在字节跳动内部,Presto 主要支撑了Ad-hoc查询、BI可视化分析、近实时查询分析等场景,日查询量接近100万条。本文是字节跳动数据平台Presto团队-软件工程师常鹏飞在PrestoCon 2021大会上的分享整理,分两次连载。
字节跳动Presto团队持续招聘中,
点此内推
在字节跳动内部,Presto主要支撑了
Ad-hoc
查询、BI可视化分析、近实时查询分析等场景,日查询量接近100万条。
完全兼容SparkSQL语法,可以实现用户从SparkSQL到Presto的无感迁移;
实现Join Reorder,Runtime Filter等优化,在TPCDS1T数据集上性能相对社区版本提升80.5%;
首先,实现了多Coordinator架构,解决了Presto集群单Coordinator没有容灾能力的问题,将
容灾恢复时间控制在3s以内
。
其次实现了基于histogram的静态规则和基于运行时状态的动态规则,可以有效进行集群的路由和限流;
实现了History Server功能,可以支持实时追踪单个Query的执行情况,总体观察集群的运行状况。

字节跳动OLAP数据引擎平台
Presto部署使用情况
过去几年,字节跳动的OLAP数据引擎经历了百花齐放到逐渐收敛,再到领域细分精细化运营优化的过程。
存储方面离线数据主要存储在HDFS,业务数据以及线上日志类数据存储在MQ和 Kafka。
计算引擎根据业务类型不同,Presto支撑了Ad-hoc查询、部分BI报表类查询,SparkSQL负责超大体量复杂分析及离线 ETL、Flink 负责流式数据清洗与导入。
为了处理日益增长的Ad-hoc查询需求,在2020年,字节跳动数据平台引入Presto来支持该类场景。
目前,整个Presto 集群规模在几万 core,支撑了每天约100万次的查询请求,覆盖了绝大部分的Ad-hoc查询场景以及部分BI查询分析场景。
上图是字节跳动内部 Presto集群部署的架构,针对不同的业务需求拆分为了多个相互隔离的集群,每个集群部署多个Coordinator,负责调度对应集群的 Worker。
接入层提供了统一的Gateway,用以负责用户请求的路由与限流。同时还提供了 History Server,Monitor System等附属组件来增加集群的可运维性与稳定性。
Presto 集群稳定性和性能提升
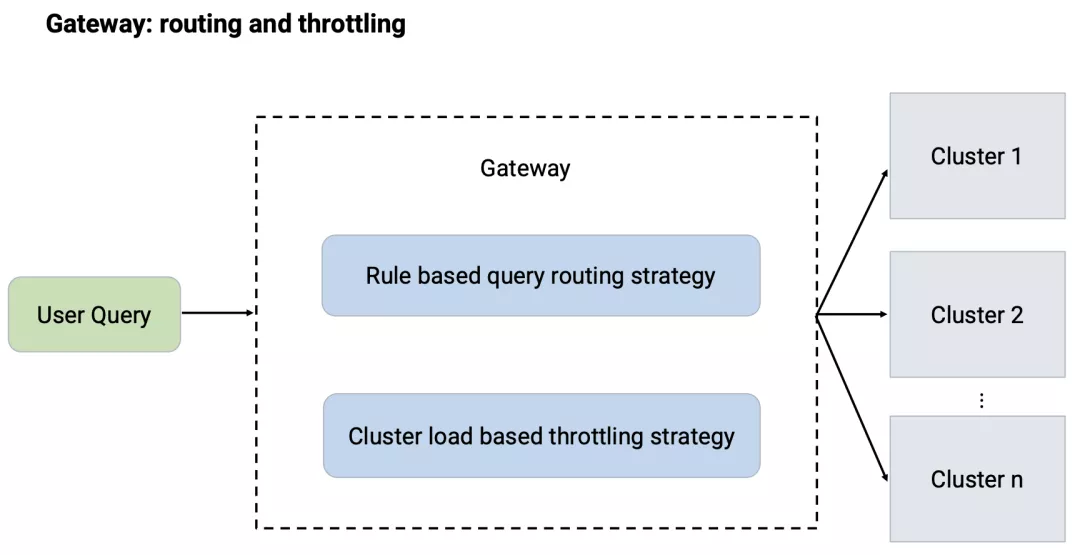
针对不同的业务场景以及查询性能要求,我们将计算资源拆分为了相互独立的 Presto集群。
Gateway负责处理用户请求的路由,这部分功能主要通过静态的路由规则来实现,路由规则主要包括允许用户提交的集群以及降级容灾的集群等。
为了更好的平衡不同集群之间的负载情况,充分有效的利用计算资源,后期又引入了动态的路由分流策略。该策略在做路由选择的过程中会调用各个集群 Coordinator的Restful API获取各个集群的负载情况,选择最优的集群进行路由调度。
通过静态规则与动态策略相结合的方式,Gateway在为用户提供统一接入接口的情况下,也保证了集群之间工作负载的平衡。
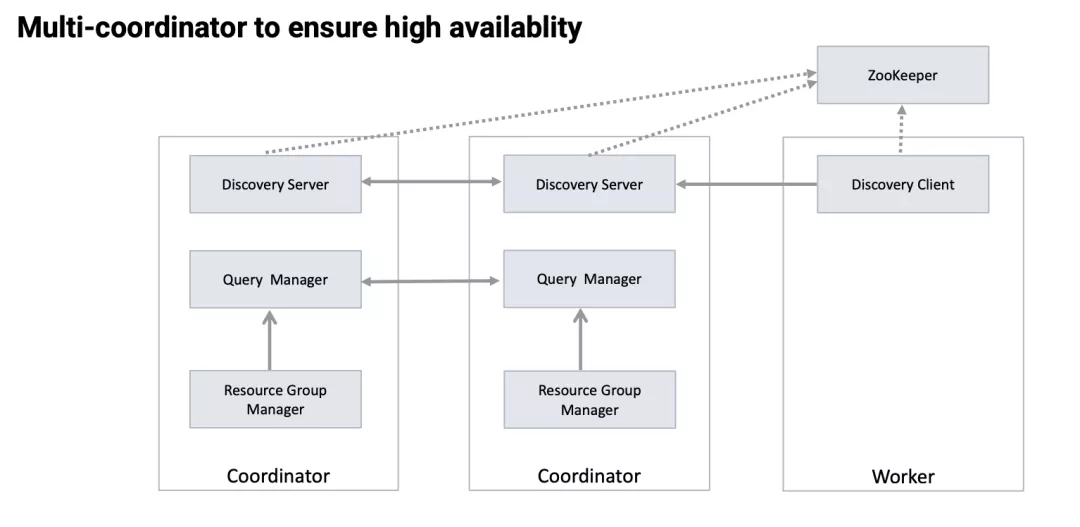
Coordinator 节点是单个 Presto集群的核心节点,负责整个集群查询的接入与分发,因此它的稳定性直接影响到整个集群的稳定性。
在最初的部署中,每个Presto集群只能部署一个Coordinator,当该节点崩溃的时候,整个集群大概会消耗几分钟的不可用时间来等待该节点的自动拉起。
为了解决这个问题,我们开发了多Coordinator的功能。该功能支持在同一个 Presto 集群中部署多个Coordinator 节点,这些节点相互之间处于active-active备份的状态。
主要实现思路是将Coordinator和Worker的服务发现使用Zookeeper来进行改造
。
Worker 会从 Zookeeper获取到现存的Coordinator并随机选取一个进行心跳上报,同时每个 Coordinator也可以从Zookeeper感知到其他Coordinator的存在。
每个 Coordinator负责存储当前连接到的Worker的任务负载情况以及由它调度的查询执行情况,同时以Restful API的形式将这些信息暴露出去;其他Coordinator在做任务调度的时候会通过这些 Restful API获取到整个集群的资源使用情况进行相应的任务调度。
目前多Coordinator机制已经在集群中上线使用了半年,将集群的不可用时间
从几分钟降低到3s以内
。
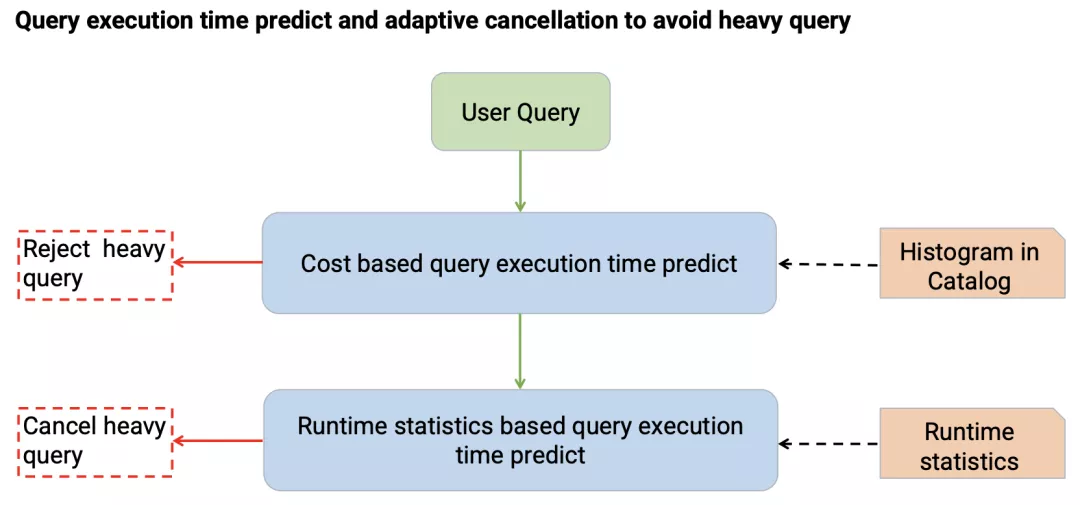
另一个影响Presto集群稳定性的重要因素是超大规模的查询。
在Ad-hoc场景下,这种查询是无法避免的,并且由于这种查询会扫描非常多的数据或者生成巨大的中间状态,从而长期占用集群的计算资源,导致整个集群性能下降。
为了解决这个问题,我们首先引入了
基于规则以及代价的查询时间预测。
基于规则的查询时间预测主要会统计查询涉及到的输入数据量以及查询的复杂程度来进行预测。
基于代价的查询时间预测主要是通过收集在 Catalog 中的Histogram数据来对查询的代价进行预测。
上述预测能够解决部分问题,但是还是会存在一些预估不准的情况,为了进一步处理这些情况,我们
引入了Adaptive Cancel
功能。
该功能主要是在查询开始执行后,周期性的统计查询预计读取的数据量以及已完成的任务执行时间来预测查询整体的执行时间,对于预测超过阈值的查询提前进行取消,从而避免计算资源浪费,提升集群稳定性。
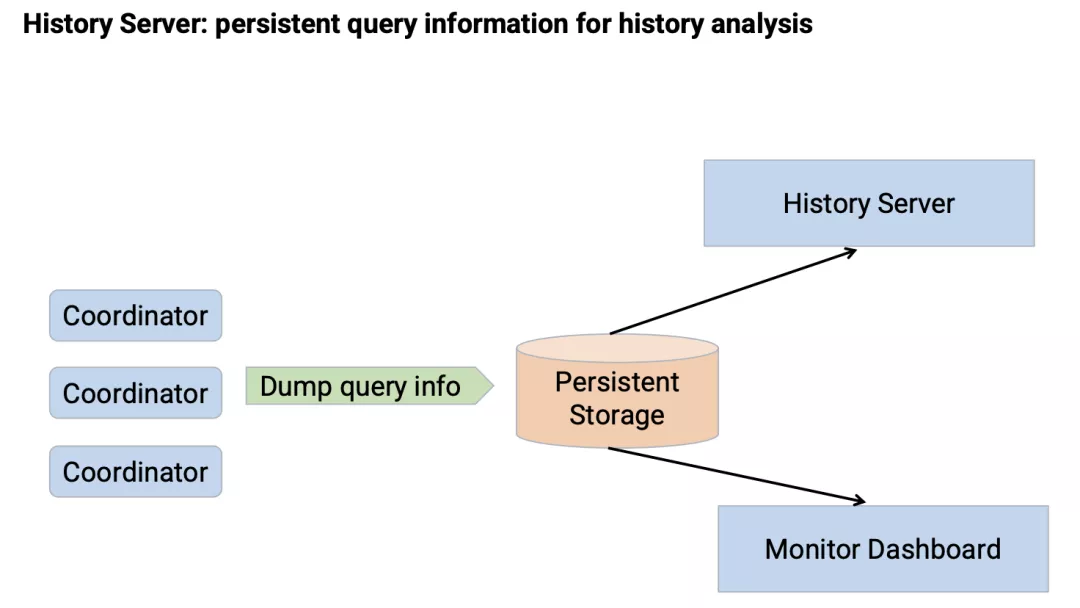
另外,Presto 本身提供的UI界面可以很好地对查询执行情况进行分析,但是由于这部分信息是存储在Coordinator内存当中,因此会随着查询数量的累积而逐步清除,从而导致历史查询情况无法获取。
为了解决这个问题,我们
开发了History Server
的功能。
Coordinator在查询执行完成之后会将查询的执行情况存储到一个持久化存储当中,History Server会从持久化存储当中加载历史的查询执行情况并提供与 Presto UI完全相同的分析体验,同时基于这部分持久化的信息,也可以建立相应的监控看板来观测集群的服务情况。










