能力和对机器学习理论的理解能力,这两个方面其实是不可偏废的。工程能力,或者说架构能力,可以使你的做事效率有一个质的提升。比如说做机器学习的工程师,肯定是会遇到很多实验的,需要收集数据、采集各种各样的特征,这个时候,你的工程能力,包括我刚才提到的架构决定了你迭代的快慢,或者说你把你自己的想法去实现出来这样一个快慢。这是工程能力提升了之后能够给你带来好处。
另外一个是在机器学习理论方面的能力。现在我们开源的库或者包其实都很多了,很多同学会觉得,我能够在数据上面跑出来结果那就 OK 了,我不需要关注它里面是什么样的,这其实是一个误区。如果你对它的理论基础没有一个清晰的认识的话,你是不知道怎么去对它做优化的。
比如说举一个最简单的一个例子:线性模型和非线性模型的选择。这个时候你需要知道 LR 是一个广义线性模型的然后 GBDT 是一个 tree based 的非线性模型,它能够对特征进行非线性划分。在不同的场景下面,特征对最后的目标的贡献,可能是线性的,也可能是非线性的,如果你不知道这个的话,对于模型的效果就没法去做提升了。这个是对知识和技术层面的一个考量。
对于在校的同学,其实还是建议大家能够多去做一些实践,包括利用自己的寒暑假或者是闲暇的时间去实习,或者说去参加一些竞赛,比如说我们的知乎机器学习挑战赛。现在来讲,工业界用的数据和很多实验室的数据还是有挺大的不同的,公司做事情的方式和在实验室做事情方式也很不一样。如果能有一些实践的经验,这对你今后的帮助是很大的,它可以让你很快地去适应这种公司的节奏或者是方式。
杨润琦:
实践上您刚才提到了可以通过实习或者比赛来证明,那么在求职应聘的时候,应该怎么样凸现自己理论方面的能力?
张瑞:
一般来讲最好是你的简历能够引导你的面试官去问你一些你比较擅长的问题,或者说是能够展现你的亮点的问题。这个一方面是你过去做的一些事情,包括你的实践经历,另一方面可能还会有你的 GitHub,你之前整理的一些技术博客或者文档,这些东西都能很好地体现你过去所做的事情和掌握的知识。其实我接到简历里面,很多同学都会有自己的 GitHub 地址,有的同学确实也实现出来很漂亮的代码,我每次筛简历遇到都会很认真地去看。
另外如果想要展示你知识的扎实,那么对于所有你做过的东西里面涉及到的基础知识是需要有一个很好的掌握的。举一个例子,比如说做文本相关性的,多多少少的都会接触到 word embedding,很多人只是说我拿 word embedding 来简单地用一下,但如果你对它有一个比较扎实深入的了解的话,其实是能够为面试官带来很多不一样的感受。
关于PaperWeekly
PaperWeekly是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事AI领域,欢迎在公众号后台点击
「交流群」
,小助手将把你带入PaperWeekly的交流群里。






