
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
一致哈希环的提出是一个非常棒的发明,然而却让人不太好理解。一般来说,实际与理论有很大的不同,一个理论能否在实际中得到广泛应用与大家对它的理解程度有关,然而具体的实现方法却可能不太理解,因为这些太抽象了。
本文尝试用Python对哈希环进行简单的说明,希望大多数人都能够理解。
为什么要用Hash?
通常情况下,你需要根据一件物品的名称来找到与之对应的东西,例如,你可以通过URL地址来访问特定的网站。这些事情都可以通过映射来完成,就像是你拿着电话本根据联系人姓名来查找电话号码。还有一本书下面的索引也是一个映射,你可以根据关键字找到指定的页数来获取需要的内容。来个书面点的说法,所有的映射都是根据一个条目经过一种特定的方式找到另一个条目。
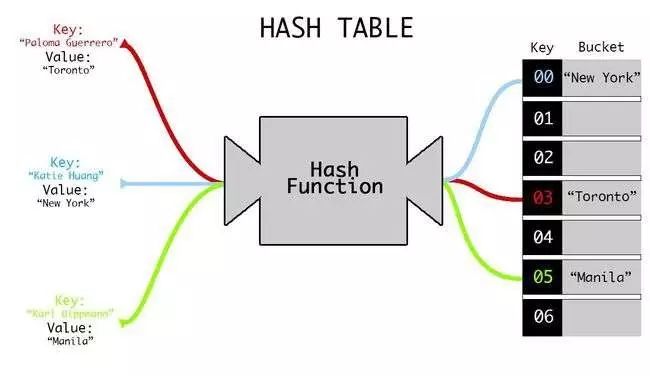
在计算机中也有这样的例子,例如,在内存中存储一个数,计算机会标记一个值,然后根据这个值通过某种方式找到内存中的那个数。在整个过程中,找到内存地址的方法称为哈希算法,映射是根据哈希表来完成的,内存的位置叫做哈希桶(hash buckets)。
问题1:有限内存
一般情况下,哈希算法会根据一个键生成一个尽可能无限大的数来表示内存的位置,但是实际中,计算机提供的内存是非常有限的。也就是说,哈希数和计算机内存之间是不可能直接形成一对一查找的。
解决方案就是避免这种情况:
1、提前知道所有可能的内存位置
2、顺序使用,如果可能的话将其按序列标记
3、取一个键计算哈希数并将它除以内存位置数,也就是取余
最终你计算出的数就放在内存位置数和它一样的内存处。举例来说,就是假设你有10个可存储位置,你的哈希数键值为103,将这个数取余得到3(1013%10=3),然后就把这个数放在标记为3 的位置处。
当我查询这个数时,就执行这些步骤,存储一个新数时,也同样如此,那么这些数就始终储存在这个位置 hash % buckets。
对于许多现实世界的应用来说,这实际上是足够的。 这有两个简单实现哈希表的代码:
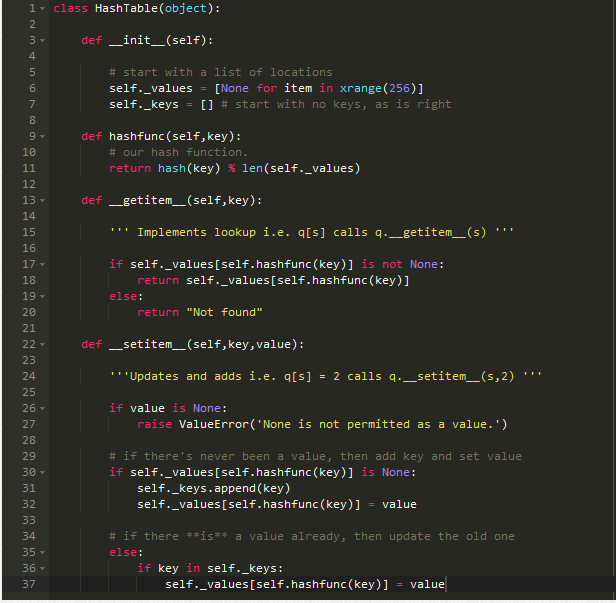
一个更加完善的哈希算法应该能够解决更多的数值,或者有两个不同的数值却产生了相同的哈希数这样的问题。好在这些都得到解决了。
问题2:消失的桶
一般的哈希表依赖于固定不变的存储位置,实际情况却并非如此。让我们通过以下步骤来了解存储位置数n发生变化时会出现什么样的事情:
1、开始有10个存储位置,要存储的数的哈希值为1013
2、将这个数放在1013%10=3的位置
3、将存储位置数改为9
4、现在根据同样的方法要查找原来的数,结果却返回103%9=5处的数,很显然这是错误的
返回错误的数时无法想象的,就像你输入谷歌的网址来访问Facebook一样。不过这样的事情却经常发生,例如在网络上传送数据的时候,通常会通过多个服务器,而要知道特定的URL地址返回服务器上的数据。有些服务器会死机,有时会增加服务器的数量,总而言之,存储位置的数量在变。
使用常规哈希表,确保数据一致性的唯一方法如下:
1、获取每个键,包括哪些丢失位置的值
2、根据原来的位置数计算最初存储的值
3、将所有的数都移动到新的位置
4、按照新的要求重新计算所有的数
这是一个重新映射的过程,当你的存储位置发生变化时会采取这样的措施。例如,有2000个键分布在100个位置,现在其中一个位置丢失了,你需要将剩下的1800个键重新分布在剩下的99个位置上。那么,有没有更简单的做法?
Yes,更简单的做法
一致哈希的发明就是为了解决存储位置不断发生变化的问题。简而言之,一致哈希的实施过程如下:
1、取消一个位置只保存一个值的做法,让一个位置 存储来自多个键的值
2、不连续编码存储位置,给它们分配0到无穷的随机数
3、不计算“哈希数%存储位置数”,找到比哈希数大的最小位置数,将数放在那
4、如果你的哈希数大于所有的存储位置,将其放在最低编号的位置
例如,随机给出1,20,41,1024,2016五个存储位置,假定哈希数为1013,那么将其代表的数放在1024这个存储位置;如果哈希数为2017,则将其放在编号为1的存储位置。
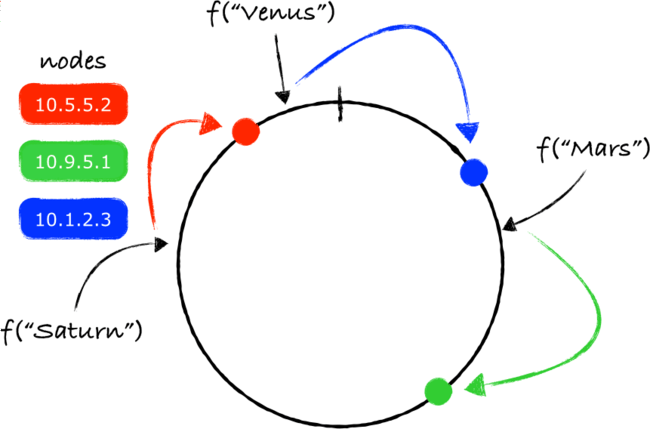
为什么这样的做法更好呢?下面来看下具体的过程:
1、将开始随机生成的五个存储位置中的1024去掉,这样只剩下1,20,41,2016这四个了
2、所有大于2016的哈希数都存储在位置为1的位置,不用改变
3、所有比20,41,2016略小的哈希数仍在这些位置,也不需要改变
4、只有比41大比1024小的哈希数需要改变,这个新的最小位置是2016,所以它们会存储在2016这个新位置。
与上一个例子不同的是,现在你只需要改变20个数的位置即可。
这就是一致哈希的优点,当一个存储位置消失后,不必对所有的数据都进行操作。对于那些经常改变存储位置的数据,现在你可以不用再担心了。
重要说明
现在你应该理解一致哈希的过程了,有一些说明还是必要的:
1、一致哈希不能解决寻值的问题,它只知道这些值最有可能存储在哪里。因为一个位置能存储多个值,一旦一个键确认了存储位置,需要额外的操作来返回具体的位置。在这个例子中,存储位置可能是服务器,当键值通过一致哈希来查找时,服务器会搜寻比它小的哈希数来返回数值。
2、实际中,每个存储位置的值并不是随机生成的,相反,它们都有个名称,而且这个名称是根据哈希算法得到的有效随机数,因此才被称为一致哈希。这样做简化了很多细节,当然,也可以生成纯随机数,不过这都属于高级优化的过程了。
怎样实现一致哈希环
这是这篇文章的技术部分,首先考虑我们的需求:
1、需要一个能搜寻数值的结构
2、需要一个能维持排序顺序的结构
当使用二分法搜索时,两个基本数据结构应该符合上面准则:
1、排序列表
2、二叉搜索树
对于给定的排序列表,工作流程如下:
1、创建一个空结构
2、给定服务器主机名,对其进行哈希并返回数值
3、在列表中插入数值,并将服务器的名称保存在其他地方
4、如果主机名被删除,只需将其从当前位置弹出
5、如果添加了主机名,则按其排序顺序将旧的主机名经过哈希变换后放置在新位置
6、给定一个键值,计算它的哈希数并使用二分法搜寻找到最近的哈希数,返回主机名
以上就是所有的过程。
在这篇文章中,我选择用二叉搜索树来达到目的,这里有很多原因,最重要的是想避免任何比python更复杂的东西,想高效的使用排序列表可以用python的bisecct。所以,毫无疑问下面是一个简单的递归算法;
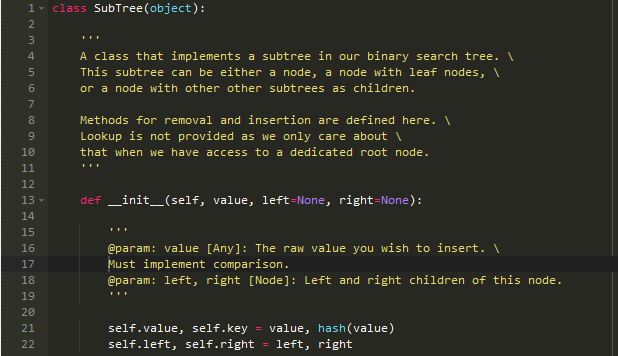
处理插入节点的代码;
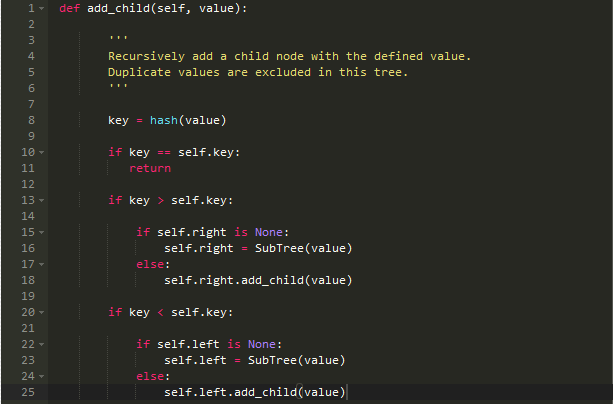
处理删除节点的代码(find_in_order_successor()只是找到下一个较高值的键):
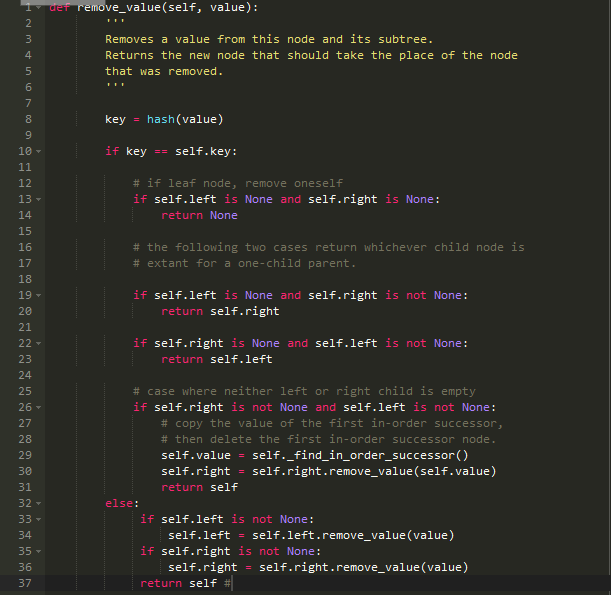
现在我们有一个基本的二叉搜索树,可以实现我们的哈希环:
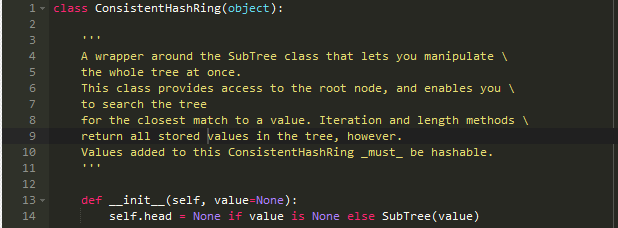
位置添加和删除已经完成,只需合理的调用即可:
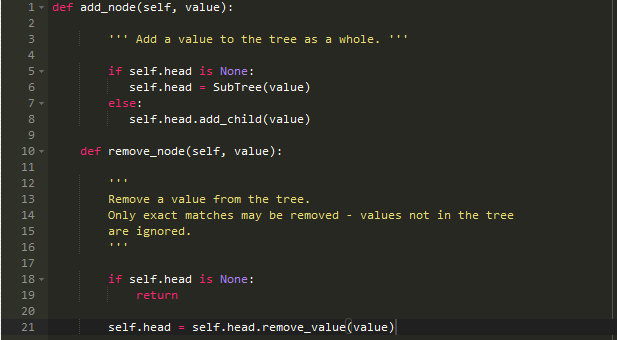
最重要的部分在于如何找到最近的值:
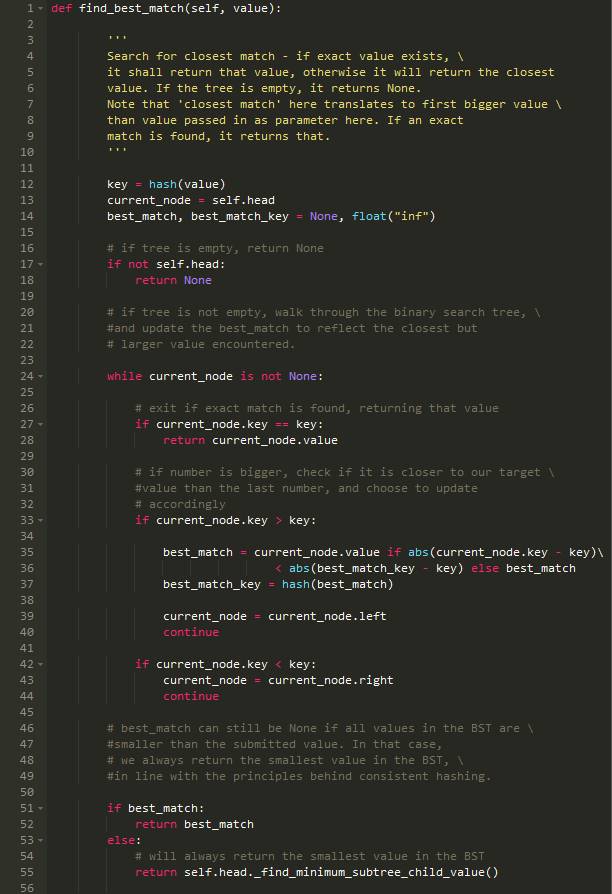
以上为止就是全部的过程,希望至此你已经理解了一致哈希环的原理。更具体的可以看我的Git仓库来完成测试:
https://github.com/AkshatM/ConsistentHashRing
欢迎随时交流!!!
英文原文:https://akshatm.svbtle.com/consistent-hash-rings-theory-and-implementation
译者:易水寒










