
来源 | 黑智(ID:VR-2014)
文 | 杨洁
5月27日,经过一番苦战,柯洁今天再次战败。在历经约3个半小时的对弈后,柯洁投子认输,以0:3的成绩完败给了AlphaGo。比赛中,柯洁在局面不利时长时间离开,回来后又泪洒现场。赛后柯洁一度哽咽称:
它太完美我很痛苦,看不到任何胜利的希望。
实际上,无论柯洁在今天的棋局上表现如何,AlphaGo在5月23日和5月25日,连续两场战胜,
从前天起,这个结果已经就被锁定了。
在昨日还进行了配对赛和团体赛,而在团队赛中,中国的5位世界冠军联手群战AlphaGo,最后还是执黑254手中盘告负。
围棋领域,人类最强大的大脑,也终于宣告完败。
围棋比赛,看似离我们的生活还比较遥远。但是,我们又能不能把这场乌镇的全民关注的棋局,单纯看成一场娱乐的表演秀?
在有些人看来,似乎就是如此,我们还没有看到AlphaGo下围棋能够给我们带来何等改变。
但
对另外一些人来说,这是令人恐惧的开端。机器会和我们一样思考?
它比我们强大,不需要受情绪、感情和身体因素的影响,如果搭配一个强有力的大脑,还有什么是它不能做的?
我们可以思考的问题,还有很多。AlphaGo究竟因为什么而如此强大,人类在机器面前是否就全无可以反攻的余地;除了下棋之外,AlphaGo还想告诉我们什么,它究竟能给未来带来何等改变;以及,下一场,人类和机器,又将在什么战局中对峙?
对弈中的AlphaGo有多可怕?
我已经很拼了。能让AlphaGo的主机发烫一下也好啊。
——by:柯洁
今天的第三局,在上一局落败后,柯洁提出本局仍由他执白,哈萨比斯痛快地答应了。第三局柯洁“回归自然”,做回自己,不再受对手的影响。而AlphaGo在开局依然将第一手落在了右下角的位置上。双方前4手常规开局,但随后AlphaGo下出新手,柯洁开始长考,最终只能无奈脱先。
让我们再来回顾一下前几场棋局,以及AlphaGo让我们曾经吃惊的地方。
1、胜半目是AlphaGo刻意而为之?
第一场,柯洁执黑先行,以小目、三三开场。经过4小时17分37秒,289手的激战后,最后AlphaGo以1/4子取胜。尽管这是中国规则中最小的差距,但最可怕的是,赛后人们对此结果的猜测:赢半目,是AlphaGo故意设置好的?
第一局棋到中盘时,阿尔法狗已经领先差不多一个贴目。但是之后,它采取了保守的下法,没有寸土必争。在赛后点棋的时候,柯洁就苦笑表示:“
我很早就知道自己要输1/4子,AlphaGo每步棋都是匀速,在最后单官阶段也是如此,所以我就有时间点目。
”
独立IT评论人keso就在赛后第一时间评论表示这可能是AlphaGo特意而为之。

但业界对此也有不同的看法。毕竟,对于电脑而言,AlphaGo被设定的目标就是胜利,而不是“赢几目”。AlphaGo给自己的命令,是用最稳妥的方法去赢,哪怕只是赢半目。极客帮创投合伙人蒋涛就认为,这一说法尚不能证实。但是,他也同样认可,“
最后能够出现这么细微的局面,说明棋局是在AlphaGo的掌控之中的。毕竟它要确保的,是结果的胜利。至于胜1目还是胜10目,对电脑来说判断都是一样的。
”
2、效仿对手开局?评价柯洁近乎“完美”
5月25日,第二局比赛进行。
而比第一战更加出乎人意料的是,比赛进行到当天中午13:37时,柯洁主动投子认输,AlphaGo提前一个多小时,中盘取胜。
在第二局,AlphaGo执黑先行。而它在落子前,不同以往地经过了思索,最后选择了第一局柯洁采用的小目、三三开局。
这是颇有意味的。要知道,AlphaGo公开问世以来到本次人机大战之前,一共下了70局,包括与樊麾的5局、与李世石的5局、以Master网名在网上下的60局。这70局里,没有一局开局就走了三三。
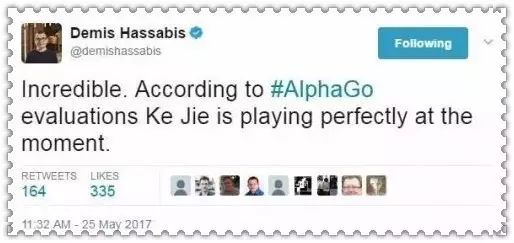
而柯洁在本场,则相对更加的沉稳。可以看出,柯洁在布局的策略上,本局下了更大的功夫。甚至在前面十几手,能够预料到AlphaGo多步棋的落子。比赛进行到1小时的时候,DeepMind创始人、AlphaGo之父哈比萨斯在自己的推特写道:“
简直不敢相信,根据AlphaGo的判断,柯洁现在下得非常完美。
”
之前一直有AlphaGo不擅长打劫的传言,但本局中,面对柯洁引爆的劫争,AlphaGo处理得非常得当,根本没有回避打劫之举。
在左下角的劫争中,柯洁的一步失误,顿时让局势无可挽回。柯洁在进行了近20手的尝试后,于155手投子认输。
这一局棋的震动也是无可比拟的。在赛后发布会上,双方都承认,当天的棋局,在前面,AlphaGo根本没有显示出胜率优势。DeepMind方也表示:“
柯洁在比赛中拥有了很多机会,AlphaGo一度无法处理……我们作为开发者,从来没有见过AlphaGo出现这么势均力敌的情况。
”
这可以说是,迄今为止,人类棋手在和AlphaGo的对弈中,最精彩的一局。
3、面对劣势时AlphaGo怎么办?认输、逼队友认输……
之后的最有趣和最令人懵逼的一幕,则出现在昨日的配对赛中。这场赛制规定,两名中国棋手古力、连笑将分别和AlphaGo组队,双方对垒。
之前,很多人猜测过,AlphaGo会不会有故意输掉比赛、或者下臭棋的可能。那么,当AlphaGo真正面对劣势时,它是怎么处理的?这场比赛或许会告诉你答案。
在对决即将结束之时,与古力搭档的AlphaGo决定投子认输,古力却拒绝了AlphaGo的要求,仍坚持鏖战。而之后,
AlphaGo的棋路变得越来越消极,最终,古力在不可逆转的情势下,也只得认输。
不管你如何认为,但明显,AlphaGo已经成为了控制棋局的关键。
现在的AlphaGo有多强大?
或许,关于AlphaGo的很多问题,可以在DeepMind对其算法的讲解中得到解释。
早在去年,AlphaGo就已经以4:1战胜过李世乭。而在今年年初,Master横空出世,在弈城和野狐两大围棋网站上,和各国顶尖棋手快棋对弈,最后以60:0的战绩横扫棋坛。而赛后,Master自揭真身,正是AlphaGo的最新版本。
而这次在乌镇和柯洁对弈的,正是Master。年初的对弈中,柯洁已经在快棋上,败给了它。
AlphaGo Master和战胜李世乭的AlphaGo Lee相比,有哪些区别?第一局赛后,DeepMind首席科学家席尔瓦在演讲中透露,去年与李世乭对战的AlphaGo Lee有50个TPUs在运作,搜索50个棋步为10000个位置/秒,而昨天打败柯洁的AlphaGo Master则是在单个TPU上进行游戏,计算量只是去年那个版本的十分之一。
和柯洁对战的是年初战胜60位高手的AlphaGo Master。
目前的AlphaGo是单机版,
配备了4块TPU。
与去年3月与李世石的比赛时相比,当前的版本在处理计算时所消耗的能量仅为过去的十分之一。


目前,与柯洁对战的AlphaGo Master的等级分已经接近了4800分。
现在的AlphaGo采用强化学习,让人工智能进行自我博弈,产生更强的神经网络。这一次AlphaGo用自我对弈训练出的策略网络,可以做到不需要更多运算,直接给出下一步的决策。
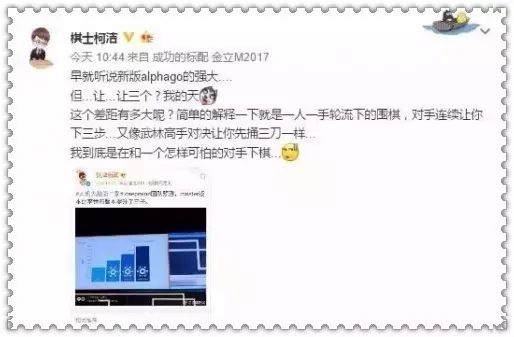
相比之下,现在的AlphaGo比去年击败了李世石那一版的AlphaGo Lee相比要“强三子”。
4块TPU,单机版,完虐了人类。而“强三子”的概念是什么?让柯洁的反应来告诉你。
如果说打败了李世乭的AlphaGo是利用卷及神经网络,让它了解规则、了解棋局,从而进行处理,那么,现在的AlphaGo,就增强了“思考”能力,并且,可以自学成才了。
在这次赛前,很多媒体报道,此次参战的 AlphaGo 2.0 可能采用了全新的算法模型,放弃了监督学习,即未先学习人类棋谱的经验,而是直接通过对战来获得认知和能力。
哈比萨斯在赛后发布会上回答,这明显是个误解。AlphaGo还是要学习人类经验,但这个版本的AlphaGo更依赖自我博弈来学习。
如何让AlphaGo进行监督学习和强化学习,席尔瓦解释,是让AlphaGo先通过训练形成一个策略网络,将棋盘上的局势作为输入信息,并对所有可行的落子位置生成一个概率分布。然后,训练出一个价值网络,以 -1(对手的绝对胜利)到1(AlphaGo的绝对胜利)的标准,预测所有可行落子位置的结果。也就是说,在这个过程中,
AlphaGo不仅会算出自己的最优选项,还会根据自己下过的棋,经过多层处理形成一个“值”,值高意味着自己赢,低意味着对手赢,并在棋局中的某一步判断是否是关键的一步。
并且,AlphaGo的搜索算法能在计算能力之上,加入和人类直觉近似的判断,让它更接近人脑。
为什么选棋牌?
那么,为什么科学家都执着于让机器和棋牌类游戏过不去呢?让一个电脑学会下棋,对我们究竟有什么好处?
原因很简单。
首先,棋牌类是人类智力活动的象征,它的宣传和号召能力自然也是其他运动所不能比拟的。
其次,自然是因为棋类非常适合作为AI算法的标杆。
机器和人对弈,是一个博弈的过程,它具有抽象的特性,而棋牌游戏的规则非常明确,状态显示则比较明确。
而在棋牌类中,围棋是非常难以攻克的一类。我们都知道,搜索算法的复杂程度取决于分支系数——每一步棋可能的走法。相比起来,国际象棋的平均分支因子大约是35,而围棋的平均分支因子为250,一局步数为350步,搜索树有250^350个节点,需要更加复杂和先进的搜索算法。在1997年之前,就没有出现过有竞争力的围棋程序。
而
战胜众多棋手的AlphaGo,使用的是蒙特卡洛树搜索算法
,借助值网络(value network)与
策略网络
(policy network)这两种深度神经网络,通过值网络来评估大量选点,并通过策略网络选择落点。
神经网络系统是以人类大脑为原型的信息处理模式,可以根据特定的输入产生特定输出,并实现图片识别、语音识别等功能。
谷歌做了两个神经网络,一个神经网络用于动态评估——计算对手下一步棋落子的各自可能性,依靠计算机远远超过棋手的计算能力,在某种程度上会占据一定优势。另一个神经网络用于静态评估——评估棋局交战双方总体态势。
谷歌输入了海量棋谱,让AlphaGo以此为基础进行了难以计数的自我对局,以丰富其数据库,预测对手的落子。
AlphaGo胜利后,今年1月,在美国宾夕法尼亚,卡内基梅隆大学开发的德州扑克人工智能系统Libratus击败了四名顶尖人类高手,一举获得了20万美元将近和177万美元筹码。
德扑和AlphaGo所擅长的围棋不同。围棋、国际象棋和西洋双陆等被AI逐个攻破的游戏,都是“完美信息”游戏。也即是,所有玩家在游戏中,能够获得公开和对称的确定信息。游戏中需要作出的决策点的数量,决定了机器的计算量。
而与之相比,
德扑则是“不完整信息”游戏。
其中包含了更多的隐藏信息,每个玩家掌握的信息都是不对称的,他只能看到自己的牌,却不知道对手的牌,需要根据直觉推测对手手牌,选择下注和放弃,并判断对手的打法。因此,“不完整信息”博弈,就成为难以攻克的计算机难题。
而Libratus,基于在匹兹堡超级计算中心大约1500万核心小时的计算,用算法分析德扑规则,预测所有步骤的胜率,来进行自己的下一步。和AlphaGo用大量棋局做训练不同,它没有用专业牌局进行神经网络训练,而是用随机生成的牌局(随机产生公共牌、底池筹码、玩家拿牌概率)和尝试性的动作带来的结果(在随机生成的输入情况下模拟玩家跟牌后的结果)来作为训练数据。Libratus还采用了博弈论,它通过纳什均衡来计算如何应对对手的招数,通过平衡风险和收益,对自身的下一步进行修正,以期达到收益最大化。其程序名Libratus,就是来源于拉丁文“制衡”。
是的,所以,你知道,风靡我国的“国民运动”麻将,就是不完美信息博弈的一种。目前虽然已经有比较强的AI,但是和人类顶尖高手相比,还是有较大的差距。
柯洁之后,或许我们可以期待一场高水平的麻将人机大赛。
但
据微软亚洲研究院研究员杨懋和秦涛的文章,最难被AI攻克的,还是星际争霸和我的世界这类游戏。它们不仅信息不对称,而且游戏规则是开放性的。除了运行速度上占优势外,计算机还还需要处理不断出现的复杂的新情况。
现在,计算机还没有在这些游戏中证明过自己的能力。
AlphaGo下完棋能做什么?
“AlphaGo 赢了李世石,so what?下围棋本来的乐趣就是对方下一把臭棋,结果机器不会下臭棋,那还有什么意思呢?”
——by:马云
所以,我们可以意识到,棋牌类游戏,对于人工智能而言,是一种早期的演练。或许它能够让游戏更有趣味,会挑战专业棋手的价值,会引发很多人的思考和恐惧,但是,AlphaGo,或者说DeepMind,它的最终目标不仅仅是下棋。DeepMind的最终目标,还是智能助手、医疗和机器人等领域。
谷歌现在有两套人工智能系统,包括谷歌的机器学习开发者工具TensorFlow,以及DeepMind的AlphaGo系统,AlphaGo未来将计划应用在医疗看护、自动驾驶车等部分。
在乌镇的人工智能峰会上,Alphabet 董事长 Eric Schmidt谈到机器学习和人工智能引领了“智能时代”的发展,他表示:“
神经网络和深度学习的爆发是我所经历过的最大变革
”。他还表示,这些新技术不仅提升了日常的生产效率,更为企业带来了无限机遇,尤其是在“医疗、交通以及政务”等领域。而谷歌的各项AI研究成果,也在这场交流中向国内观众做了完全的展示。
比如
机器学习在消费产品中的应用
,包括 Google Photos以及Gmail。以 Google Photos最新版本为例,通过机器学习技术,可以将照片中的雨滴去除,并为照片添加滤镜,使其拥有与知名艺术作品一般的效果。
还比如,
如何利用电脑工具帮助缺乏医疗资源的国家更广泛地进行眼疾诊断
,这其中就包括了印度。印度拥有13亿人口,总计缺少 127,000 名眼科医生。Google 的机器学习模型诊断眼疾的准确率,甚至略微高于一些通过美国认证委员会认证的眼科医生。这个技术还有很大的潜能可以应用到其它疾病的诊断,例如斯坦福的研究者近期已经开始使用 TensorFlow 利用图像进行皮肤癌的诊断。
TensorFlow 是现在 GitHub 上世界第一的机器学习知识库,其使用增长率远远高于其它同类型平台。比利时公司Connecterra 就将TensorFlow 应用到了牧场当中,而澳大利亚的研究者则将此项技术用于判断海牛种群的健康状况。
Google 翻译也用到了
TensorFlow
。随着神经网络机器翻译的引入,翻译结果有了显著提高。同时,结合了“计算机视觉”使得 Google 翻译 App 能够利用手机摄像头进行即时图像翻译,这项功能正是通过TensorFlow 在移动设备上的版本来实现的。在文艺领域,还有“Portrait Matcher” ,一个可以利用摄像头将你的面部特征与类似艺术品匹配的功能。
柯洁战后说:“未来是人工智能的。”而人工智能,终究是人类所开发的。
暂时我们也不必担忧,人类将被机器所完全取代和统治。李开复的答案是,人工智能目前只有在符合以下三个前提的领域里,将全面战胜人类:
第一,有海量的数据;
第二,数据有标准;
第三,单一领域。
在前不久的IT领袖峰会上,李彦宏也说:“
强人工智能时代,也许永远不会到来。
”
也许,机器并不值得我们去恐惧。但真正可怕的事实,其实是,我们并不知道,人类会将它推向哪一步……
*本文系黑智(ID:VR-2014)









