
本文将以 Alex-Net、VGG-Nets、Network-In-Network 为例,分析几类经典的卷积神经网络案例。
在此请读者注意,此处的分析比较并不是不同网络模型精度的“较量”,而是希望读者体会卷积神经网络自始至今的发展脉络和趋势。
这样会更有利于对卷积神经网络的理解,进而举一反三,提高解决真实问题的能力。
01
Alex-Net 网络模型
Alex-Net 是计算机视觉领域中首个被广泛关注并使用的卷积神经网络,特别是 Alex-Net 在 2012 年 ImageNet 竞赛 中以超越第二名 10.9个百分点的优异成绩一举夺冠,从而打响了卷积神经网络乃至深度学习在计算机视觉领域中研究热潮的“第一枪”。
Alex-Net 由加拿大多伦多大学的 Alex Krizhevsky、Ilya Sutskever(G. E.
Hinton 的两位博士生)和 Geoffrey E. Hinton 提出,网络名“Alex-Net”即
取自第一作者名。
关于 Alex-Net 还有一则八卦:由于 Alex-Net 划时代的意义,并由此开启了深度学习在工业界的应用。
2015 年 Alex 和 Ilya 两位作者连同“半个”Hinton 被 Google 重金(据传高达 3500 万美金)收买。
但为何说“半个”Hinton? 只因当时 Hinton 只是花费一半时间在 Google 工作,而
另一半时间仍然留在多伦多大学。
下图所示是 Alex-Net 的网络结构,共含五层卷积层和三层全连接层。其中,Alex-Net 的上下两支是为方便同时使用两片 GPU 并行训练,不过在第三层卷积和全连接层处上、下两支信息可交互。
由于两支网络完全一致,
在此仅对其中一支进行分析。下表列出了 Alex-Net 网络的架构及具体参数。
单在网络结构或基本操作模块方面,Alex-Net 的改进非常微小,构建网络的基本思路变化不大,仅在网络深度、复杂度上有较大优势。

图1 Alex-Net 网络结构
Alex-Net 网络架构及参数
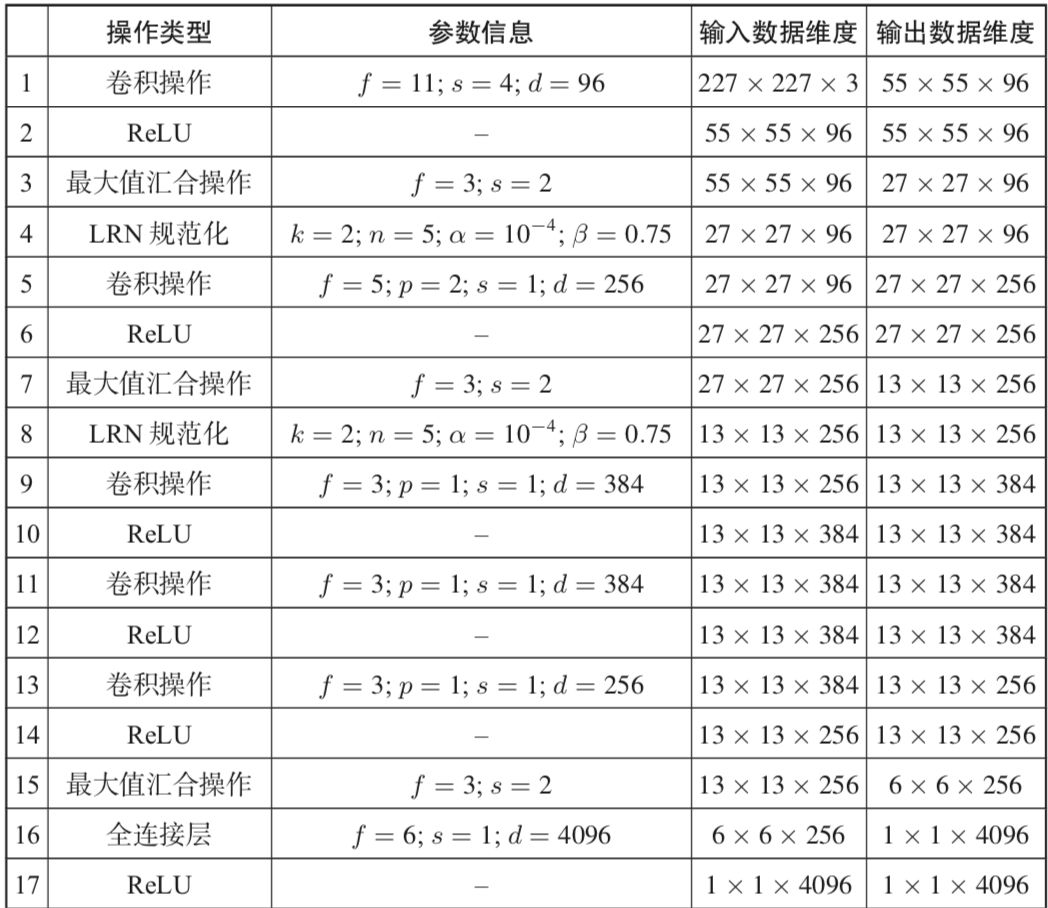

不过仍需指出 Alex-Net 的几点重大贡献,正因如此,Alex-Net 方可在整个卷积神经网络甚至连接主义机器学习发展进程中占据里程碑式的地位。
Alex-Net 首次将卷积神经网络应用于计算机视觉领域的海量图像数
据集 ImageNet(该数据集共计 1000 类图像,图像总数约 128 多
万张),揭示了卷积神经网络拥有强大的学习能力和表示能力。
另一方面,海量数据同时也使卷积神经网络免于过拟合。可以说二者相辅相成,缺一不可。自此便引发了深度学习,特别是卷积神经网络在计算机视觉领域中“井喷”式的研究。
利用 GPU 实现网络训练。在上一轮神经网络研究热潮中,由于计算资源发展受限,研究者无法借助更加高效的计算手段(如 GPU),这也较大程度地阻碍了当时神经网络的研究进程。
“工欲善其事,必先利其器”,在 Alex-Net 中,研究者借助 GPU 将原本需数周甚至数月的网络训练过程大大缩短至 5~6 天。
在揭示卷积神经网络强大能力的同时,这无疑也大大缩短了深度网络和大型网络模型开发研究的周期并降低了时间成本。缩短了迭代周期,正是得益于此,数量繁多、立意新颖的网络模型和应用才能像雨后春笋一般层出不穷。
一些训练技巧的引入使“不可为”变成“可为”,甚至是“大有可为”。如 ReLU 激活函数、局部响应规范化操作、为防止过拟合而采取的数据增广(data augmentation)和随机失活(dropout)等。
这些训练技巧不仅保证了模型性能,更重要的是为后续深度卷积神经网络的构建提供了范本。实际上,此后的卷积神经网络大体都遵循这一网络构建的基本思路。
局部响应规范化(LRN)要求对相同空间位置上相邻深度(adjacent
depth)的卷积结果做规范化。
假设
a
d
i,j
为第 d 个通道的卷积核在 (i, j) 位置处的输出结果(即响应),随后经过 ReLU 激活函数的作用,其局部响应规范化的结果
b
d
i,j
可表示为:
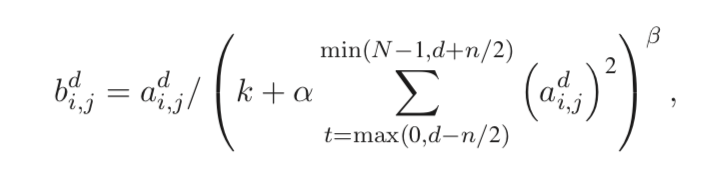
其中,n 指定了使用 LRN 的相邻深度卷积核数目,N 为该层所有卷积核数目。k、n、α、β 等为超参数,需通过验证集进行选择,在原始 Alex-Net中这些参数的具体赋值如上表所示。
使用 LRN 后,在 ImageNet 数据集上Alex-Net 的性能分别在 top-1 和 top-5 错误率上降低了 1.4% 和 1.2%;此外,一个四层的卷积神经网络使用 LRN 后,在 CIFAR-10 数据上的错误率也从 13% 降至 11%。
LRN 目前已经作为各个深度学习工具箱的标准配置,将 k、n、α、β等超参数稍做改变即可实现其他经典规范化操作。如当 “k = 0,n = N,α = 1,β = 0.5”时便是经典的 l2 规范化:
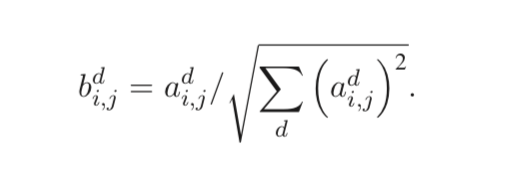
02
VGG-Nets 网络模型
VGG-Nets 由英国牛津大学著名研究组 VGG(VisualGeometryGroup)
提出,是 2014 年 ImageNet 竞赛定位任务 (localization task) 第一名和分类
任务第二名做法中的基础网络。









