 我 相 信 这 么 优秀 的 你
我 相 信 这 么 优秀 的 你
已 经 置 顶 了 我
翻译| 陈金鹿 选文| 小象
转载请联系后台
1. Håkon Hapnes Strand, 数据科学家
问:你认为记住高级公式在机器学习算法中很重要吗?
我不认为记住公式很重要。事实上,我觉得这甚至会产生反效果。如果您了解机器学习算法的工作原理,我的意思是在低级别上真正理解它,而不仅仅是高级直觉,那么您应该可以自己导出公式。在实践中,这是您几乎不需要做的事情,记住一个可以给你错觉的公式,你将难以理解原理。

2. Roman Trusov,Facebook AI研究实习生
问:你应该花钱买一个好的GPU来学习深度学习吗?(我不是指生产运行。)
你需要一个本地GPU平台吗?如果你认真学习数据传输链路,是的。了解架构或算法并使其正常工作是两个截然不同的层次,获取知识的唯一真正途径就是自己尝试并分析结果。
如果您考虑购买多个便宜的GPU来学习如何使用它们,不要这样做。如果您的框架支持分布式计算,它将以一种无阻碍的方式运行。如果它不运行,这将不是一个初学者的任务,这在后面通常是一种烦恼。
对于现代架构的培训,CPU不能以任何方式代替GPU。我有一个非常好的CPU,需要几个星期的时间训练我通常在一夜之间训练的网络。消费级i5(我不认为i7超支是个好主意)甚至更慢。

3. Zeeshan Zia,计算机视觉与机器学习博士
问:如何为计算机视觉研究科学家采访做准备?
有关于计算机视觉和机器学习的光线编程部分和基本问题,大约有一半的位置。在另一半,根本没有技术问题。通常情况下,如果您自己编程并定期参加会议,那么您不需要为此部分做好准备。如果真的需要,最多可以在几天内刷新C ++。
他们想知道的两件事情是:(一)你是否可以作为独立研究员工作,(二)你对软件开发工作的预期比例是否与软件开发工作相符。

4. Ian Goodfellow,AI研究员科学家
问:使用GAN生成图像有什么问题或动机?
您可以使用GAN 生成模拟训练数据和模拟训练环境,填写缺少的数据,训练具有半监督学习的分类器(分类器从标记和未标记的数据中学习,并且与GAN同时从完全虚构的数据中学习), 监督学习,监督信号表示多个正确答案中的任何一个可以接受,而不是仅仅提供一个具体的答案,您要求每个培训示例,用统计生成代替昂贵的模拟,来自生成模型的后验分布的样本,了解对其他任务有用的嵌入。

5. Clayton Bingham,在 Informatics 公司担任数据分析师,神经工程研究员
问:机器学习(深入学习之外)有什么趋势?
我不知道趋势,但我知道一个强大的方法,在主流ML之外,被证明具有巨大的灵活性,可解释性和在VLSI / FPGA硬件中相对容易实现的优势。
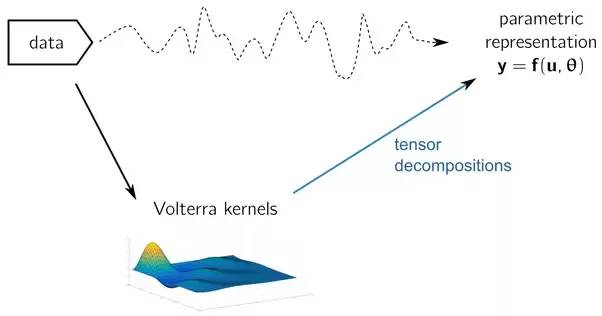
Volterra Kernels
了解Volterra系列如何工作的最简单的方法是估计一系列数字滤波器将从输入信号转换为适当的输出。卷积内核(滤波器)的形状,时间延迟和数量包括必须估计的模型的特征,以便对复杂系统的行为进行准确的预测。
6. Xavier Amatriain 前ML研究员,现在在Quora的领先工程
问:什么是训练机器学习模型的最佳实践?
指标:
您应该选择与产品目标相关的离线优化指标。很多时候,产品目标的良好代理可以是在线A / B测试结果或其他在线指标。
您只能通过运行不同的实验和跟踪离线指标,知道衡量标准与在线A / B测试相关
倾向于与排名相关问题相关的指标是召回@ n,NDCG或MRR(平均互惠等级)
一个很好的指标:

7. Chomba Bupe,开发机器学习算法
问:除了K最近的邻居还有分类方法,您可以添加类和训练样本,而无需重新训练所有数据?
是的,什么叫做转移学习?你几乎可以用任何机器学习(ML)算法,而不需要重新整理系统。例如,可以获得一个预先训练的网络,并在顶部添加一个额外的简单分类器,并且只对新的训练样本上的分类器进行训练,同时保持预训练的权重。这在相关任务的实践中表现良好。
然而,转移学习存在局限性,因为它的工作很好,我们需要确保新的样本具有与样品相似的分布。

8. Liang Huang,博士 宾夕法尼亚大学计算机科学系(2008)
问:在AI深入学习中,谁是继Hinton,Lecun和Bengio之后的顶尖研究人员?
这个问题被宣布是错误的。现在我们都知道,Schmidhuber的贡献与Hinton, LeCun, and Bengio的贡献是对等的,如果不是更重要的话,DL只有两个关键的想法
1.CNN(Fukushima-LeCun)2.LSTM(Schmidhube
其他一切,包括Hinton和Bengio的工作,都是次要的。
这并不是说那些并不重要,它们在推广NN方面是非常重要的,但如果你只是谈论诺贝尔奖总是说的“原创思想”,那么就是LeCun,更早的福岛和Schmidhuber。如果有DL的诺贝尔奖,那么应该去给这些人。

9.Yoshua Bengio,美国蒙特利尔大学教授
问:如何在机器学习中进行研究,只要有从Coursera或edX的MOOC获得的必要知识?
我不认为MOOC就够了。你需要认真练习 例如,尝试重现在您感兴趣的几篇论文中获得的结果,参加Kaggle比赛等。然后尝试加入其他学生和研究人员进行深入学习的学术实验室,作为访问者/实习生或研究生。

10. Shehroz Khan,ML研究员
问:计算科学家如何决定用于交叉验证的策略?
让我们考虑一个2类的问题和相同的分配培训和测试数据。K折交叉验证(CV)可能会失败,如果在折叠形成期间,验证集不包含来自负面类别的任何样本,训练集只包含正样本。
为了避免这种情况,您可能需要进行分层的K-fold CV,以确保训练和验证集中样本的比例。使用相同的学习方法和数据集的不同的10倍交叉验证实验经常产生不同的结果,因为随机变化对选择折叠本身的影响。分层减少变化,但不能完全消除它。
离开一次更好,因为您获得最大数量的培训; 然而,成本是需要的培训过多(对于1000个样本的数据,您必须做1000次)。当我们说数据是随机生成的时候,可能会出现一个非常戏剧化的情况,最好的一个分类器可以做的是预测大多数类,因此是50%的错误率。
但是,在每次休假一次的情况下,测试实例的相反类别是多数—因此预测总是不正确的,导致估计错误率为100%。离开一个不能分层,因为只有样本需要测试。通常,使用10次10次分层CV。

陈金鹿
来自吉林大学珠海学院通信工程,热衷于大数据、云计算开发,擅长数据挖掘和安卓开发。目前在珠海大横琴科技公司实习,负责云计算运维。











