(点击上方蓝字,快速关注我们)
来源:ieiayaobb
segmentfault.com/a/1190000010348905
如有好文章投稿,请点击 → 这里了解详情
前言
作为一个炉石传说玩家,经常有事没事开着直播网站看看大神们的精彩表演。不过因为各个平台互相挖人的关系,导致关注的一些主播分散到了各个直播平台,来回切换有点麻烦,所以萌生了做一个视频聚合站的想法。
我主要去采集斗鱼、熊猫等的炉石区的主播信息。虽然各个站点的人气信息有水分,但还是做了个简单的排名。
上图:

手机上的效果图:
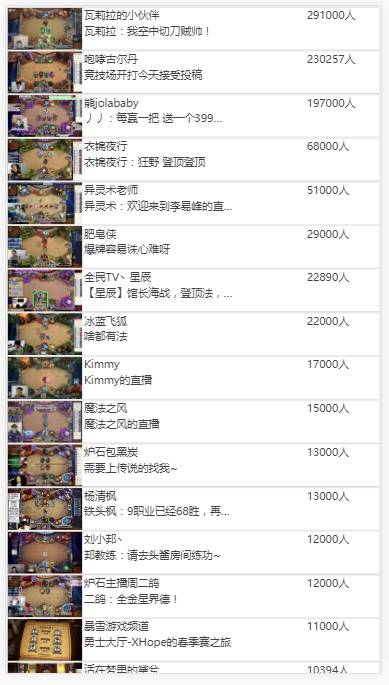
话不多说,上网站: http://lushiba.leanapp.cn/
项目部输在了leancloud上,比较省心,但有一定的免费额度(如果显示超出限制,需要晚一些来访问,毕竟免费的,每天6个小时限制)
源码地址: https://github.com/ieiayaobb/lushi8 欢迎Star
master分支是redis方式存储实现
lean分支是基于lean cloud的实现
基础介绍
聚合站的思路就是采集目标站点的相关信息,通过数据处理将想要的信息做提取,整理入库,然后通过web展示。因为直播平台数据实时在变,所以考虑将存储的数据放在缓存中(redis),因为部署在了lean cloud上,所以示例就直接存储在了lean cloud的存储上。
为了方便讲解,我们以斗鱼为目标采集的网站,介绍解析和存储部分的内容,其他网站的处理大同小异。
功能说明
整体项目就分为数据采集解析、数据存储、web展现三大功能。后续我们会对这三个部分的功能做逐一展开说明。
技术选型
轻量级的项目,直接就是用了Python来做,Python在爬虫、web方面都有着不错的库支持,而且lean cloud也支持Python部署,所以毫不犹豫的就采用了Python来做
requests的特点就是轻量,且简单易用。虽然这是个爬虫项目,但实在规模太小,所以没必要上scrapy了
requests的介绍地址:http://docs.python-requests.org/zh_CN/latest/index.html
请求模拟
url = 'http://www.douyu.com/directory/game/How'
session = requests.Session()
response = session.get(url, verify=False)
数据解析
解析部分主要有两种:正则,BeautifulSoup
这里为了通用,直接使用了正则来解析。
正则处理要求比较高,但是几乎能应对所有的情况,属于大杀器。
BeautifulSoup4的详细介绍: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Django是Python比较重量级的框架,Django自带了orm的框架,可惜这个项目中用不到。但是我们会使用Django的模板引擎,Django的模板引擎也是很方便的一个特性。Django还提供了django-rest-framework,方便开发RESTful的接口,这个项目后续做了个配搭的React Native的mobile应用,所以引入了django-rest-framework。
详细介绍在此:https://www.djangoproject.com/
既然用了lean cloud,存储就直接用了lean提供的存储功能。
详细的介绍在这里: https://leancloud.cn/docs/leanstorage_guide-python.html
参考了lean cloud官方的项目骨架: https://github.com/leancloud/django-getting-started
pureCss还是为了简单,支持响应式,并且提供了基础的UI组件
详细介绍在这里: https://purecss.io/
环境准备
Python的开发环境网上比较多,主要是virtualenv的准备,可以看廖老师的博客了解具体信息:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001432712108300322c61f256c74803b43bfd65c6f8d0d0000
requirments.txt内容如下:
Django==1.9.7
requests==2.10.0
wheel==0.24.0
gunicorn
leancloud-sdk>=1.0.9
分析与采集
视频站内容解析
目标是采集炉石区所有主播的链接地址和人气情况
#### 页面内容(单个主播的信息)
<a class="play-list-link" data-rid='48699' data-tid='2' data-sid='167' data-rpos="0" data-sub_rt="0" href="/yechui" title="衣锦夜行:狂野 登顶登顶"
target="_blank">
<span class="imgbox">
<span class="imgbox-corner-mark">span>
<b>b>
<i class="black">i>

span>
<div class="mes">
<div class="mes-tit">
<h3 class="ellipsis">衣锦夜行:狂野 登顶登顶h3>
<span class="tag ellipsis">炉石传说span>
div>
<p>
<span class="dy-name ellipsis fl">衣锦夜行span>
<span class="dy-num fr" >8.1万span>
p>
div>
a>
衣锦夜行:狂野 登顶登顶
炉石传说
衣锦夜行 8.1万
我们需要采集的有几部分内容:
直播间url (节点里的href,/yechui)
直播间的标题(节点里的title,衣锦夜行:狂野 登顶登顶)
直播间的截图(节点里的img标签的src,https://rpic.douyucdn.cn/a170…)
直播间的人气(8.1万)(这里有个注意的地方,斗鱼的人气可能是X万,需要把这个万转化成数值方便排序)
主播名称(衣锦夜行)
页面处理与采集
所有完整的直播站处理代码在fetch.py中
#### 命中主播信息节点
re.finditer('([\s\S]*?)', response.content.decode('utf8'))
简单的说明一下代码:
response.content.decode('utf8')
解析代码
采集href信息(主播房间链接)
href = re.search('href=".*?"', group).group().lstrip('href="').rstrip('"')
采集标题信息
title = re.search('title=".*?"', group).group().lstrip('title="').rstrip('"')
采集截图信息
img = re.search('data-original=".*?"', group).group().lstrip('data-original="').rstrip('"')
采集主播名称
name = re.search('.*?', group).group().lstrip('').rstrip('')
采集人气数量信息
num = re.search('').rstrip('')
处理‘万’字
int(round(float(num.replace('万', '').replace('\r', '').replace('\n', '')) * 10000))
存储与刷新
采集到的信息需要存储到lean cloud的存储中,会调用lean cloud所提供的API
字段设计
Chairman
直播间的唯一id
直播间主播名称
直播间的标题
直播间的页面地址
直播间的人气
直播间的截图
接口设计
/fetch
Fetch的接口包含了清空、采集、解析、存储所有的更新逻辑,设计这个接口的目的主要是方便后面使用云函数进行定时调用,以更新数据,调用逻辑如下(lean cloud不支持全部遍历,所以用了while循环来遍历所有,先清空,再采集):
leancloud.init(LEAN_CLOUD_ID, LEAN_CLOUD_SECRET)
query = leancloud.Query('Chairman')
allDataCompleted = False
batch = 0
limit = 1000
while not allDataCompleted:
query.limit(limit)
query.skip(batch * limit)
query.add_ascending('createdAt')
resultList = query.find()
if len(resultList) < limit:
allDataCompleted = True
leancloud.Object.destroy_all(resultList)
batch += 1
fetcher = Fetcher()
fetcher.fetch_douyu()
/chairmans(redis版本才支持)
Django-rest-framework提供,可以通过分页的方式展现当前库中的信息
/chairman/{id}(redis版本才支持)
Django-rest-framework提供,可以根据指定id获取某一个主播的信息
刷新机制
lean cloud提供了一种云函数的概念,并且可以像配置cron一样,定期的去触发某一个请求,为了能够定期的更新排行榜,我们会通过配置这个云函数,实现定期的数据刷新
云函数是一个cloud.py文件,内容如下
engine = Engine(get_wsgi_application())
@engine.define
def fetch(**params):
leancloud.init(LEAN_CLOUD_ID, LEAN_CLOUD_SECRET)
# fetch逻辑
在lean cloud中配置定时执行
页面展示
页面部分比较简单,以一个列表的形式,展现了主播的排行榜信息,点击某一个主播,直接跳转到对应直播网站的目标直播间。因为考虑到在手机上的显示,所以做了自适应
列表页
列表页的渲染使用了Django的模板引擎
由于lean cloud的存储和Django的orm不一样,所以这里需要将attributes放到列表中,页面上才能用模板语法进行访问
view部分代码:
def get_index(request):
leancloud.init(LEAN_CLOUD_ID, LEAN_CLOUD_SECRET)
query = leancloud.Query('Chairman')
chairmans = []
for chairman in query.add_descending('num').find():
chairmans.append(chairman.attributes)
return render_to_response('index.html', locals(),
context_instance=RequestContext(request))
页面部分代码:
{% for chairman in chairmans %}
<a href="{{ chairman.href }}" class="chairman-wrapper">
<div class="pure-g chairman">
<div class="pure-u-1-5">

div>
<div class="pure-u-2-5">
<div class="name">{{ chairman.name }}div>
<div class="title">{{ chairman.title }}div>
div>
<div class="pure-u-1-5">
<span class="type {{ chairman.type }}">span>
div>
<div class="pure-u-1-5">
<div class="num">{{ chairman.num }}人div>
div>
div>
a>
{% endfor %}
项目部署
因为部署在了lean cloud上,可以直接使用提供的lean-cli进行部署,
lean-cli的详细介绍在这里:
https://www.leancloud.cn/docs/leanengine_cli.html# 部署
这里为了方便直接在页面上进行配置

后言
整个项目比较简单,目的是为了练手。如有疑问,欢迎在github上面发issue。
看完本文有收获?请转发分享给更多人
关注「Python开发者」,提升Python技能










