付钱拉是一家做金融云服务的公司,目前对外提供有支付、资金管理、大数据征信、余额增值、理财超市等与金融相关的服务。付钱拉提供的这些金融服务非常简单好用,跟互联网上的大家看到的OAuth,评论等互联网接口类似,对接付钱拉的支付只需要7行代码。金融简单化,互联网化是我们企业的夙愿。但金融服务跟其他服务相比也有几个特点:
安全,稳定压到一切
数据要求强一致
重试成本高
调用链长,延时高
全程可回溯
用户操作谨慎
业务场景的这些特点会随着版本演进,逐渐渗透到付钱拉的整体架构设计里面,后面会慢慢展开。
目前付钱拉仍是一个创业公司,从2014年至今付钱拉经历了4次大的技术架构调整。目前仍在中小规模下运作,如果读者您目前的团队跟我们差不多,那我想会有更多共鸣。所以本文有几个适用范围:
处在技术债的积累期。
开发团队几十人。
硬件规模不过百。
服务调用千万级。

all in one 模式,所有服务都在一起,部署准双机,之所以叫准双机,是因为还略有不同。右边那个webapp里面还有定时任务,上面是网络分发层,下面是DB。是不是很熟悉的感觉?开发框架是Spring+MyBatis。网站前台,管理后台,定时任务,API接口都在一个war里面。所有操作直接打到数据库上,业务和通讯耦合和在一起, 批处理和实时接口也耦合和在一起。
大家看这个很low吧。业务刚起步的时候,逻辑简单,访问量也不高,其实还好。随着公司业务的迅猛发展,几个月后这套架构的不足就体现出来了。比如:
各种模块耦合严重,不能局部扩容。
直接打数据库,IO和CPU都过载。
历史数据沉淀拖慢数据库性能。
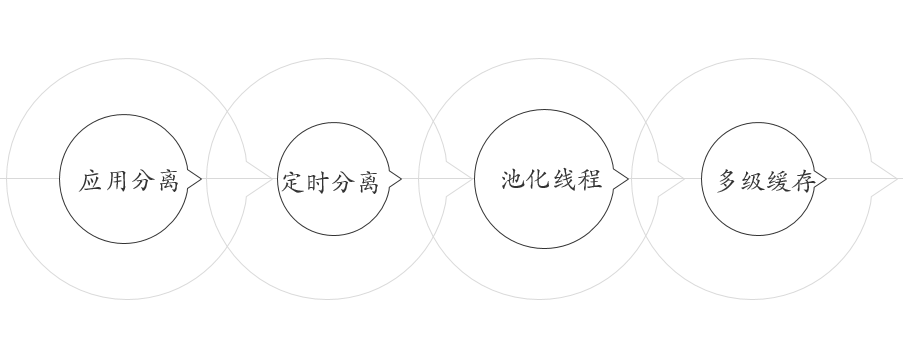
解决V1.0的问题,最简单的方式就是拆应用,加机器,加内存,换SSD。把前台、后台、定时、接口拆成4个应用,独立部署。为了解决数据库性能问题,增加多级缓存。JVM里面的localCache,分布式Redis的上线,大大降低了数据库IO。如果业务稳定了,其实这个架构我们会一直沿用下去。
付钱拉遇到的真实情况是随着业务的迅猛发展,平台的功能模块开始了爆炸式增长。各种需求层出不穷,人手也比较紧张,本着先发展后治理的思路。经过3个月的努力,终于把项目写成了一个大泥球,运行速度越来越慢,新增修改需求也越来越慢,Bug越来越不容易捉,最主要性能也扛不住了。这个时候,不改也不行了。

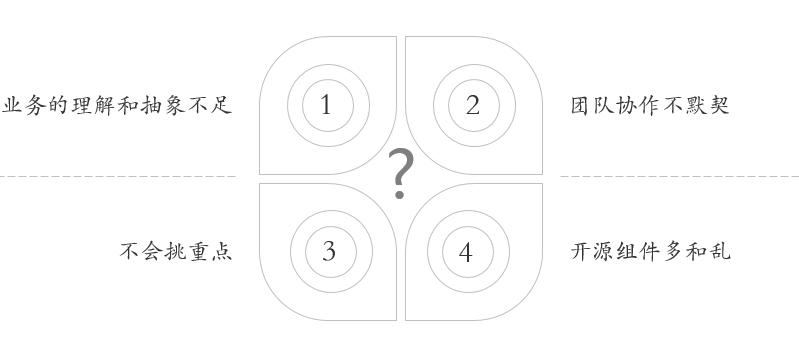
泥球一定不好吗?如何拆解大泥球?新业务线如何避免写成大泥球?我们总结了一下,有以下几点:
增强业务的理解和抽象
增强团队协作和知识储备
学会挑重点,合理安排优先级
其实如果业务逻辑不是特别复杂,系统对于性能、稳定性要求不是特别高。这套简单实用的架构挺适用于小公司的快速发展的。回头有机会我们把V2.0的架构开源出来,让大家评判一下。
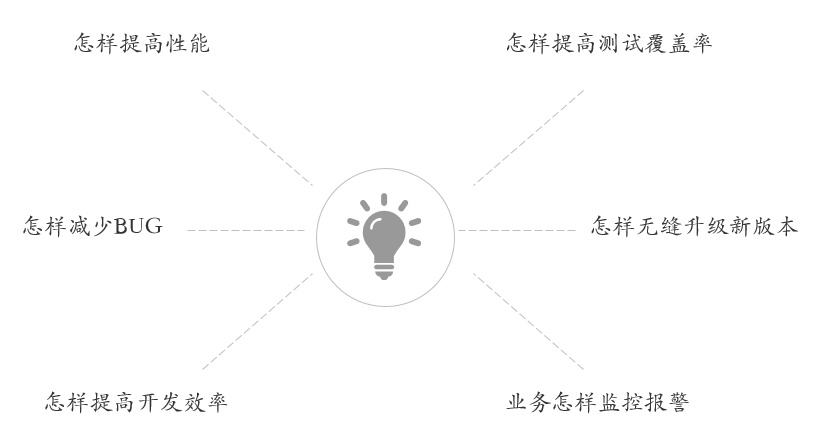
V1.0和V2.0 架构其实没有大多变化,主旋律是拆分解耦和加机器加缓存。这也是目前业界普遍采用的做法。那有没有更好的设计理念?
可以灵活的提高性能;
可以简单的做单元测试;
可以无缝升级新版本;
可以稳步提高开发效率;
我们先看两个非常简单的问题:

假设付钱拉只提供两个API,一个是做加法,客户端给参数a和b,服务端返回a+b。一个是做++1,客户端get,服务端获取最新值+1后返回。
1+1 是一种CPU密集型操作,API主要做计算操作,而且不需要保存状态,这种服务我们叫无状态化的计算型服务。因为没有状态,无线程安全问题,完全可以并发操作。如果顶不住了可以随时加机器解决。
而++1这种呢,需要获取当前的最新值,才可以做+1操作,是一种有状态的服务。这种服务我们叫有状态的IO密集型服务。
++1 还有一个特殊情况,服务线程还需要考虑并发的问题。再考虑上分布式环境下,状态不能单机保存,还需要考虑集中存储的问题。
以上两个例子,是目前付钱拉API的两个典型的场景。
借这个场景来说明有状态无状态,IO密集,计算密集等API设计时的通用问题。那么怎么解决呢?
我们先从程序的结构上说起,API也是一个程序,按照各位大佬书上说的:程序=数据结构+算法。
算法就是1+1的问题,加法就是一个最简单的算法。++1 更多的是一个数据结构的问题,比如使用Redis的Incrby来做累加,因为Redis的单线程模型,分布式存储和线程同步的问题一并解决了。所以比较好的设计思路是把算法和数据结构完全分离。
如果程序不能完全隔离状态,那就把状态(数据结构)托管到专门的状态存储中间件。比如Redis、MySQL等,逻辑和状态从设计和部署上解耦,即所有的服务都是『无状态化的服务』。

基于金融服务要求完全可回溯,再考虑到数据库的并发锁性能问题。更新操作可以理解为先删除再增加,更新操作首先是一个随机IO,定位数据行需要时间。


另外操作也比较复杂,先删后加,更新还会丢失历史版本,比如更新1->2->3,我们只能看到最终结果3,看不到过程1和2了,所以建议用新增替代更新。
所以 把状态理解成版本,版本只能新增累加,如 git svn 等版本控制工具。
新增操作是顺序IO,一直在表的末尾追加,性能优于更新而且新增不会有并发的问题,更新要考虑并发。另外新增可以保存所有的历史版本,例如新增1,2,3,都在表里面。
思考了这么多…..那么新的架构要满足那些条件呢?
综上所述,新版的架构应该具备目前比较流行的”微服务”的特质:
模块化
服务化
异步化
简单可调试
全流程跟踪
原生云支持,弹性部署
3.0这个版本 从webapp切换成了微服务架构:

给大家看看我们的事件处理机制:
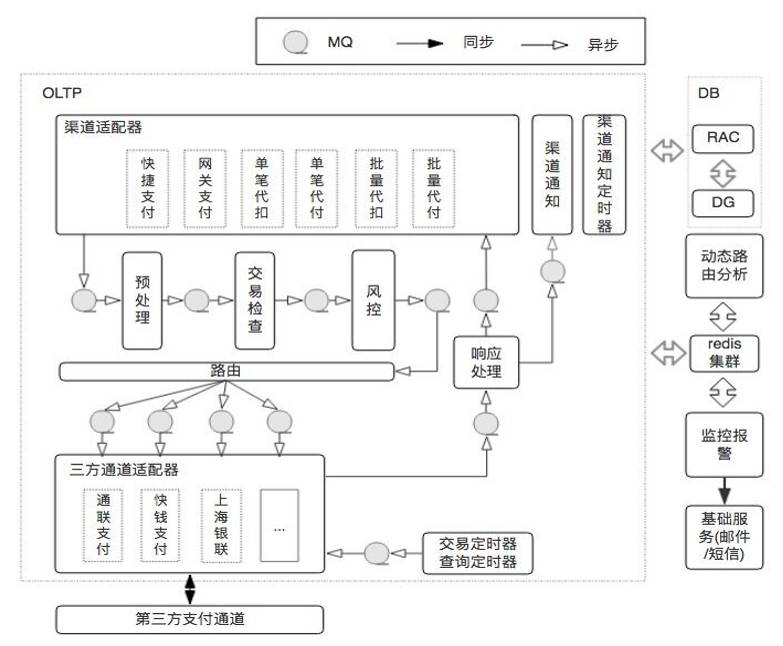
V3.0是一个基于MQ消息的异步驱动的流程组织引擎,整体的业务流程都是消息驱动,上游处理完毕后,把消息扔给下游就不管了。哪个模块出了异常都可以随时终止流程返回给调用方,如果程序正常执行完毕,最末端的模块负责给调用方响应。
那模块如何响应调用方?调用方在发消息的时候,在报文里面放一个UUID的队列名称。调用方发出消息后,就开始阻塞监听这个UUID的返回队列,各个处理模块都可以给这个UUID队列放消息,调用方收到消息后流程就结束了。我们内部叫”用两个异步的消息,完成一次同步的通讯”。
V3.0 上线后极大的提高了我们的处理性能,弹性局部扩容,异步化等特性也都具备了,终于可以喘一口气了。
差点忘了说了,V3.0重构时我们顺便解决了数据的分库分表问题。
数据库集群分了三个大区:
“在线库”主要做实时交易用,日表操作,只保留最新的7天数据。
“离线库”主要做查重和实时交易统计,数据秒级同步,周表操作,保存半年。
“历史库”主要做BI和数据分析,月表操作,永久保存。
V3.0 稳定了半年多吧,也发现了一些问题,也在逐步的完善。有一些基础的设计理念,针对日益复杂的需求变更,还是有点慢。目前我们的核心业务有一部分还跑在3.0这个架构上。其他大部分业务我们都在V4.0这个框架上了。V3.0和V4.0其实是有不同的适用场景的,不是一个完全的新版本替代关系。

V4.0 相对于 V3.0来说,有几个显著的改变:
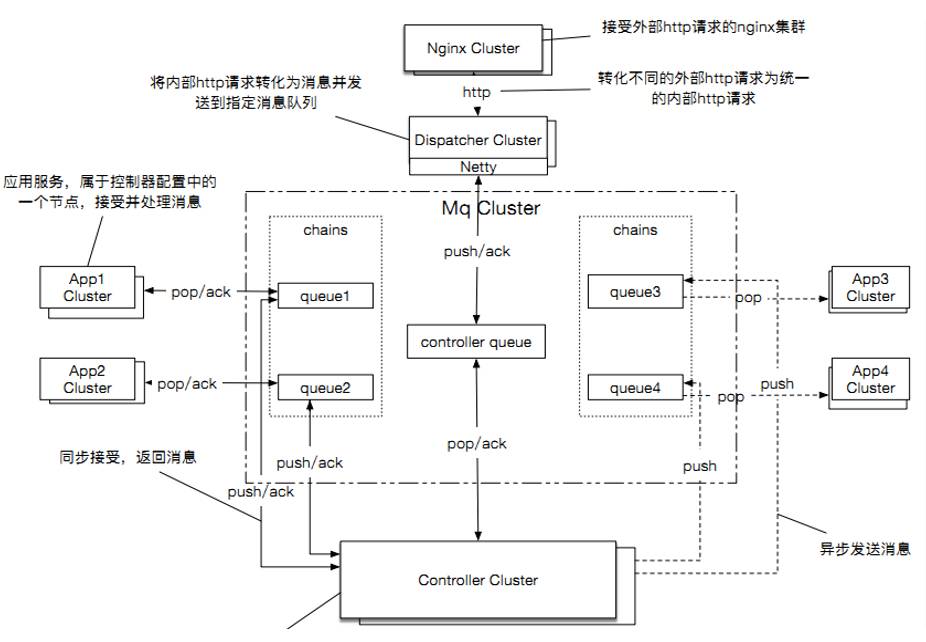
大家可以对比一些 V3.0的架构图。
增加了控制器队列,主要负责消息的编排,各个具体功能模块执行完毕后。
不需要决定把消息给那个下游模块了,而是直接返回给控制器模块,控制器来决定下一个模块是谁。
控制器模块其实也是一个普通队列可以多点部署防止单点故障。
控制器模块的编排是根据配置文件来做的.配置文件里面定义了一个业务的调用链。
配置文件支持简单的顺序,选择,循环和tryCatch等分支流程。
下面是一个例子:

单看性能参数,3.0的性能大概是4.0 的2.5倍左右,4.0主要用在业务逻辑多变,性能要求不是特别高的场景下。
下面说一下付钱拉的批处理和调度:

我们仿照Hadoop搞了一套调度与批处理,用nas mount网络存储 来替代HDFS实现分布式文件存储。用数据库MySQL来存放调度等meta数据,替代jobtracker。大体一个拉模型,各个任务节点都要主动去MySQL里面轮询任务。
有没有我的任务?
不停的去MySQL里面查…
业务和运维人员可以用sql和我们的工具界面。
操作数据库的记录实现任务的分配 执行 结果反馈.. 重提 .. 可以自动跑批,也可以人工干预。成本不高 但是很简单实用。
这个批处理架构有兴趣的,我们可以单聊,今天就说个架子,不详细展开了。
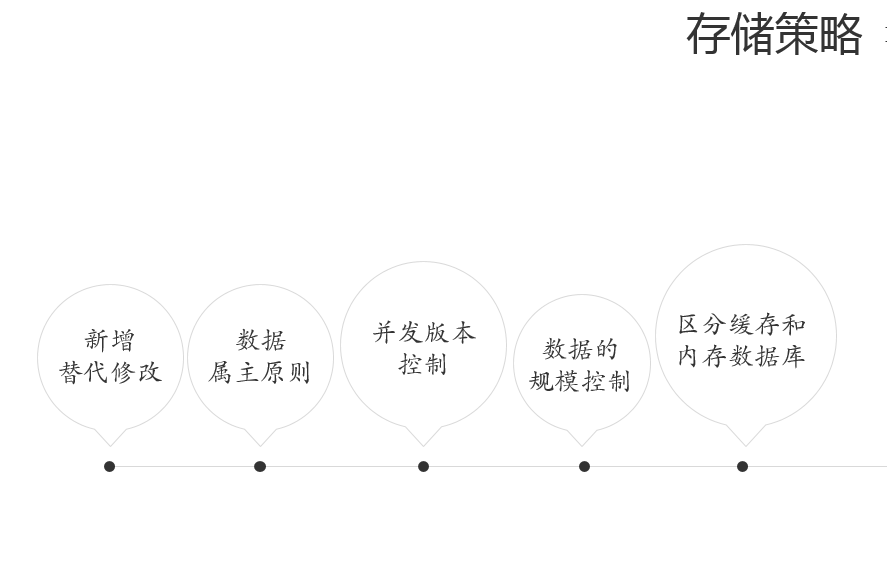
上面这个PPT说的是数据库的一些设计的基本原则。时间关系也不展开讲了。点击阅读原文,你可以下载本文的演讲稿。









