在2015年11月9号Google发布了人工智能系统TensorFlow并宣布开源,此举在深度学习领域影响巨大,也受到大量的深度学习开发者极大的关注。当然,对于人工智能这个领域,依然有不少质疑的声音,但不可否认的是人工智能仍然是未来发展的趋势。
而TensorFlow能够在登陆GitHub的当天就成为最受关注的项目,作为构建深度学习模型的最佳方式、深度学习框架的领头者,在发布当周轻松获得超过1万个星数评级,这主要是因为Google在人工智能领域的研发成绩斐然和神级的技术人才储备。当然还有一点是在围棋上第一次打败人类,然后升级版Master保持连续60盘不败的AlphaGo,其强化学习的框架也是基于TensorFlow的高级API实现的。
作为Goolge二代DL框架,使用数据流图的形式进行计算的TensorFlow已经成为了机器学习、深度学习领域中最受欢迎的框架之一。自从发布以来,TensorFlow不断在完善并增加新功能,并在今年的2月26号在Mountain View举办的首届年度TensorFlow开发者峰会上正式发布了TensorFlow 1.0版本,其最大的亮点就是通过优化模型达到最快的速度,且快到令人难以置信,更让人想不到的是很多拥护者用TensorFlow 1.0的发布来定义AI的元年。
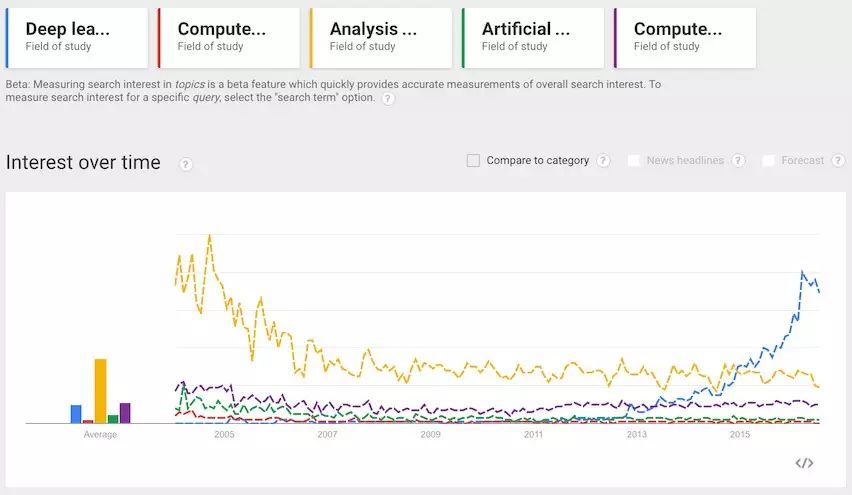
通过以上Google指数,深度学习占据目前流程技术的第一位
TensorFlow在过去获得成绩主要有以下几点:
TensorFlow被应用在Google很多的应用包括:Gmail, Google Play Recommendation, Search, Translate, Map等等; 在医疗方面,TensorFlow被科学家用来搭建根据视网膜来预防糖尿病致盲(后面也提到Stanford的PHD使用TensorFlow来预测皮肤癌,相关工作上了Nature封面); 通过在音乐、绘画这块的领域使用TensorFlow构建深度学习模型来帮助人类更好地理解艺术; 使用TensorFlow框架和高科技设备,构建自动化的海洋生物检测系统,用来帮助科学家了解海洋生物的情况; TensorFlow在移动客户端发力,有多款在移动设备上使用TensorFlow做翻译、风格化等工作; TensorFlow在移动设备CPU(高通820)上,能够达到更高的性能和更低的功耗; TensorFlow ecosystem结合其他开源项目能够快速地搭建高性能的生产环境; TensorBoard Embedded vector可视化工作 能够帮助PHD/科研工作者快速开展project研究工作。
|
Google第一代分布式机器学习框架DistBelief不再满足Google内部的需求,Google的小伙伴们在DistBelief基础上做了重新设计,引入各种计算设备的支持包括CPU/GPU/TPU,以及能够很好地运行在移动端,如安卓设备、ios、树莓派 等等,支持多种不同的语言(因为各种high-level的api,训练仅支持Python,inference支持包括C++,Go,Java等等),另外包括像TensorBoard这类很棒的工具,能够有效地提高深度学习研究工作者的效率。
TensorFlow在Google内部项目应用的增长也十分迅速:在Google多个产品都有应用如:Gmail,Google Play Recommendation, Search, Translate, Map等等;有将近100多project和paper使用TensorFlow做相关工作。

TensorFlow在正式版发布前的过去14个月的时间内也获得了很多的成绩,包括475+非Google的Contributors,14000+次commit,超过5500标题中出现过TensorFlow的github project以及在Stack Overflow上有包括5000+个已被回答 的问题,平均每周80+的issue提交,且被一些顶尖的学术研究项目使用: – Neural Machine Translation – Neural Architecture Search – Show and Tell.
当然了,说到底深度学习就是用非监督式或者半监督式的特征学习,分层特征提取高校算法来替代手工获取特征。目前研究人员和从事深度学习的开发者使用深度学习框架也并非只有TensorFlow一个,同样也有很多在视觉、语言、自然语言处理和生物信息等领域较为优秀的框架,比如Torch、Caffe、Theano、Deeplearning4j等。
下面,编者整理段石石博文中的一些对网络神经模型、算法深度分析的内容,了解TensorFlow这个开源深度学习框架的强大之处。
这篇文章主要针对Tensorflow利用CNN的方法对艺术照片做下Neural Style的相关工作。首先,作者会详细解释下A Neural Algorithm of Artistic Style这篇paper是怎么做的,然后会结合一个开源的Tensorflow的Neural Style版本来领略下大神的风采。
在艺术领域,尤其是绘画,艺术家们通过创造不同的内容与风格,并相互交融影响来创立独立的视觉体验。如果给定两张图像,现在的技术手段,完全有能力让计算机识别出图像具体内容。而风格是一种很抽象的东西,在计算机的眼中,当然就是一些pixel,但人眼就能很有效地的辨别出不同画家不同的style,是否有一些更复杂的feature来构成,最开始学习DeepLearning的paper时,多层网络的实质其实就是找出更复杂、更内在的features,所以图像的style理论上可以通过多层网络来提取里面可能一些有意思的东西。而这篇文章就是利用卷积神经网络(利用pretrain的Pre-trained VGG network model)来分别做Content、Style的reconstruction,在合成时考虑content loss 与style loss的最小化(其实还包括去噪变化的的loss),这样合成出来的图像会保证在content 和style的重构上更准确。

这里是整个paper在neural style的工作流,理解这幅图对理解整篇paper的逻辑很关键,主要分为两部分:
Content Reconstruction:上图中下面部分是Content Reconstruction对应于CNN中的a,b,c,d,e层,注意最开始标了Content Representations的部分不是原始图片(可以理解是给计算机比如分类器看的图片,因此如果可视化它,可能完全就不知道是什么内容),而是经过了Pre-trained之后的VGG network model的图像数据, 该model主要用来做object recognition, 这里主要用来生成图像的Content Representations。理解了这里,后面就比较容易了,经过五层卷积网络来做Content的重构,文章作者实验发现在前3层的Content Reconstruction效果比较好,d,e两层丢失了部分细节信息,保留了比较high-level的信息。
Style Reconstruction: Style的重构比较复杂,很难去模型化Style这个东西,Style Represention的生成也是和Content Representation的生成类似,也是由VGG network model去做的,不同点在于a,b,c,d,e的处理方式不同,Style Represention的Reconstruction是在CNN的不同的子集上来计算的,怎么说呢,它会分别构造conv1_1(a),[conv1_1, conv2_1](b),[conv1_1, conv2_1, conv3_1],[conv1_1, conv2_1, conv3_1,conv4_1],[conv1_1, conv2_1, conv3_1, conv4_1, conv5_1]。这样重构的Style 会在各个不同的尺度上更加匹配图像本身的style,忽略场景的全局信息。
|
理解了以上两点,剩下的就是建模的数据问题了,这里按Content和Style来分别计算loss,Content loss的method比较简单:
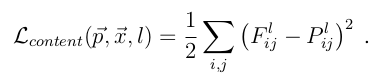
其中F^l是产生的Content Representation在第l层的数据表示,P^l是原始图片在第l层的数据表示,定义squared-error loss为两种特征表示的error。
Style的loss基本也和Content loss一样,只不过要包含每一层输出的errors之和
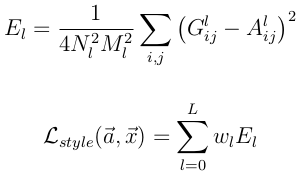
其中A^l 是原始style图片在第l的数据表示,而G^l是产生的Style Representation在第l层的表示
定义好loss之后就是采用优化方法来最小化模型loss(注意paper当中只有content loss和style loss),源码当中还涉及到降噪的loss:
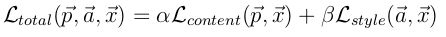
优化方法这里就不讲了,tensorflow有内置的如Adam这样的方法来处理。
前面看了一些Tensorflow的文档和一些比较有意思的项目,发现这里面水很深的,需要多花时间好好从头了解下,尤其是cv这块的东西,特别感兴趣,接下来一段时间会开始深入了解ImageNet比赛中中获得好成绩的那些模型: AlexNet、GoogLeNet、VGG(对就是之前在nerual network用的pretrained的model)、deep residual networks。
ImageNet Classification with Deep Convolutional Neural Networks 是Hinton和他的学生Alex Krizhevsky在12年ImageNet Challenge使用的模型结构,刷新了Image Classification的几率,从此deep learning在Image这块开始一次次超过state-of-art,甚至于搭到打败人类的地步,看这边文章的过程中,发现了很多以前零零散散看到的一些优化技术,但是很多没有深入了解,这篇文章讲解了他们alexnet如何做到能达到那么好的成绩,好的废话不多说,来开始看文章:
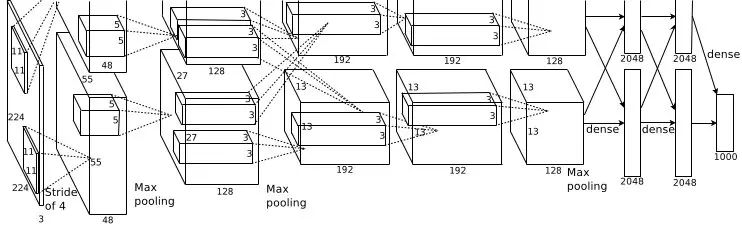
这张图是基本的caffe中alexnet的网络结构,这里比较抽象,作者用caffe的draw_net把alexnet的网络结构画出来了:
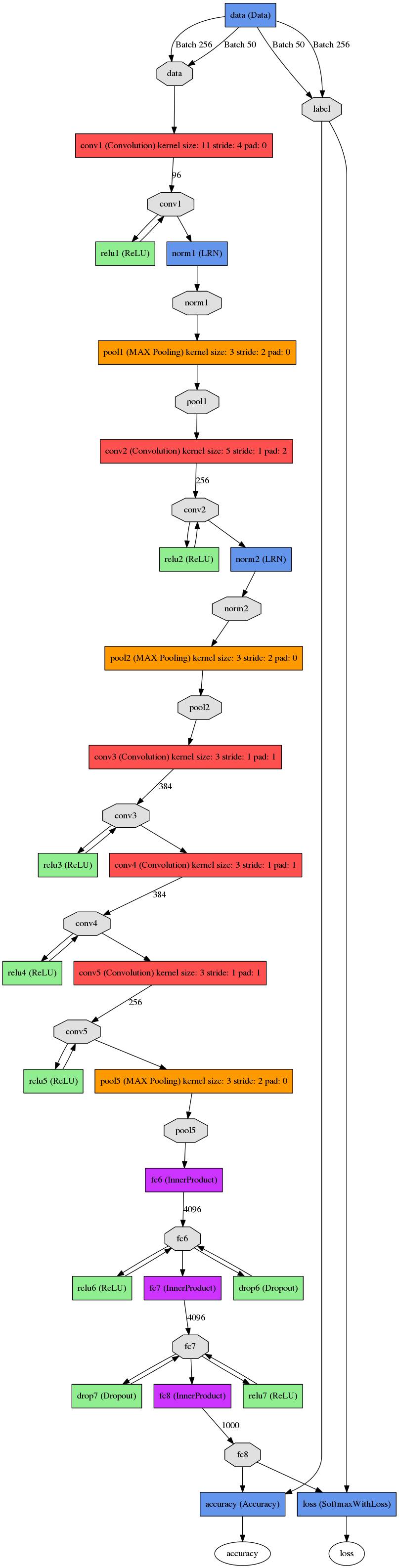
alexnet总共包括8层,其中前5层convolutional,后面3层是full-connected,文章里面说的是减少任何一个卷积结果会变得很差,下面具体讲讲每一层的构成:
第一层卷积层 输入图像为227*227*3(paper上貌似有点问题224*224*3)的图像,使用了96个kernels(96,11,11,3),以4个pixel为一个单位来右移或者下移,能够产生5555个卷积后的矩形框值,然后进行response-normalized(其实是Local Response Normalized,后面我会讲下这里)和pooled之后,pool这一层好像caffe里面的alexnet和paper里面不太一样,alexnet里面采样了两个GPU,所以从图上面看第一层卷积层厚度有两部分,池化pool_size=(3,3),滑动步长为2个pixels,得到96个2727个feature。 第二层卷积层使用256个(同样,分布在两个GPU上,每个128kernels(5*5*48)),做pad_size(2,2)的处理,以1个pixel为单位移动(感谢网友指出),能够产生27*27个卷积后的矩阵框,做LRN处理,然后pooled,池化以3*3矩形框,2个pixel为步长,得到256个13*13个features。 第三层、第四层都没有LRN和pool,第五层只有pool,其中第三层使用384个kernels(3*3*384,pad_size=(1,1),得到384*15*15,kernel_size为(3,3),以1个pixel为步长,得到384*13*13);第四层使用384个kernels(pad_size(1,1)得到384*15*15,核大小为(3,3)步长为1个pixel,得到384*13*13);第五层使用256个kernels(pad_size(1,1)得到384*15*15,kernel_size(3,3),得到256*13*13,pool_size(3,3)步长2个pixels,得到256*6*6)。
全连接层: 前两层分别有4096个神经元,最后输出softmax为1000个(ImageNet),注意caffe图中全连接层中有relu、dropout、innerProduct。
|
paper里面也指出了这张图是在两个GPU下做的,其中和caffe里面的alexnet可能还真有点差异,但这可能不是重点,各位在使用的时候,直接参考caffe中的alexnet的网络结果,每一层都十分详细,基本的结构理解和上面是一致的。
前面讲了下AlexNet的基本网络结构,大家肯定会对其中的一些点产生疑问,比如LRN、Relu、dropout, 相信接触过dl的小伙伴们都有听说或者了解过这些。这里按paper中的描述详细讲述这些东西为什么能提高最终网络的性能。
一般来说,刚接触神经网络还没有深入了解深度学习的小伙伴们对这个都不会太熟,一般都会更了解另外两个激活函数(真正往神经网络中引入非线性关系,使神经网络能够有效拟合非线性函数)tanh(x)和(1+e^(-x))^(-1),而ReLU(Rectified Linear Units) f(x)=max(0,x)。基于ReLU的深度卷积网络比基于tanh的网络训练块数倍,下图是一个基于CIFAR-10的四层卷积网络在tanh和ReLU达到25%的training error的迭代次数:
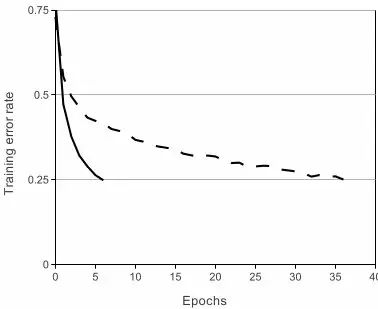
实线、间断线分别代表的是ReLU、tanh的training error,可见ReLU比tanh能够更快的收敛
Local Response Normalization
使用ReLU f(x)=max(0,x)后,你会发现激活函数之后的值没有了tanh、sigmoid函数那样有一个值域区间,所以一般在ReLU之后会做一个normalization,LRU就是文中提出(这里不确定,应该是提出?)一种方法,在神经科学中有个概念叫“Lateral inhibition”,讲的是活跃的神经元对它周边神经元的影响。
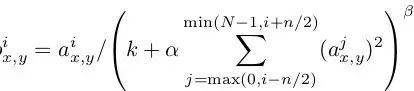
Dropout也是经常挺说的一个概念,能够比较有效地防止神经网络的过拟合。 相对于一般如线性模型使用正则的方法来防止模型过拟合,而在神经网络中Dropout通过修改神经网络本身结构来实现。对于某一层神经元,通过定义的概率来随机删除一些神经元,同时保持输入层与输出层神经元的个人不变,然后按照神经网络的学习方法进行参数更新,下一次迭代中,重新随机删除一些神经元,直至训练结束
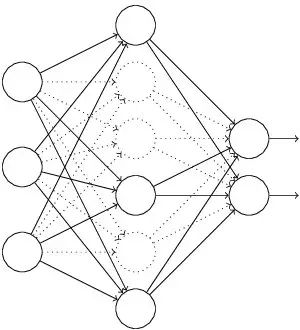
其实,最简单的增强模型性能,防止模型过拟合的方法是增加数据,但是其实增加数据也是有策略的,paper当中从256*256中随机提出227*227的patches(paper里面是224*224),还有就是通过PCA来扩展数据集。这样就很有效地扩展了数据集,其实还有更多的方法视你的业务场景去使用,比如做基本的图像转换如增加减少亮度,一些滤光算法等等之类的,这是一种特别有效地手段,尤其是当数据量不够大的时候。
GoogLeNet是ILSVRC 2014的冠军,主要是致敬经典的LeNet-5算法,主要是Google的team成员完成,paper见Going Deeper with Convolutions.相关工作主要包括LeNet-5、Gabor filters、Network-in-Network.Network-in-Network改进了传统的CNN网络,采用少量的参数就轻松地击败了AlexNet网络,使用Network-in-Network的模型最后大小约为29MNetwork-in-Network caffe model.GoogLeNet借鉴了Network-in-Network的思想,下面会详细讲述下。
左边是CNN的线性卷积层,一般来说线性卷积层用来提取线性可分的特征,但所提取的特征高度非线性时,需要更加多的filters来提取各种潜在的特征,这样就存在一个问题,filters太多,导致网络参数太多,网络过于复杂对于计算压力太大。
文章主要从两个方法来做了一些改良:
卷积层的改进:MLPconv,在每个local部分进行比传统卷积层复杂的计算,如上图右,提高每一层卷积层对于复杂特征的识别能力,这里举个不恰当的例子,传统的CNN网络,每一层的卷积层相当于一个只会做单一任务,你必须要增加海量的filters来达到完成特定量类型的任务,而MLPconv的每层conv有更加大的能力,每一层能够做多种不同类型的任务,在选择filters时只需要很少量的部分; 采用全局均值池化来解决传统CNN网络中最后全连接层参数过于复杂的特点,而且全连接会造成网络的泛化能力差,Alexnet中有提高使用dropout来提高网络的泛化能力。
|
最后作者设计了一个4层的Network-in-network+全局均值池化层来做imagenet的分类问题。
class NiN(Network):
def setup(self):
(self.feed('data')
.conv(11, 11, 96, 4, 4, padding='VALID', name='conv1')
.conv(1, 1, 96, 1, 1, name='cccp1')
.conv(1, 1, 96, 1, 1, name='cccp2')
.max_pool(3, 3, 2, 2, name='pool1')
.conv(5, 5, 256, 1, 1, name='conv2')
.conv(1, 1, 256, 1, 1, name='cccp3')
.conv(1, 1, 256, 1, 1, name='cccp4')
.max_pool(3, 3, 2, 2, padding='VALID', name='pool2')
.conv(3, 3, 384, 1, 1, name='conv3')
.conv(1, 1, 384, 1, 1, name='cccp5')
.conv(1, 1, 384, 1, 1, name='cccp6')
.max_pool(3, 3, 2, 2, padding='VALID', name='pool3')
.conv(3, 3, 1024, 1, 1, name='conv4-1024')
.conv(1, 1, 1024, 1, 1, name='cccp7-1024')
.conv(1, 1, 1000, 1, 1, name='cccp8-1024')
.avg_pool(6, 6, 1, 1, padding='VALID', name='pool4')
.softmax(name='prob'))
网络基本结果如上,代码见https://github.com/ethereon/caffe-tensorflow. 这里因为作者最近工作变动的问题,没有了机器来跑一篇,也无法画下基本的网络结构图,之后会补上。这里指的提出的是中间cccp1和ccp2(cross channel pooling)等价于1*1kernel大小的卷积层。caffe中NIN的实现(略,请前往原文阅读)
NIN的提出其实也可以认为我们加深了网络的深度,通过加深网络深度(增加单个NIN的特征表示能力)以及将原先全连接层变为aver_pool层,大大减少了原先需要的filters数,减少了model的参数。paper中实验证明达到Alexnet相同的性能,最终model大小仅为29M。
理解NIN之后,再来看GoogLeNet就不会有不明所理的感觉。
痛点
越大的CNN网络,有更大的model参数,也需要更多的计算力支持,并且由于模型过于复杂会过拟合;
在CNN中,网络的层数的增加会伴随着需求计算资源的增加;
稀疏的network是可以接受,但是稀疏的数据结构通常在计算时效率很低
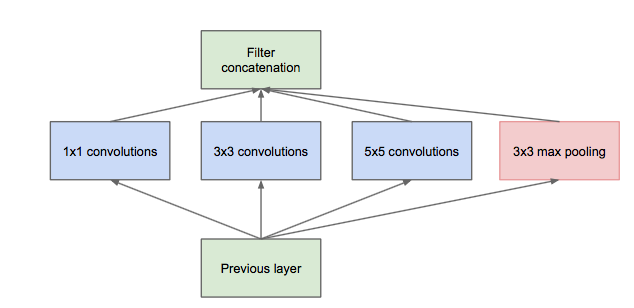
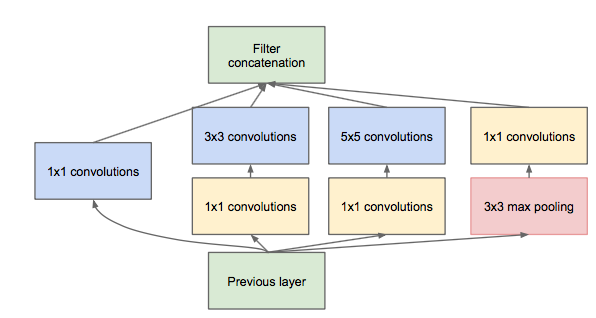
Inception module的提出主要考虑多个不同size的卷积核能够hold图像当中不同cluster的信息,为方便计算,paper中分别使用1*1,3*3,5*5,同时加入3*3 max pooling模块。 然而这里存在一个很大的计算隐患,每一层Inception module的输出的filters将是分支所有filters数量的综合,经过多层之后,最终model的数量将会变得巨大,naive的inception会对计算资源有更大的依赖。 前面有提到Network-in-Network模型,1*1的模型能够有效进行降维(使用更少的来表达尽可能多的信息),所以文章提出了”Inception module with dimension reduction”,在不损失模型特征表示能力的前提下,尽量减少filters的数量,达到减少model复杂度的目的。
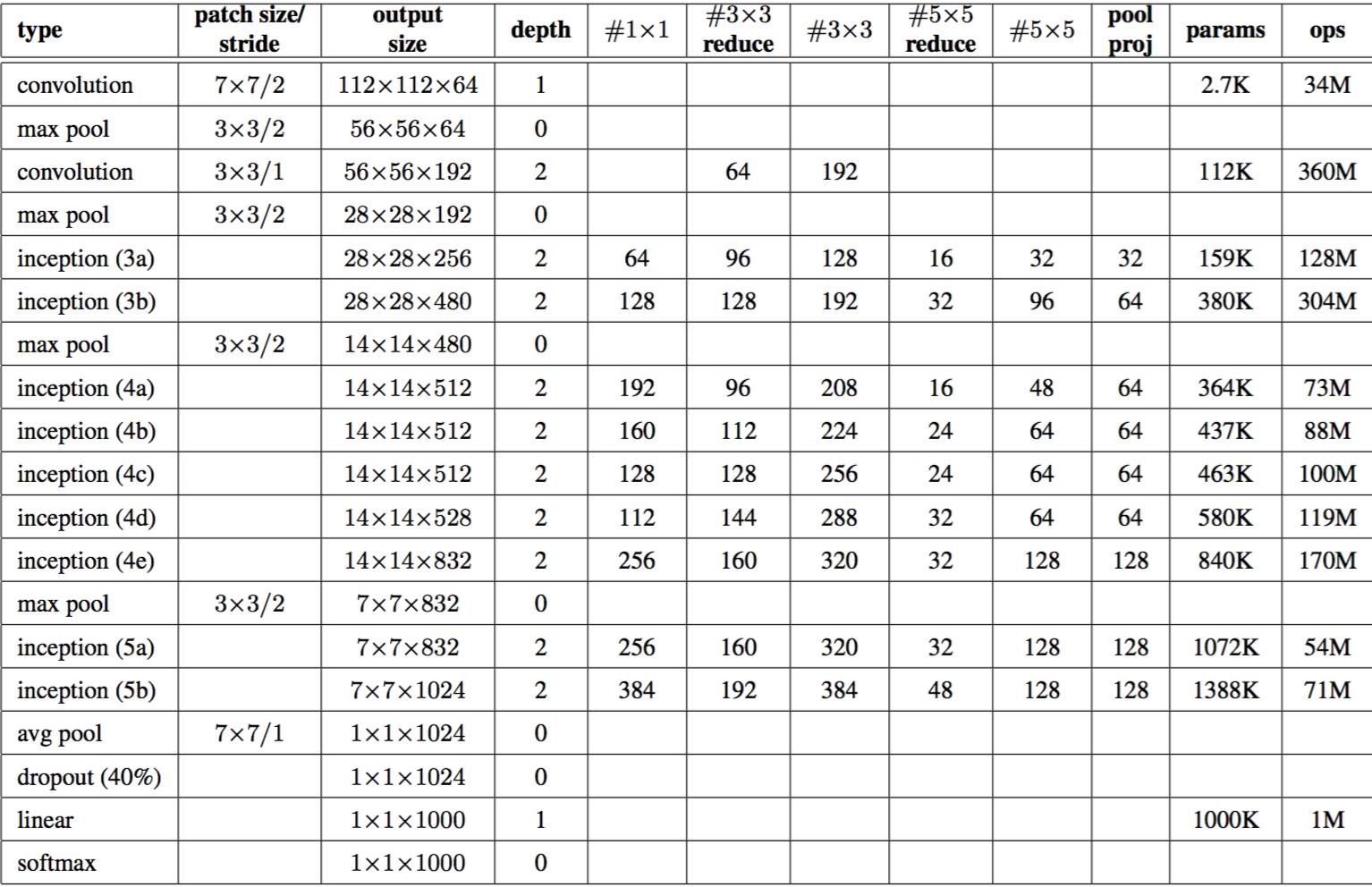
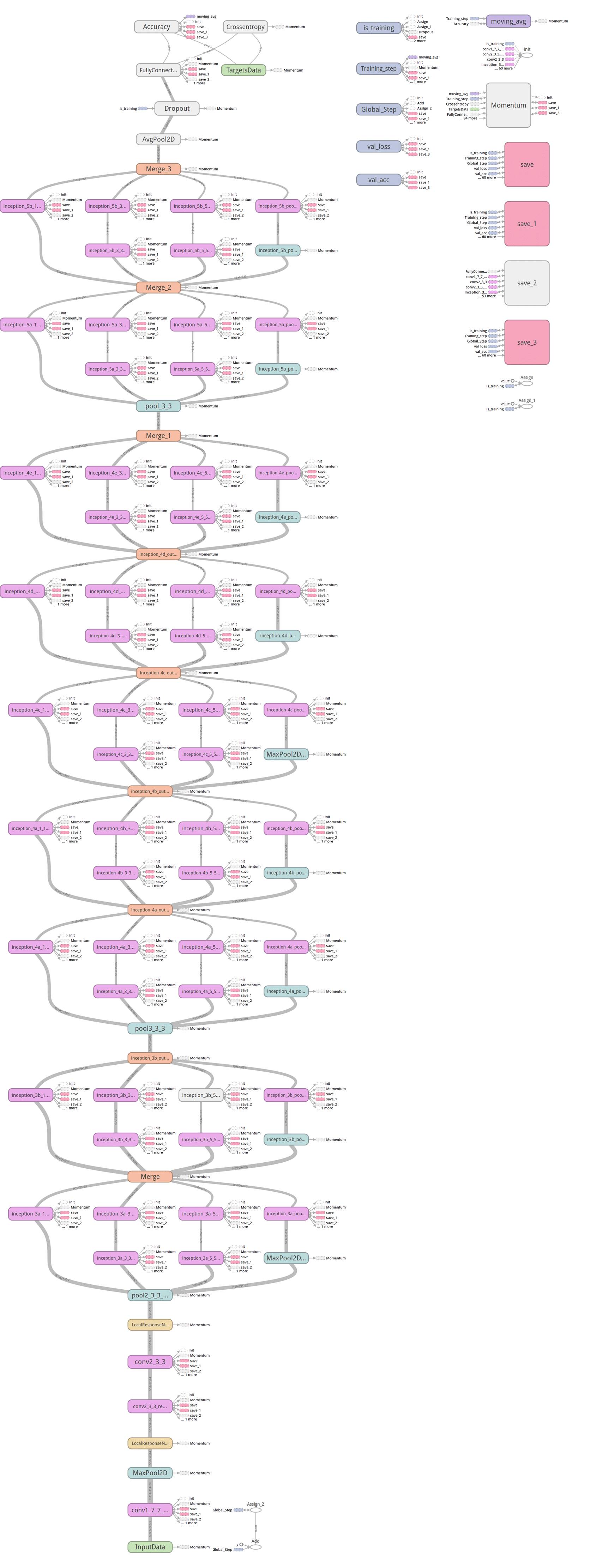
在tensorflow构造GoogLeNet基本的代码在https://github.com/ethereon/caffe-tensorflow中(如果懒得找,原文有展示),作者封装了一些基本的操作,了解网络结构之后,构造GoogLeNet很容易。之后等到新公司之后,作者会试着在tflearn的基础上写下GoogLeNet的网络代码。
GoogLeNet为了实现方便,作者用tflearn来重写了下,代码中和caffe model里面不一样的就是一些padding的位置,因为改的比较麻烦,必须保持inception部分的concat时要一致,这里也不知道怎么修改pad的值(caffe prototxt),所以统一padding设定为same,具体代码(略,原文有展示)
大家如果感兴趣,可以看看这部分的caffe model prototxt, 帮忙检查下是否有问题,代码作者已经提交到tflearn的官方库了,add GoogLeNet(Inception) in Example,各位有tensorflow的直接安装下tflearn,看看是否能帮忙检查下是否有问题,这里因为没有GPU的机器,跑的比较慢,TensorBoard的图如下,不像之前Alexnet那么明显(主要还是没有跑那么多epoch,这里在写入的时候发现主机上没有磁盘空间了,尴尬,然后从新写了restore来跑的,TensorBoard的图也貌似除了点问题, 好像每次载入都不太一样,但是从基本的log里面的东西来看,是逐步在收敛的,这里图也贴下看看吧)
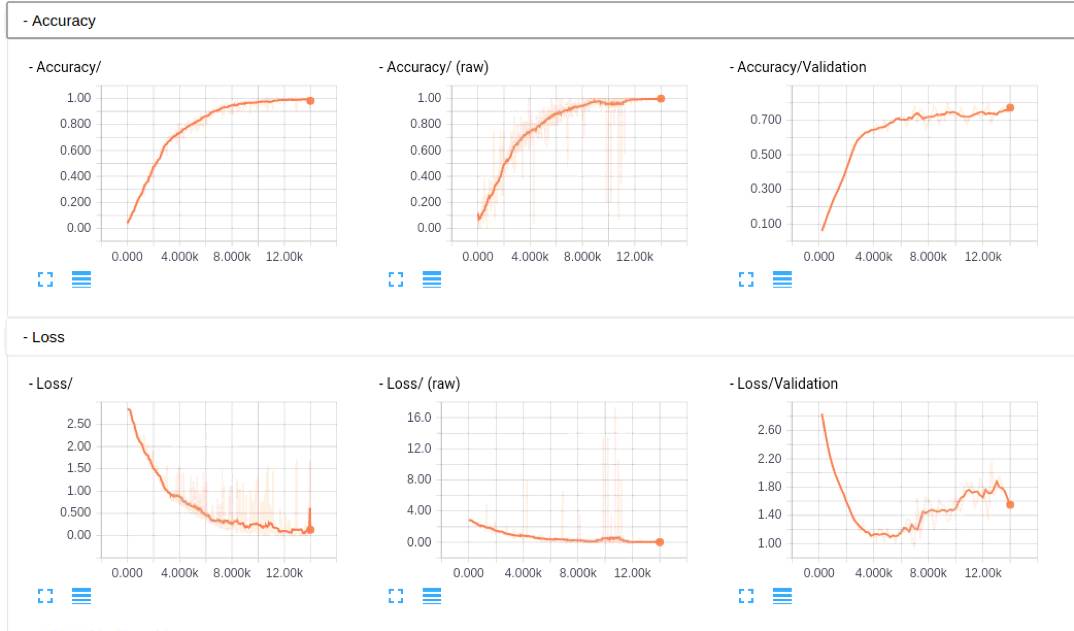
网络结构,这里有个bug,可能是TensorBoard的,googlenet的graph可能是太大,大概是1.3m,在chrome上无法下载,试了火狐貌似可以了:
这段时间到了新公司,工作上开始研究DeepLearning以及TensorFlow,挺忙了,前段时间看了VGG和deep residual的paper,一直没有时间写,今天准备好好把这两篇相关的paper重读下。
VGGnet是Oxford的Visual Geometry Group的team,在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能,如下图,文章通过逐步增加网络深度来提高性能,虽然看起来有一点小暴力,没有特别多取巧的,但是确实有效,很多pretrained的方法就是使用VGG的model(主要是16和19),VGG相对其他的方法,参数空间很大,最终的model有500多m,alnext只有200m,googlenet更少,所以train一个vgg模型通常要花费更长的时间,所幸有公开的pretrained model让我们很方便的使用,前面neural style这篇文章就使用的pretrained的model,paper中的几种模型如下:
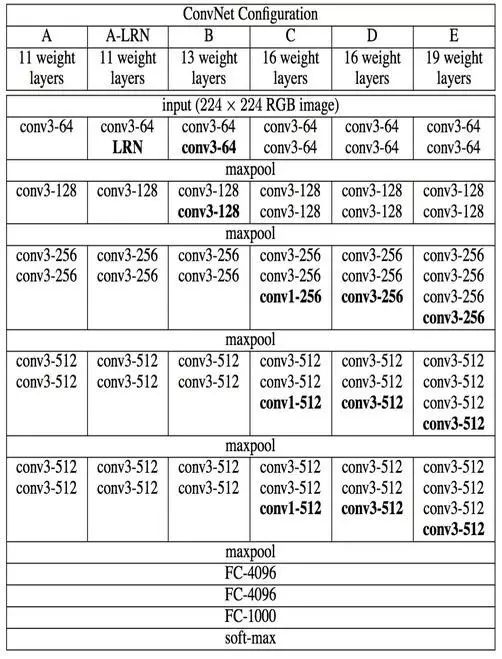

可以从图中看出,从A到最后的E,他们增加的是每一个卷积组中的卷积层数,最后D,E是我们常见的VGG-16,VGG-19模型,C中作者说明,在引入1*1是考虑做线性变换(这里channel一致, 不做降维),后面在最终数据的分析上来看C相对于B确实有一定程度的提升,但不如D、VGG主要得优势在于:
tflearn 官方github上有给出基于tflearn下的VGG-16的实现 from future import division, print_function, absolute_import
import tflearn
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimator import regression
import tflearn.datasets.oxflower17 as oxflower17
X, Y = oxflower17.load_data(one_hot=True)
network = input_data(shape=[None, 224, 224, 3])
network = conv_2d(network, 64, 3, activation='relu')
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = conv_2d(network, 128, 3, activation='relu')
network = conv_2d(network, 128, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = conv_2d(network, 256, 3, activation='relu')
network = conv_2d(network, 256, 3, activation='relu')
network = conv_2d(network, 256, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = fully_connected(network, 4096, activation='relu')
network = dropout(network, 0.5)
network = fully_connected(network, 4096, activation='relu')
network = dropout(network, 0.5)
network = fully_connected(network, 17, activation='softmax')
network = regression(network, optimizer='rmsprop',
loss='categorical_crossentropy',
learning_rate=0.001)
model = tflearn.DNN(network, checkpoint_path='model_vgg',
max_checkpoints=1, tensorboard_verbose=0)
model.fit(X, Y, n_epoch=500, shuffle=True,
show_metric=True, batch_size=32, snapshot_step=500,
snapshot_epoch=False, run_id='vgg_oxflowers17')
VGG-16 graph如下:
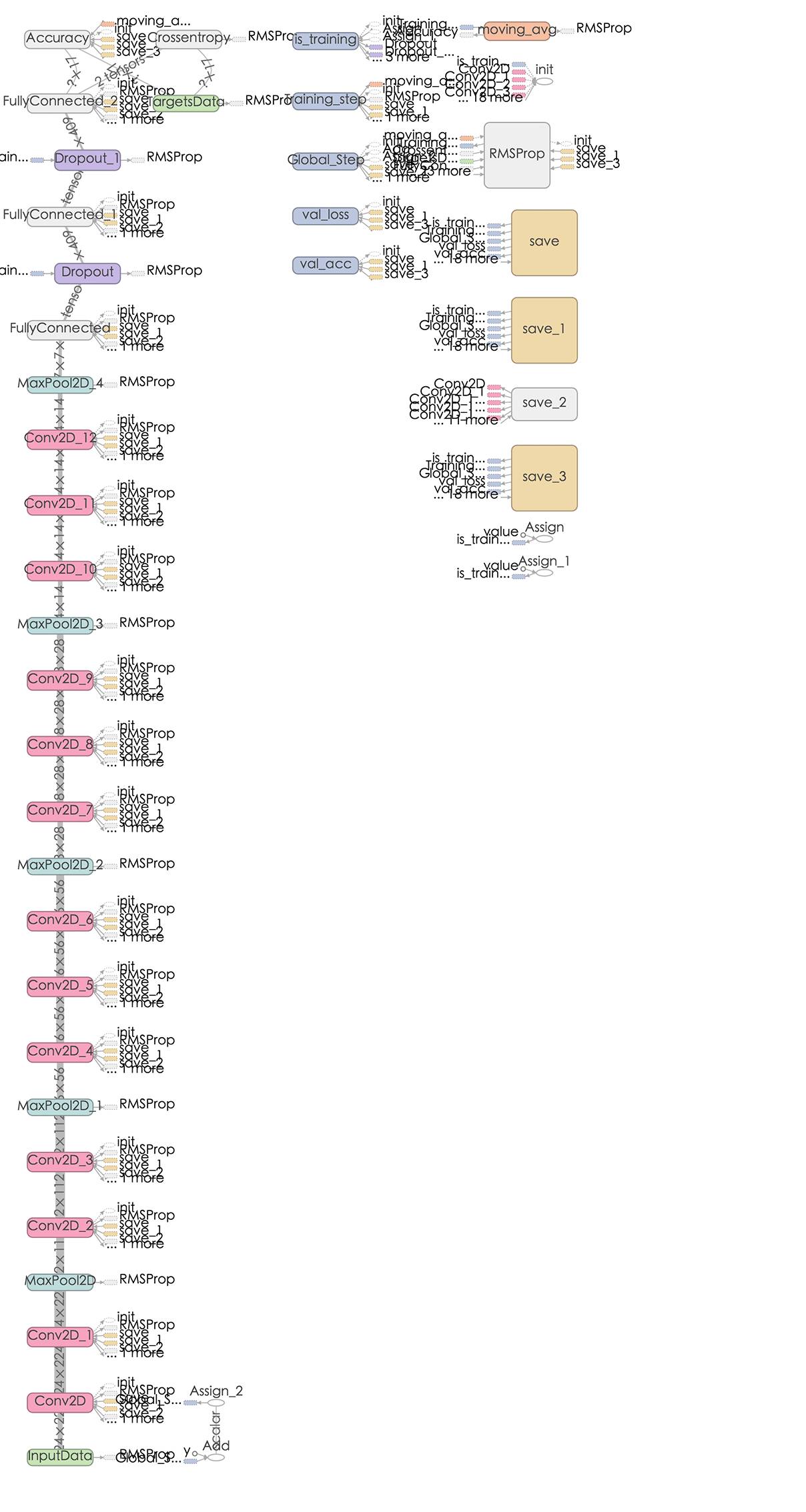
对VGG,作者个人觉得他的亮点不多,pre-trained的model我们可以很好的使用,但是不如GoogLeNet那样让人有眼前一亮的感觉。
一般来说越深的网络,越难被训练,Deep Residual Learning for Image Recognition中提出一种residual learning的框架,能够大大简化模型网络的训练时间,使得在可接受时间内,模型能够更深(152甚至尝试了1000),该方法在ILSVRC2015上取得最好的成绩。
随着模型深度的增加,会产生以下问题:
vanishing/exploding gradient,导致了训练十分难收敛,这类问题能够通过norimalized initialization 和intermediate normalization layers解决;
对合适的额深度模型再次增加层数,模型准确率会迅速下滑(不是overfit造成),training error和test error都会很高,相应的现象在CIFAR-10和ImageNet都有提及
为了解决因深度增加而产生的性能下降问题,作者提出下面一种结构来做residual learning:
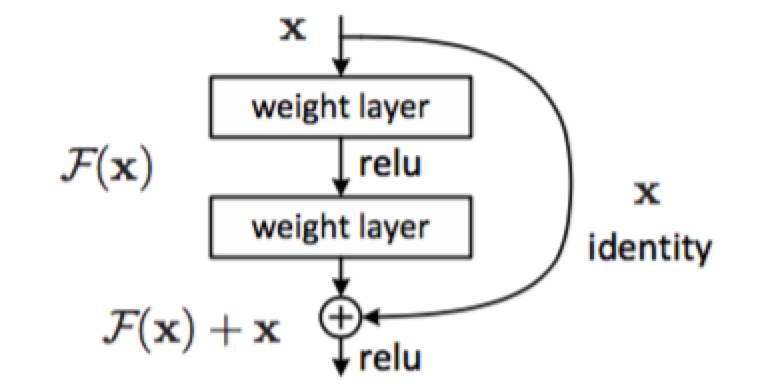
假设潜在映射为H(x),使stacked nonlinear layers去拟合F(x):=H(x)-x,残差优化比优化H(x)更容易。 F(x)+x能够很容易通过”shortcut connections”来实现。
这篇文章主要得改善就是对传统的卷积模型增加residual learning,通过残差优化来找到近似最优identity mappings。
paper当中的一个网络结构:
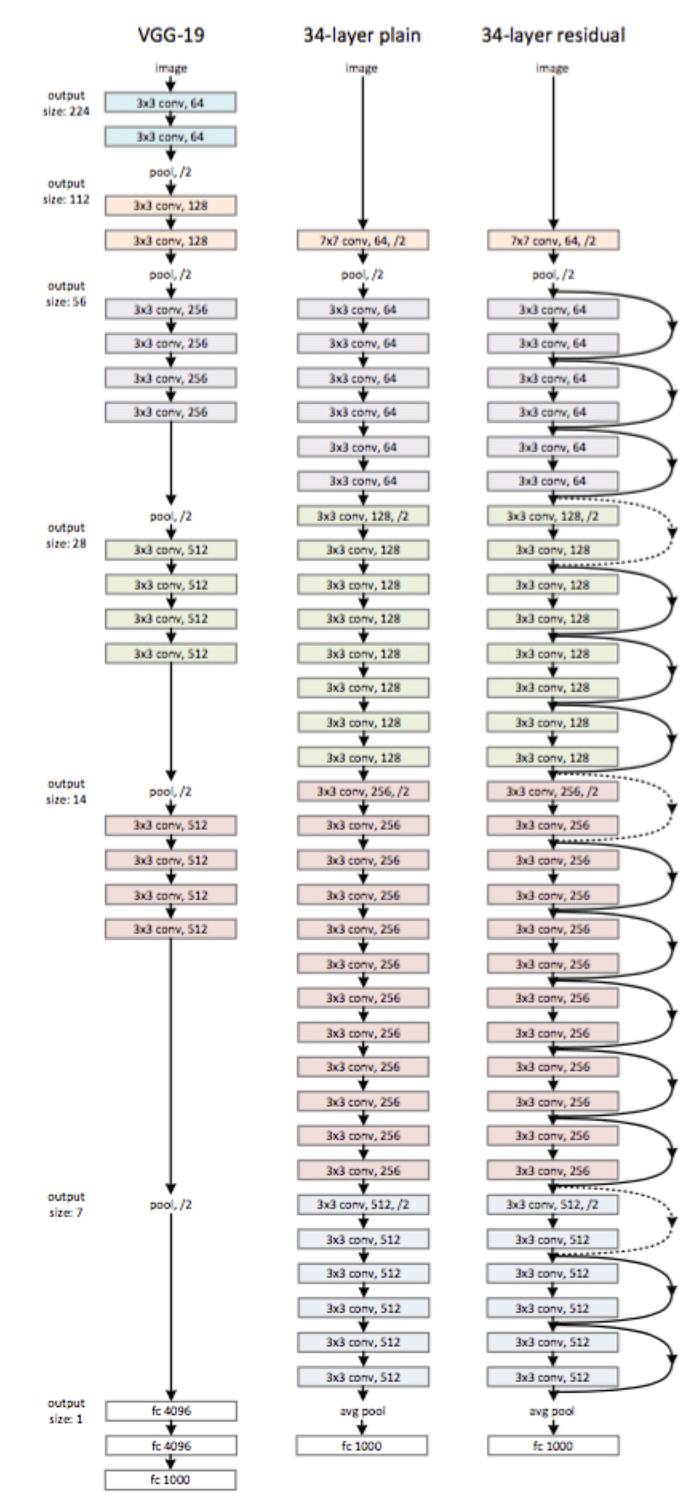
Deep Residual Network tflearn实现原文里面有详细的介绍。
前面几篇文章讲述了在Computer Vision领域里面常用的模型,接下来一段时间,作者会花精力来学习一些TensorFlow在Computer Vision领域的应用,主要是分析相关pape和源码,今天会来详细了解下fast neural style的相关工作,前面也有文章分析neural style的内容,那篇算是neural style的起源,但是无法应用到实际工作上,为啥呢?它每次都需要指定好content image和style image,然后最小化content loss 和style loss去生成图像,时间花销很大,而且无法保存某种风格的model,所以每次生成图像都是训练一个model的过程,而fast neural style中能够将训练好的某种style的image的模型保存下来,然后对content image 进行transform,当然文中还提到了image transform的另一个应用方向:Super-Resolution,利用深度学习的技术将低分辨率的图像转换为高分辨率图像,现在在很多大型的互联网公司,尤其是视频网站上也有应用。
Paper原理
几个月前,就看了Neural Style相关的文章TensorFlow之深入理解Neural Style,A Neural Algorithm of Aritistic Style中构造了一个多层的卷积网络,通过最小化定义的content loss和style loss最后生成一个结合了content和style的图像,很有意思,而Perceptual Losses for Real-Time Style Transfer and Super-Resolution,通过使用perceptual loss来替代per-pixels loss使用pre-trained的vgg model来简化原先的loss计算,增加一个transform Network,直接生成Content image的style版本, 如何实现的呢,请看下图:
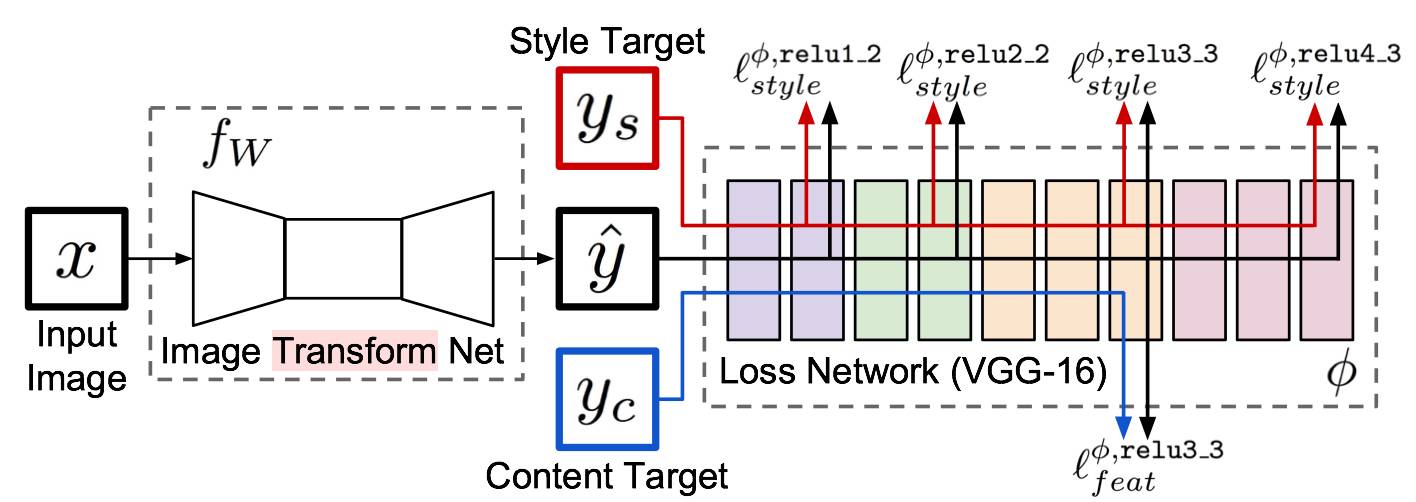
整个网络是由部分组成:image transformation network、 loss netwrok;Image Transformation network是一个deep residual conv netwrok,用来将输入图像(content image)直接transform为带有style的图像;而loss network参数是fixed的,这里的loss network和A Neural Algorithm of Aritistic Style中的网络结构一致,只是参数不做更新,只用来做content loss 和style loss的计算,这个就是所谓的perceptual loss,作者是这样解释的为Image Classification的pretrained的卷积模型已经很好的学习了perceptual和semantic information(场景和语义信息),所以后面的整个loss network仅仅是为了计算content loss和style loss,而不像A Neural Algorithm of Aritistic Style做更新这部分网络的参数,这里更新的是前面的transform network的参数,所以从整个网络结构上来看输入图像通过transform network得到转换的图像,然后计算对应的loss,整个网络通过最小化这个loss去update前面的transform network,是不是很简单?
loss的计算也和之前的都很类似,content loss:
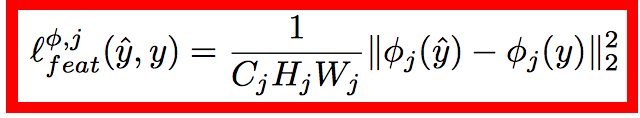
style loss:
style loss中的gram matrix:
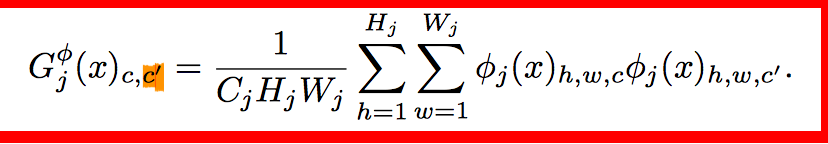
Gram Matrix是一个很重要的东西,他可以保证y^hat和y之间有同样的shape。 Gram的说明具体见paper这部分,作者这也解释不清楚,相信读者一看就明白:

相信看到这里就基本上明白了这篇paper在fast neural style是如何做的,总结一下:
transform network 网络结构为deep residual network,将输入image转换为带有特种风格的图像,网络参数可更新。
loss network 网络结构同之前paper类似,这里主要是计算content loss和style loss, 注意参数不做更新。
Gram matrix的提出,让transform之后的图像与最后经过loss network之后的图像不同shape时计算loss也很方便。
本文的技术内容取得 深度学习工程师 段石石 的发布授权,同时为了阅读体验,内容有些小修改和整合,并精简了部分的实践内容。如果想了解更多的深度学习实践,请移步到 小石头的码疯营 进行阅读。

51CTO粉丝群期待小伙伴们的加入! 四大阵营:IT资讯、IT技术干货、IT无忧、黑科技;小伙伴们可找熊小妹(微信号:maomao-fjc)按兴趣加入各微信群,共同讨论分享IT内容,当然少不了N波红包雨和惊喜大奖的助兴哦
四大阵营:IT资讯、IT技术干货、IT无忧、黑科技;小伙伴们可找熊小妹(微信号:maomao-fjc)按兴趣加入各微信群,共同讨论分享IT内容,当然少不了N波红包雨和惊喜大奖的助兴哦










