可用性和可靠性对于所有 Web 应用程序和 API 服务至关重要。如果您提供 API 服务,您可能体会过流量突增对服务质量的影响,甚至可能造成服务中断。本文介绍了对 API 限流的 4 种常用方法。本文由高可用架构翻译,转载请注明出处。
最初发生这种情况时,对基础架构进行扩容以适应增长是合理的。 但是在 API 服务生产环境中,需要针对具体规模来进行设计和构建,并确保任何坏因素不会影响其可用性。
限制流量可以使 API 服务在下面的场景中更可靠:
某个用户直接或间接造成了流量飙升,我们需要确保对其他用户服务可用。
某个用户向 API 服务发送大量请求。 或者更糟的是,某个用户试图恶意冲垮服务器。
用户发送了大量低优先级请求,但我们希望确保不会影响其他高优先级请求。 例如,发送大量分析数据请求的用户可能会影响其他用户的关键事务。
系统内部产生错误,导致无法处理所有请求,不得不丢弃低优先级的请求。
在 Stripe,通过细致的设计和实现一些限流策略,保障了我们的 API 服务对所有用户的可用性。在这篇文章中,我们将详细介绍这些限流策略、如何对 API 请求进行优先级划分,以及如何安全地使用限流器而不影响现有用户的工作流程。
限流器和负载降级
限流器用于控制在网络上发送或接收的流量速率。什么时候应该使用限流器?If your users can afford to change the pace at which they hit your API endpoints without affecting the outcome of their requests(小编:这句话翻译起来太拗口了,小编的理解限流首先是保护服务提供方,然后不会伤害正常的服务使用方),那么使用限速器就是合适的。如果在请求与请求之间插入间隔不可行,比如对于实时通信场景,那么则需要另外的策略(这超出了此文章的范围,但通常来说需要对基础设施扩容)。
用户可以产生很多请求:例如,批处理支付请求会导致 API 流量持续升高。用户总是可以扩展他们的请求,而不受限流器的影响。
限流器对于大部分使用场景是十分高效的,但有时我们需要完全丢弃低优先级的请求,以确保更多关键请求的处理,这称为负载降级(load shedder)。
负载降级可以根据系统的整体状态而不是正在请求的用户来进行决策。它可以帮助我们应对突发事件,确保核心部分正常工作。
使用不同类型的限流器
我们应该根据场景决定使用何种限流器,以确保其最大程度提高 API 服务的可靠性。
在 Stripe,我们在生产环境中使用4种不同类型的限流器。 第一种,请求限流器,它也是最重要的一个。
请求限流器
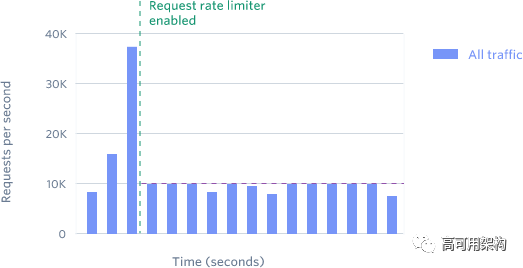
该限流器限制每个用户每秒可发送 N 个请求。
我们的请求限流器在本月已经拒绝了数百万个请求,特别是对于用户无意运行脚本产生的测试请求。
我们的 API 在测试和生产模式下提供相同的速率/流量限制行为。 这样做有利于开发人员的体验:在从开发切换到生产模式时,程序或脚本不会遇到副作用。
在分析了我们的流量模式之后,我们为请求限流器增加了适应请求激增的能力,比如用于电商中的抢购。
并发请求限流器
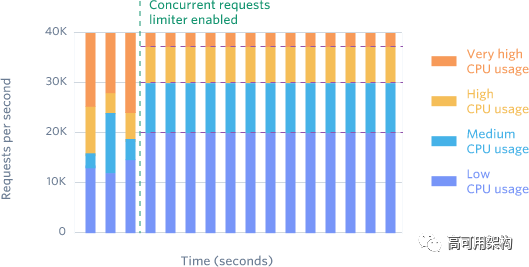
相对于第一种请求限流器,限制每秒最高请求数,这种限流器则是限制最高并发请求数。有些 API endpoint 对外部资源依赖多,用户经常处于请求-等待返回-重试。这些重试继续加剧了已经超载的服务。并发请求限流器有助于很好地解决这个问题。
我们的并发请求限流器很少被触发,本月只有12000次请求,它帮助我们有效地控制 CPU 密集型 API enpoint。在我们开始使用并发请求限流器之前,我们经常需要处理由于用户同一时间产生太多请求而造成的资源争用。并发请求限流器完全解决了这个问题。
仔细地调整该限制器策略是非常必要的,它比请求限流器会更频繁地拒绝请求。
基于使用量的负载降级
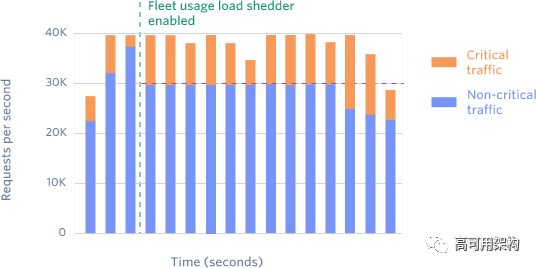
我们将流量分为两种类型:关键 API 请求(例如,创建订单)和非关键请求(例如,列出历史订单)。我们有一个 Redis 集群,用于计算当前每种类型的请求数量。
我们总是为关键请求预留一小部分冗余。例如,我们的预留比例是20%,那么超过 80% 的非关键请求将被拒绝服务,并返回503的状态码。
基于 Worker 利用率的负载降级
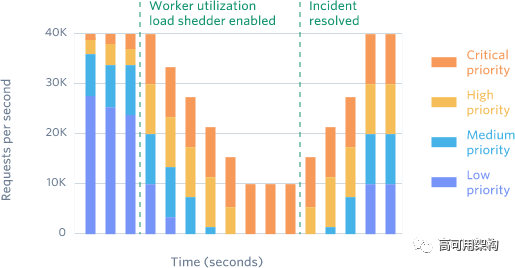
大多数 API 服务使用一组 worker 线程/协程以并行方式独立地处理请求并响应。 这种负载降级是最后的防线。
我们将流量分为4类组成:
关键 API 请求
HTTP POST 方法
HTTP GET 方法
测试请求
我们追踪可用的 worker 数量。如果某个 worker 太忙,无法处理分配给它的请求,它会缓慢降级非关键请求,当然是先从测试请求开始。如果降低测试请求的过程中,worker 的处理能力恢复到好的状态,那我们就可以开始缓慢地恢复流量(取消降级)。
缓慢地进行降级和恢复是非常重要的!比如这个场景:“我完全丢弃了测试请求的流量,一切都很好!我把它恢复回来,噢一切又变糟了!”。我们用了大量的尝试和错误来调整降级和恢复的速率。
这种负载降级限制了已经发生事件的影响,控制了近一步的损害,比如你们知道的“雪崩效应”。
构建限流器实践
上面已经概述了我们使用的四种类型的限流器,接下来我们来谈谈它们的实现。有什么限流算法?以及如何实现?
我们使用令牌桶算法 [2] 来进行流量限制。该算法有一个集中的桶,为每一个请求分配一个令牌,并不断地缓慢地在桶中放入令牌。 如果桶为空,则拒绝该请求。在我们的例子中,每个用户都被分配一个桶,每当他们产生一个请求时,我们从这个桶中移除一个令牌。
我们通过 Redis 来实现我们的限速器。 既可以自己搭建和运维 Redis 实例,或者如果已经使用 AWS,则可以使用 ElastiCache 这样的托管服务。
当你考虑要实现类似的限流器时,要注意下面几点:
将限流器安全地插入到您的中间件链(middleware chain)中。要确保如果限流器代码中出现错误(例如 Redis 发生故障),请求不会受到影响。需要捕获所有级别的异常,以确保 API 正常工作。
向用户显示清晰明白的异常。首先确定将什么样的异常显示给用户。比如是否将 HTTP 429 或 HTTP 503 展示给用户。同时任何返回给用户的信息应该是可操作的,以避免用户不知所措。
建立保障措施,以确保可以关闭限流器。确保有“终极大杀器”可以完全禁用限流器,设置报警和监控指标以了解触发频率。
低峰启动或发布,并注意观察流量变化。评估每个限流的策略并做出调整。找到不影响用户现有请求模式下的限流阈值。这可能涉及与用户的开发人员一起修改其代码,以便新的限流策略对他们有效。
总结
流量限制是使 API 具备水平扩展最有效的方法之一。 这篇文章中描述的不同限流策略在一开始并不是必需的,一旦你意识到需要限流的话,你可以逐渐地引入它们。
我们的建议按照以下步骤为基础设施引入限流策略和机制:
首先建立一个请求限流器。 它是防止“请求洪流”最重要,也是我们最常用的一种限流器。
逐渐地引入后面三种限流器,以应对不同类别的问题。
在基础架构中添加新的限流策略和限流器时,应遵循良好的启动发布方式。 应随时处理错误,随时可关闭,同时依靠监控指标来查看其触发频率。
此外,基于我们在 Stripe 生产环境实际使用的代码,我们创建了一个 gist [3],分享了一些实现细节。希望它对你有帮助!
关于 Stripe
Stripe Inc 是美国目前估值最高的 Fintech 初创公司,Stripe 是一家在美国及全球专注支付集成服务的科技创业公司,提供集成银行系统、信用卡系统以及 Paypay 的支付服务。
相关链接
本文英文版: https://stripe.com/blog/rate-limiters
https://en.wikipedia.org/wiki/Token_bucket
https://gist.github.com/ptarjan/e38f45f2dfe601419ca3af937fff574d
推荐阅读
本文由魏佳翻译,英文作者 Paul Tarjan @ptarjan,转载请注明出处,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号










