
问题导读
1.读取日志的过程中,发生异常本文是如何解决的?
2.读取后,如何过滤异常的记录?
3.如何实现统计点击最高的记录?
日志分析实战之清洗日志小实例5:实现获取不能访问url
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22911
下面我们开始统计链接的点击量,并做排序。
我们统计记录的时候,为了防止空记录等异常的情况,我们创建一条空记录
[Bash shell]
纯文本查看
复制代码
?
|
1
|
val nullObject = AccessLogRecord(
""
,
""
,
""
,
""
,
"GET /foo HTTP/1.1"
,
""
,
""
,
""
,
""
)
|
下面我们开始找点击量最高的链接。
首先获取我们想要的uri
[Scala]
纯文本查看
复制代码
?
|
1
2
3
|
val
uriCounts
=
log.map(p.parseRecord(
_
).getOrElse(nullObject).request)
.map(
_
.split(
" "
)(
1
))
.filter(
_
!
=
"/foo"
)
|
上面的代码做一个简单解释:
p.parseRecord(_)解析记录
p.parseRecord(_).getOrElse(nullObject)如何没有取到值,则使用nullObject,也就是我们上面定义的对象
p.parseRecord(_).getOrElse(nullObject).request也就是我们取到uri
.map(_.split(" ")(1))是取到我们过滤的url,过滤掉不想要的版本等信息
.filter(_ != "/foo")则是再次过滤掉/foo[也就是空记录]
这样就获取了uri,然后我们输出
[Scala]
纯文本查看
复制代码
?
|
1
|
uriCounts.collect.foreach(print)
|
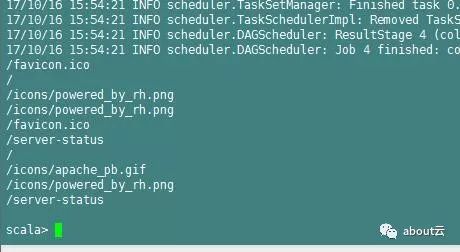
下面我们统计点击量
[Scala]
纯文本查看
复制代码
?
|
1
2
3
4
|
val
uriCounts
=
log.map(p.parseRecord(
_
).getOrElse(nullObject).request)
.map(
_
.split(
" "
)(
1
))
.map(uri
=
> (uri,
1
))
.reduceByKey((a, b)
=
> a + b)
|
rdd转换为数组
[Scala]
纯文本查看
复制代码
?
|
1
|
val
uriToCount
=
uriCounts.collect
|





