国产AI大模型DeepSeek的产业影响力正在蔓延,16家国产AI芯片企业相继宣布适配或上架DeepSeek模型服务,包括华为昇腾、沐曦、天数智芯、摩尔线程等。同时,10家国内云计算巨头和至少12家独立云及智算企业也宣布了对DeepSeek的支持。此外,南京智算中心、浙东南智算中心均成功上线DeepSeek,并实现了零成本迁移和开箱即用。DeepSeek的影响正在深入AI产业全方位圈层,推动中国AI自主可控产业链的长远发展。
16家国产AI芯片企业相继适配或上架DeepSeek模型服务,覆盖华为昇腾、沐曦、天数智芯、摩尔线程等。
10家国内云计算巨头和至少12家独立云及智算企业宣布了对DeepSeek的支持,包括华为云、天翼云、腾讯云、阿里云等。
两个智算中心均实现了DeepSeek的零成本迁移和开箱即用,展示了DeepSeek在AI产业中的实际应用。
DeepSeek的影响正在深入AI产业全方位圈层,推动中国AI自主可控产业链的长远发展。


芯东西2月7日报道,国产AI大模型DeepSeek的产业影响力还在蔓延。短短7天内,
16家
国产AI芯片企业(华为昇腾、沐曦、天数智芯、摩尔线程、海光信息、壁仞科技、太初元碁、云天励飞、燧原科技、昆仑芯、灵汐科技、鲲云科技、希姆计算、算能、清微智能、芯动力)相继宣布适配或上架DeepSeek模型服务
。

▲截至2月7日,官宣支持DeepSeek模型的国产AI芯片企业(按时间顺序排列,智东西制表)
其中
海光信息
是科创板CPU+GPU上市公司,
云天励飞
是科创板AI上市公司,
昆仑芯科技
是百度旗下AI芯片公司,
燧原科技
、
壁仞科技
、
摩尔线程
、
沐曦
这4家AI芯片独角兽均已启动IPO进程。
云计算与智算企业也积极行动。
华为云、天翼云、腾讯云、阿里云、百度智能云、火山引擎、京东云、联通云、移动云、浪潮云等10家国内云计算巨头,
无问芯穹
、
硅基流动、云轴科技ZStack、PPIO派欧云、超算互联网、青云科技、算力互联、并济科技、优刻得、神州数码、并行科技、北京超算等至少12家独立云及智算
企业
,均宣布对DeepSeek的支持。
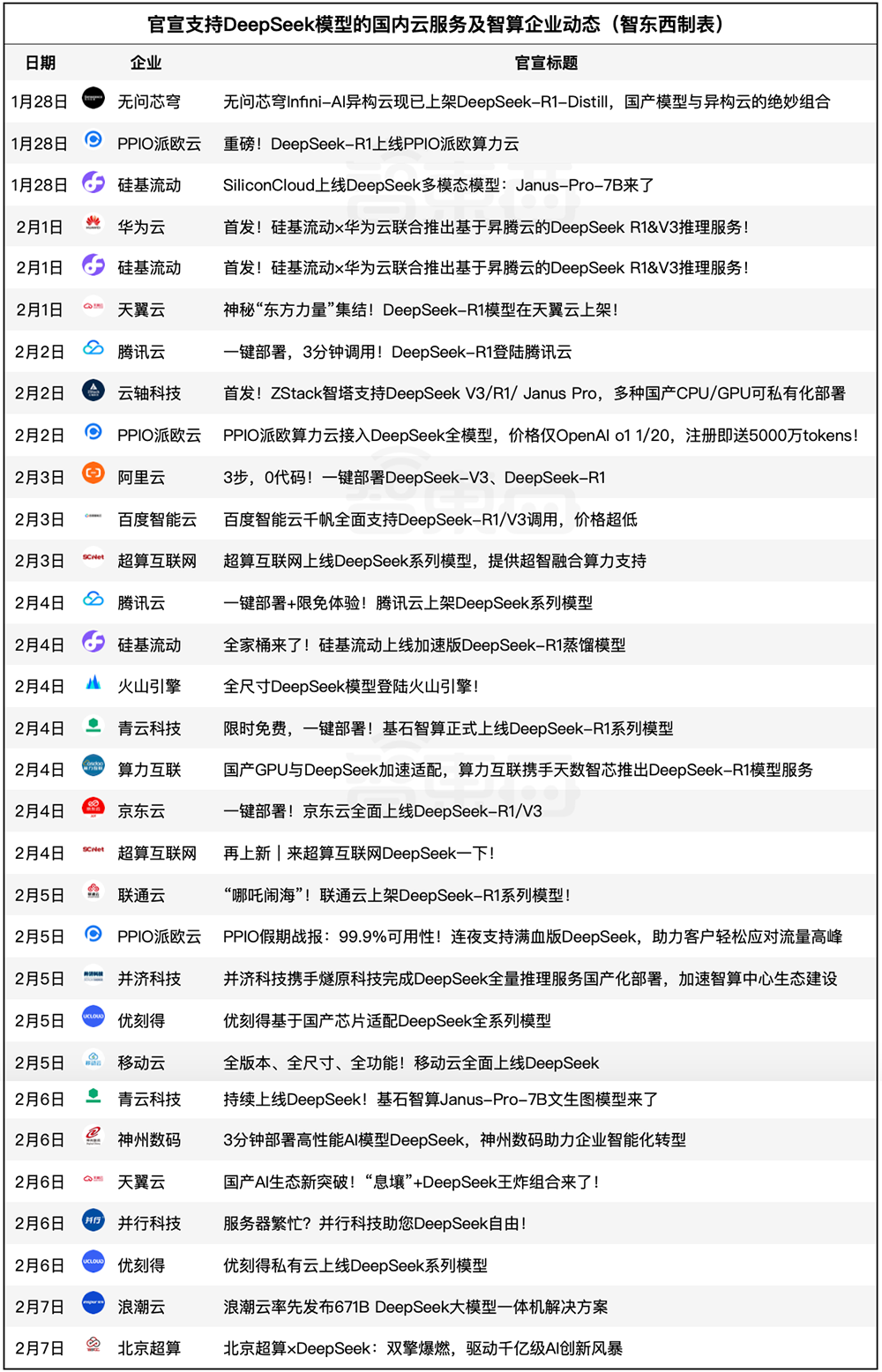
▲截至2月7日,官宣支持DeepSeek模型的国内云服务及智算企业(按时间顺序排列,智东西制表)
截至发稿时间,“科创板AI芯片第一股”寒武纪暂未发布DeepSeek有关讯息,而是在低调支持。南京智算中心、浙东南智算中心均在2月6日透露相应进展:
去年寒武纪全年股价涨势凶猛,成为年度股王,今年市值更是一度越过3000亿元大关,但在春节假期前后交易日股价连续下跌,2月7日才恢复涨势。海光信息股价则在连涨两日后转而下滑。并行科技、浪潮信息、神州数码、青云科技、优刻得等算力概念股均在春节假期后连收涨停板。

▲寒武纪、海光信息、并行科技、浪潮信息近5个交易日股价变化
港股上市公司金山云亦受DeepSeek热潮提振,股价在春节假期后的头两个交易日连续上涨。不过2月7日港股AI概念股普跌,金山云股价也出现回落。

▲神州数码、青云科技、优刻得、金山云近5个交易日股价变化
2月1日,华为昇腾打响国产AI芯片支持DeepSeek系列模型的第一枪。随后群雄毕至,15家独立AI芯片企业相继宣布支持DeepSeek的快速部署,乃至训练。
2月1日,华为云宣布与硅基流动联合首发并上线基于华为云昇腾云服务的DeepSeek R1/V3推理服务。得益于自研推理加速引擎加持,该服务支持部署的DeepSeek模型可获得
持平全球高端GPU部署模型
的效果。
2月4日,DeepSeek R1、V3、V2、Janus-Pro模型正式上线昇腾社区,支持一键获取DeepSeek系列模型,支持昇腾硬件平台上开箱即用,推理快速部署。
天翼云、联通云、移动云三大运营商云均已采用昇腾算力底座来支持DeepSeek模型。神州数码也特别提到其神州鲲泰推理服务器产品搭载昇腾硬件,可全面支持DeepSeek模型的快速部署。
国产GPU独角兽沐曦对DeepSeek的支持,由国内一站式大模型托管平台
Gitee AI
代为官宣。Gitee AI在2月2日宣布上线1.5B、7B、14B、32B四个尺寸的DeepSeek R1模型并均部署在国产沐曦曦云GPU上。

2月5日,Gitee AI再度发文,宣布经测试已确认DeepSeek-V3
全精度满血版(671B)可以成功运行在沐曦训推一体GPU
上,并将V3满血版上线到平台上。
同日,联想联合沐曦发布
基于DeepSeek大模型的首个国产一体机解决方案
。该方案以“联想服务器/工作站+沐曦训推一体国产GPU+自主算法”为核心架构,配合联想AI Force智能体开发平台,推出智能体一体机与训推一体服务器双产品形态。
面向敏捷部署的
DeepSeek智能体一体机
,采用ThinkStation PX工作站为载体,搭载沐曦曦思N260国产GPU,可支持本地部署DeepSeek各种参数蒸馏模型推理。
面向更广泛场景的
DeepSeek训推一体机
,基于联想问天WA5480 G3 AI服务器,搭载8张曦云C500国产GPU,可为大模型训练和推理提供强大的算力支撑。
浪潮云在2月7日发布的预置DeepSeek R1和V3模型的海若一体机时,也采用了沐曦的国产GPU。
2月4日,天数智芯与Gitee AI联合发布,在双方的高效协作下,
仅用时一天
,便成功完成了与DeepSeek R1的适配工作,并已正式上线多款大模型服务,包括1.5B、7B、14B等尺寸。
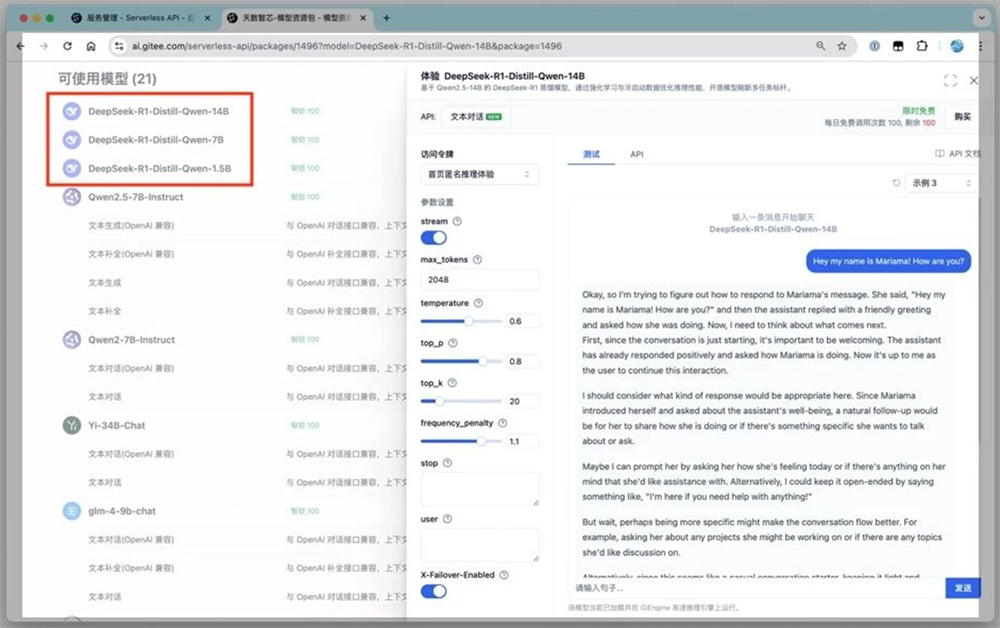
天数智芯还在联合并行科技、算力互联等多家伙伴,全力开展DeepSeek多款模型的适配与上线。
此前,DeepSeek V3 671B刚一发布,天数智芯便迅速响应,完成了与该模型的适配工作。经测试与验证,
适配后的模型精度高度对标论文精度
,展现出出色的稳定性与可靠性,可快速投入应用场景。
2月4日,摩尔线程宣布快速实现DeepSeek R1蒸馏模型推理服务在摩尔线程夸娥(KUAE)GPU智算集群上的高效部署。摩尔线程即将开放夸娥GPU智算集群,全面支持DeepSeek V3、R1模型及新一代蒸馏模型的分布式部署。
用户也可以基于摩尔线程MTT S80和MTT S4000显卡进行DeepSeek-R1蒸馏模型的推理部署。早在1月28日,就已经有B站UP主在MTT S80上手动完成推理DeepSeek R1模型的实践。
基于Ollama开源框架,摩尔线程完成DeepSeek-R1-Distill-Qwen-7B蒸馏模型的部署,并在多种中文任务中展现了优异的性能,验证了摩尔线程全功能GPU的通用性与CUDA兼容性。
2月4日~5日,海光信息宣布其技术团队近日成功完成DeepSeek V3模型、R1模型、
Janus-Pro多模态大模型
与海光DCU的适配优化,并正式上线。
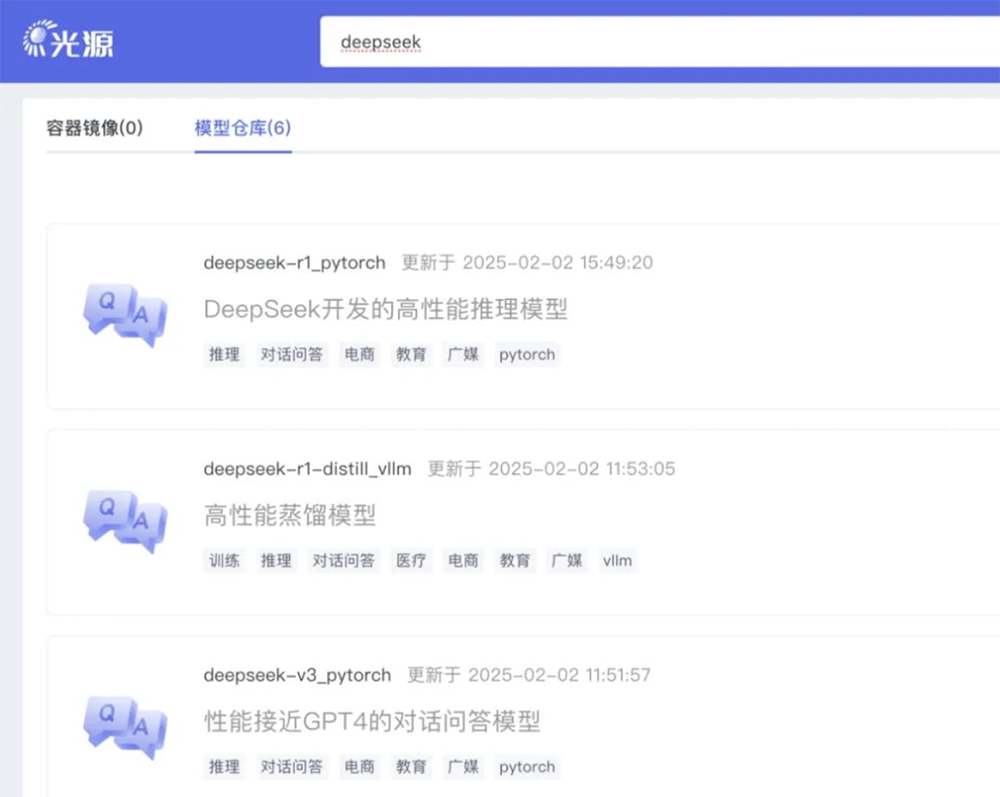
DCU(深度计算单元)是海光信息推出的高性能GPGPU架构AI加速卡,DeepSeek模型可直接在DCU上运行,并不需要大量适配工作,技术团队的主要工作是进行精度验证和持续的性能优化。
用户可通过“光合开发者社区”中的“光源”板块访问并下载相关模型,或登录 [www.sourcefind.cn] 搜索“DeepSeek”,即可基于DCU平台快速部署和使用相关模型。
2月5日,壁仞科技宣布壁仞AI算力平台正式上线DeepSeek R1全系列蒸馏模型推理服务,供开发者云端体验。
该服务具备两大核心优势:一是零部署成本,实现“开箱即用”的云端推理体验;二是多场景覆盖,针对大语言模型等不同任务预置优化配置方案。
壁仞科技已联合上海智能算力科技有限公司、中兴通讯、科华数据、无问芯穹、开源中国(Gitee AI)、UCloud优刻得、一蓦科技等战略伙伴,基于壁砺系列训推产品106M、106B、106E、110E,全面开展DeepSeek全系列模型的适配与上线。
同日,UCloud优刻得发文宣布,优刻得与壁砺系列进行适配兼容,仅用数小时即完成了对DeepSeek R1全系列蒸馏模型的支持。
2月5日,太初元碁宣布在太初T100加速卡上仅用2小时便完成DeepSeek-R1系列模型的适配工作,快速上线多款大模型服务。
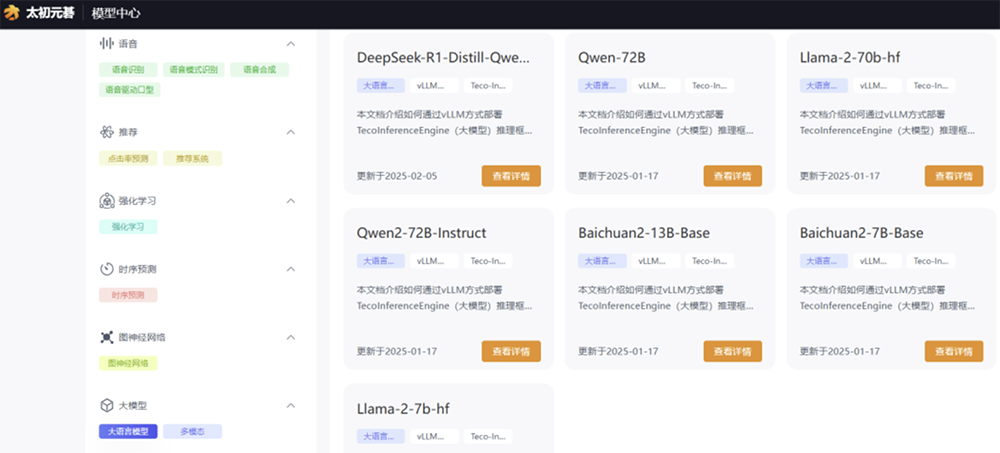
DeepSeek-R1系列模型可在太初元碁官网的模型中心获取。该模型中心为用户提供免费的太初T100加速卡,并提供模型权重下载、在线/离线推理脚本、模型评测脚本等全流程内容。
当前,DeepSeek-R1系列推理API无限量限时免费。
太初元碁正积极联手京算、是石科技、神威数智、龙芯中科等合作伙伴,全力打造DeepSeek系列模型的云端推理平台。
2月5日,云天励飞宣布其芯片团队完成DeepEdge10芯片平台与DeepSeek R1(1.5B、7B、8B)大模型的适配,可以交付客户使用。
DeepSeek R1(32B、70B)以及V3/R1 671B MoE大模型也在有序适配中。适配完成后,DeepEdge10芯片平台将在端、边、云全面支持DeepSeek全系列模型。

2月6日,燧原科技宣布完成了对DeepSeek
全量模型
的高效适配,包括DeepSeek R1/V3 671B原生模型和蒸馏模型。
目前,DeepSeek的全量模型已在庆阳、无锡、成都等智算中心完成了
数万卡
的快速部署。
这一成果
标志着
燧原科技在国内率先实现了DeepSeek全量模型的部署和落地
。
燧原科技与并济科技、并行科技、东华软件、道客网络、光环云、迈富时、清程极智、燧弘华创、未来速度、无问芯穹、向量栈、亿算智能、中科加禾等合作伙伴紧密合作,积极推进DeepSeek全量模型的更多系统级优化,进一步推理性价比。
燧原科技还与万物安全、飞渡科技、万物之宜等深度合作,即将推出面向智慧城市、智慧园区、智慧交通等
AIoT场景的国内首个DeepSeek智算训推一体机
,帮助用户解决国产化私有算力、超清数字孪生及物联网安全等问题。
2月6日,昆仑芯宣布已完成Deepseek R1、V3系列模型训练推理
全版本
适配,包括MoE模型及其蒸馏小模型,且性能卓越、成本效率极致,一键部署。
据介绍,P800显存规格优于同类主流GPU 20%-50%,对MoE架构更加友好,且率先支持8bit推理,
单机8卡即可运行671B模型
,可轻松完成DeepSeek-V3/R1全版本推理任务;并能支撑Deepseek系列MoE模型大规模训练任务,
仅需32台即可支持模型全参训练
,高效完成模型持续训练和微调。
昆仑芯前身为百度智能芯片及架构部,于2021年4月完成独立融资。2月5日,百度智能云宣布其
成功点亮昆仑芯三代P800万卡集群
,
三万卡集群也将于近日点亮
。
2月6日,灵汐科技宣布,节后开工第一天,其团队联合类脑技术社区(“脑启社区”)的开发者,仅用半天时间,就完成了DeepSeek-R1系列模型在灵汐KA200类脑芯片及相关智算卡的适配,助力国产大模型与类脑智能硬件系统的深度融合。
据 “脑启社区“的开发者反馈,在DeepSeek-R1-Distill-Qwen的1.5B、7B等系列模型测试中,模型在4K上下文情形下体验顺畅,具备交付客户使用的能力。后续,灵汐科技也将联合产业生态伙伴及脑启社区,适时发布云上服务。
2月6日,鲲云科技宣布其全新一代可重构数据流AI芯片CAISA 430成功适配DeepSeek R1蒸馏模型推理。
CAISA 430的可重构数据流架构能够根据DeepSeek R1模型的特点进行动态配置,生成面向该模型的高性能定制化流水线,进一步优化推理性能。
该芯片原生支持DeepSeek R1蒸馏模型的开源基础模型。DeepSeek R1的Qwen和Llama模型可直接在CAISA 430上运行,不需要复杂的适配工作。
2月6日,希姆计算宣布其技术团队仅用数小时,就将DeepSeek R1全系列蒸馏模型快速适配到自研RISC-V开源指令集的推理加速卡系列之上,并
落地全国多个千卡级以上智算中心
。
企业级用户可通过希姆智算云平台,一键使用DeepSeek R1全系列蒸馏模型。
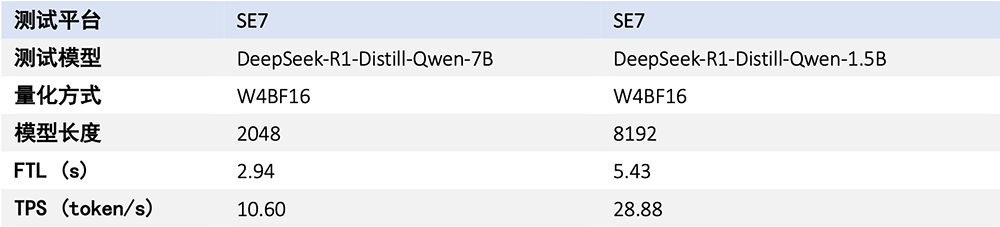
2月7日,算能宣布,搭载算丰第四代智能视觉深度学习处理器BM1684的算能微服务器SE7,已完成DeepSeek R1 7B/1.5B蒸馏模型适配,性能强劲,为R1蒸馏模型提供最佳国产边缘部署方案。
2月7日,清微智能宣布其可重构算力芯片RPU已完成DeepSeek R1系列模型的适配和部署运行。
清微智能算力服务器具有训推一体特点,支持无交换机自组网调度,显著提升计算资源利用率与能效比,
单机支持DeepSeek全尺寸模型
,具有高性价比特点。
除推理外,该服务器高性能支持基于DeepSeek模型对其他模型进行蒸馏训练,便于实现大模型本地私有化部署。
2月7日,芯动力宣布
在24小时内完成了与DeepSeek R1大模型的适配。其高性能AI加速卡A
zureBlade K340L M.2
内嵌AE7100芯片,尺寸大约半张名片大小,算力达到32TOPS,功耗不到8W,
已经可以支撑大模型在AI PC等设备上运行。





