Fusion-NewSQL 是由滴滴自研的在分布式 KV 存储基础上构建的 NewSQL 存储系统。Fusion-NewSQL 兼容了 MySQL 协议,支持二级索引功能,提供超大规模数据持久化存储和高性能读写。
一. 遇到的问题
滴滴的业务快速持续发展,数据量和请求量急剧增长,对存储系统等压力与日俱增。虽然分库分表在一定程度上可以解决数据量和请求增加的需求,但是由于滴滴多条业务线(快车,专车,两轮车等)的业务快速变化,数据库加字段加索引的需求非常频繁,分库分表方案对于频繁的 Schema 变更操作并不友好,会导致 DBA 任务繁重,变更周期长,并且对巨大的表操作还会对线上有一定影响。同时,分库分表方案对二级索引支持不友好或者根本不支持。
鉴于上述情况,NewSQL 数据库方案就成为我们解决业务问题的一个方向。
二. 开源产品调研
最开始,我们调研了开源的分布式 NewSQL 方案:TiDB。虽然 TiDB 是非常优秀的 NewSQL 产品,但是对于我们的业务场景来说,TiDB 并不是非常适合,原因如下:
-
我们需要一款高吞吐,低延迟的数据库解决方案,但是 TiDB 由于要满足事务,2pc 方案天然无法满足低延迟(100ms 以内的 99rt,甚至 50ms 内的 99rt)
-
我们的多数业务,并不真正需要分布式事务,或者说可以通过其他补偿机制,绕过分布式事务。这是由于业务场景决定的。
-
TiDB 三副本的存储空间成本相对比较高。
-
我们内部一些离线数据导入在线系统的场景,不能直接和 TiDB 打通。
基于以上原因,我们开启了自研符合自己业务需求的 NewSQL 之路。
三. 我们的基础
我们并没有打算从 0 开发一个完备的 NewSQL 系统,而是在自研的分布式 KV 存储 Fusion 的基础上构建一个能满足我们业务场景的 NewSQL。Fusion 是采用了 Codis 架构,兼容 Redis 协议和数据结构,使用 RocksDB 作为存储引擎的 NoSQL 数据库。Fusion 在滴滴内部已经有几百个业务在使用,是滴滴主要的在线存储之一。
Fusion 的架构图如下:
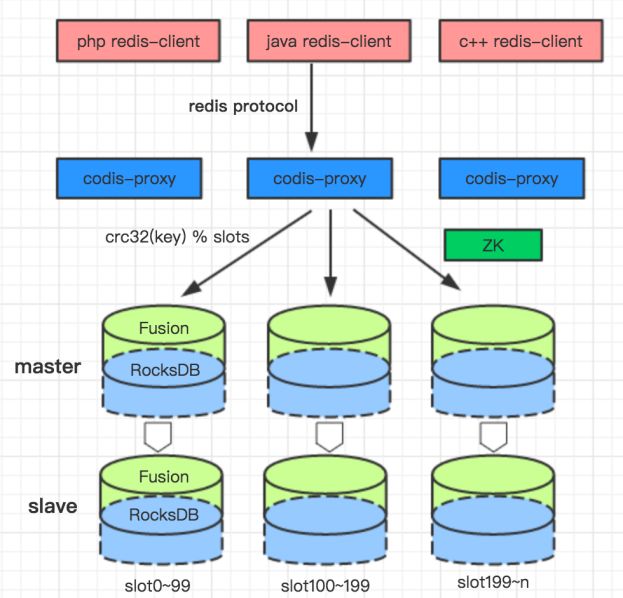
我们采用 hash 分片的方式来做数据 sharding。从上往下看,用户通过 Redis 协议的客户端就可以访问 Fusion,用户的访问请求发到 proxy,再由 proxy 转发数据到后端 Fusion 的数据节点。proxy 到后端数据节点的转发,是根据请求的 key 计算 hash 值,然后对 slot 分片数取余,得到一个固定的 slotid,每个 slotid 会固定的映射到一个存储节点,以此解决数据路由问题。
有了一个高并发,低延迟,大容量的存储层后,我们要做的就是在之上构建 MySQL 协议以及二级索引。
需求
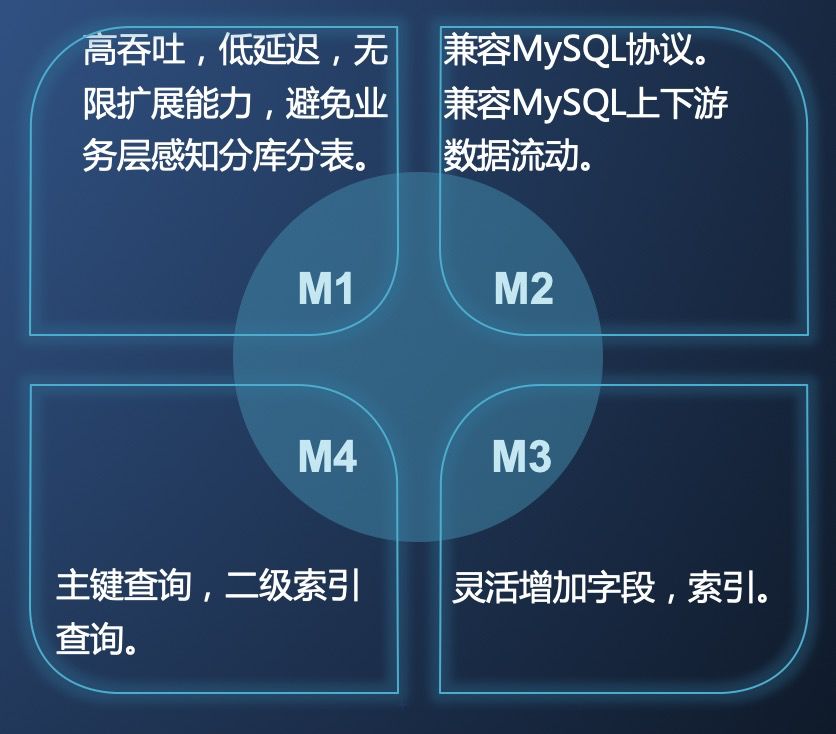
综合考虑大多数用户对需求,我们整理了我们的 NewSQL 需要提供的几个核心能力:
-
高吞吐,低延迟,大容量
-
兼容 MySQL 协议及下游生态
-
支持主键查询和二级索引查询
-
Schema 变更灵活,不影响线上服务稳定性。
架构设计
Fusion-NewSQL 由下面几个部分组成:
1. 解析 MySQL 协议的 DiseServer
2. 存储数据的 Fusion 集群 -Data 集群
3. 存储索引信息的 Fusion 集群 -Index 集群
4. 负责 Schema 的管理配置中心 -ConfigServer
5. 异步构建索引程序 -Consumer 负责消费 Data 集群写到 MQ 中的 MySQL-Binlog 格式数据,根据 schema 信息,生成索引数据写入 Index 集群。
6. 外部依赖,MQ,Zookeeper
架构图如下:

技术挑战及方案
1.SQL 表转 Hashmap
MySQL 的表结构数据如何转成 Redis 的数据结构是我们面临的第一个问题。
如下图:
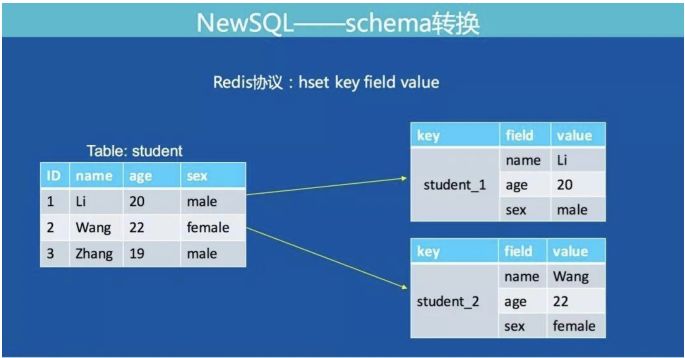
我们将 MySQL 表的一行记录转成 Redis 的一个 Hashmap 结构。Hashmap 的 key 由表名 + 主键值组成,满足了全局唯一的特性。下图展示了 MySQL 通过主键查询转换为 Redis 协议的方式:
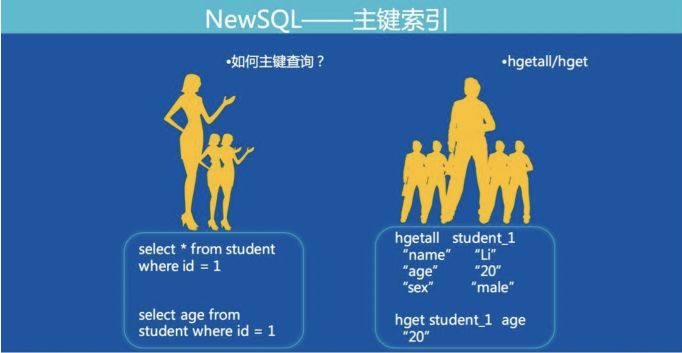
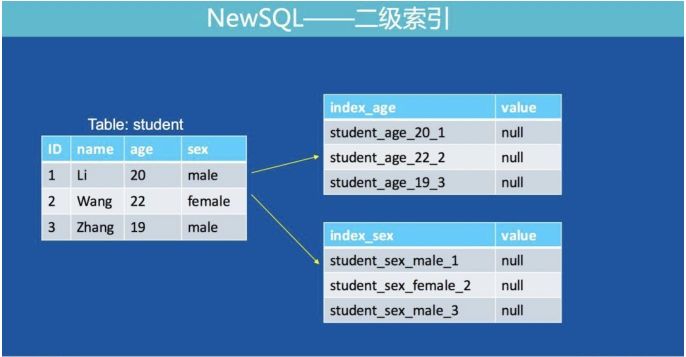
除了数据,索引也需要存储在 Fusion-NewSQL 中,和数据存成 hashmap 不同,索引存储成 key-value 结构。根据索引类型不同,组成 key-value 的格式还有一点细微的差别 (下面的格式为了看起来直观,实际上分隔符,indexname 都是做过编码的):
1. 唯一索引:
Key: table_indexname_indexColumnsValue Value: Rowkey
2. 非唯一索引:
Key: table_indexname_indexColumnsValue_Rowkey Value:null
造成这种差异的原因就是非唯一索引在加入 Rowkey 之前的部分是有可能重复的,无法全局唯一。另外,唯一索引不将 Rowkey 编码在 key 中,是因为在查询语句是单纯的“=”查询的时候直接 get 操作就可以找到对应的 Rowkey 内容,而不需要通过 scan,这样的效率更高。