全球机器智能峰会(GMIS 2017),是全球人工智能产业信息服务平台机器之心举办的首届大会,邀请来自美国、欧洲、加拿大及国内的众多顶级专家参会演讲。本次大会共计 47 位嘉宾、5 个 Session、32 场演讲、4 场圆桌论坛、1 场人机大战,兼顾学界与产业、科技巨头与创业公司,以专业化、全球化的视角为人工智能从业者和爱好者奉上一场机器智能盛宴。

5 月 27 日,由机器之心主办、为期两天的全球机器智能峰会(GMIS 2017)在北京 898 创新空间顺利开幕。中国科学院自动化研究所复杂系统管理与控制国家重点实验室主任王飞跃为本次大会做了开幕式致辞,他表示:「如今人工智能非常热,有人说再过几年人类甚至不如鞋底聪明,50% 甚至 70% 工作被人工智能取代。」王飞跃对此表示很震惊,但并不认同,他又说:「情况是,再过几年,人类 90% 的工作由人工智能提供,就像今天我们大部分工作是由机器提供的一样。我们的工作就是尽快让我们的鞋底也像人一样聪明,而不是鞋底比我们聪明,并希望机器之心主办的这次全球机器智能峰会让我们知道人工智能会提供一个更美好的未来。」。
大会第一天重要嘉宾「LSTM 之父」Jürgen Schmidhuber、Citadel 首席人工智能官邓力、腾讯 AI Lab 副主任俞栋、英特尔 AIPG 数据科学部主任、GE Transportation Digital Solutions CTO Wesly Mukai 等知名人工智能专家参与峰会,并在主题演讲、圆桌论坛等互动形式下,从科学家、企业家、技术专家的视角,解读人工智能的未来发展。

下午,加利福尼亚大学伯克利分校人工智能方向在读博士吴翼发表了主题为《价值迭代网络》的演讲,探讨分享了如何通过学习规划计算,使得机器具有更好的泛化能力。
下面是吴翼演讲的主要内容:
价值迭代网络

大家好!我叫吴翼,目前是 UC Bekerley 第三年人工智能方向的博士生。我今天来展示的工作,叫价值迭代网络(Value Iteration Network)。这项工作在刚刚在去年巴塞罗那结束的机器学习顶级会议 NIPS 上,获得大会唯一的最佳论文奖项。
动机
这项工作的出发点,也是 Berkeley AI Lab 的一个使命,那就是研发自动机器人,希望有一天这样的场景会发生:某天早上你对你家的机器人说:「帮我从冰箱拿瓶牛奶」。然后它就打开冰箱,看到这样的冰箱场景,然后挪开前面的苹果来拿到放在最后面的牛奶。
这项工作的难点在于,冰箱里面的样子每天都是不同的。所以这就要求机器人背后的算法有一定的泛化能力。我相信在座的大家每天都会进行类似的动作,但是这对于目前的机器人来说,还是太难了。
当然我也相信,很多人都认为,深度强化学习,能够有一天帮助我们达成这一点。
背景介绍
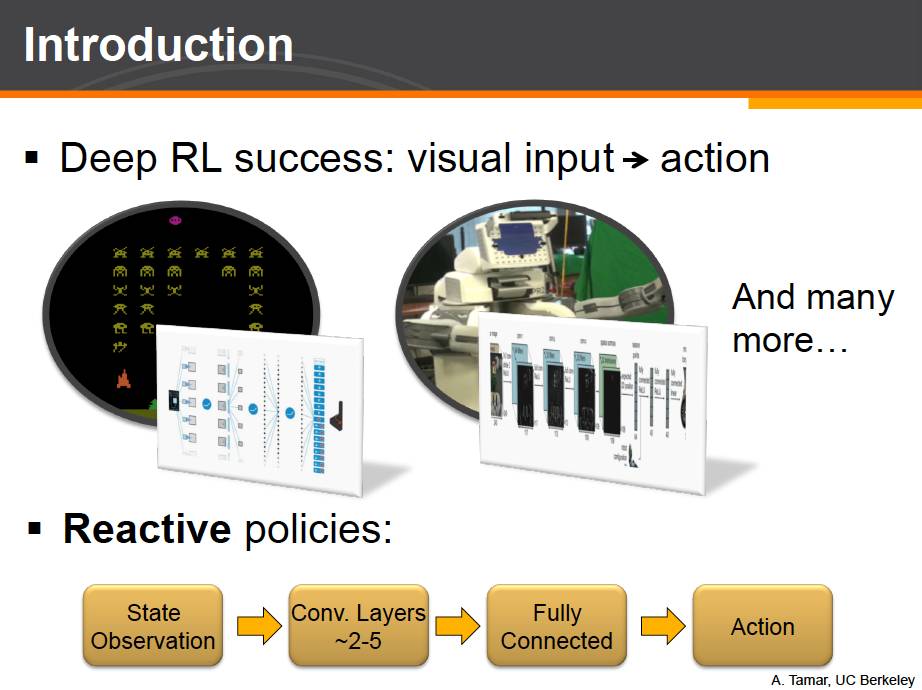
因此,本项工作的另一个出发点就是,在近些年,深度强化学习可以成功的通过学习,单纯从图像输入,做出复杂的决策。比如玩 Atari 游戏,或者操作真实机器人,等等。在这些最近的工作中,有一个看起来让人有些惊讶的事实,那就是这些工作所采用的深度学习网络结构,和计算机视觉领域中的图片分类的神经网络非常类似。他们都有一系列卷积层来做特征提取,然后紧跟着一两个全连接层产生输出。
当然,我们已经知道了,通过反应式网络,已经足以解决一些复杂的问题。但是,这些网络结构,是否真正理解这些复杂问题?那么,什么算是真正的理解呢?这个问题很难很清楚的定义。这里让我们尝试利用一些简单的强化学习实验来回答这个问题。这个实验我们称之为格子迷宫问题,grid world。在这个问题中,红色点代表机器人,绿色的点代表目标点。机器人需要从起点移动到终点并躲避开障碍物。这项任务相对简单的原因是,机器人可以看到完整的地图信息,知道他的位置以及终点位置。
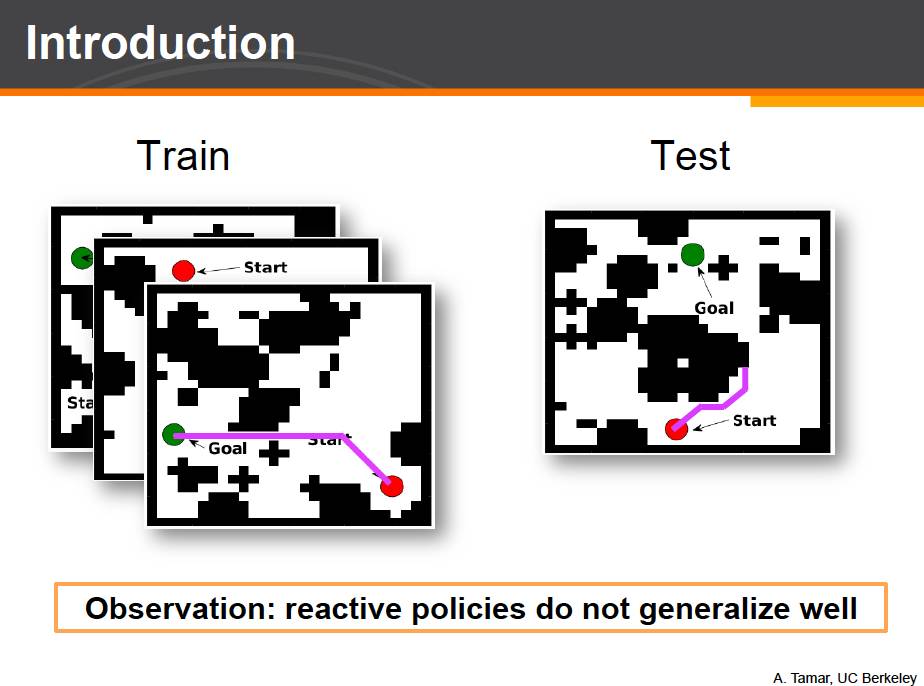
但重要的是下面这个发现。完成了网络训练之后,我们利用这个训练好的网络,并将之放置到不同的有着随机障碍和起点终点位置的迷宫环境中。我们希望知道这个训练好的神经网络是不是真的理解这项任务的本质要求。如果这个网络真的能做到理解 understand,那么及时给定一个他从未见过的迷宫环境,他也应该有能力成功的到达终点。对应到一开始我们提到的开冰箱的例子,这也就是所谓的泛化能力。让人感到意外的是,反应式网络结构并不能在新的迷宫环境中成功泛化。训练好的神经网络可以在训练中出现过的地图上表现完美,但是在没有见过的测试地图上,它并不能很好的完成任务。
那么为什么反应式网络不能很好的泛化呢?我们之前讨论的任务都需要连续做出一些决策。也就是,这些决策需要一定的规划的计算,也就是 planning。比如在迷宫问题中,我们记录下来我们从原点出发的路径,然后比如进行一些推理和长期规划。
深度强化学习通过不同的算法学习了一个从输入图片到决策的映射函数。尽管有多种算法,但是总体上深度强化学习确实在某种程度上进行规划计算。
比如 policy gradient 算法就会学习出有着较高总体回报的决策;Q-learning 算法会学习有着较高 Q 值 - 也就期望的最终回报较高的策略;模仿学习则会让人来做出好的规划,并让机器来模仿人的行为。这里我们注意到,深度强化学习的算法,确实会在训练环境中进行一些规划计算。但是这些训练出来的神经网络,即使是在最新的一些工作中,所展现出来的泛化能力也多局限于训练任务中。也就是,通过在训练任务中的训练,神经网络有了一定的在训练任务中泛化的能力。
但是,如果我们将神经网络放置于一个全新的任务当中呢?在一个全新的任务中,神经网络需要根据新的任务和环境进行重新规划。但是目前的神经网络结构并不能学会这样的能力,并且,尽管现在的网络都很复杂,但这些结构多是简单的堆积,并没有对于规划计算的比较好的直接的表达。在这个工作中,我们提出了一个新的网络结构。这个结构有能力学习如何进行规划。我们也将展示,这个网络结构能够更好的泛化。
模型
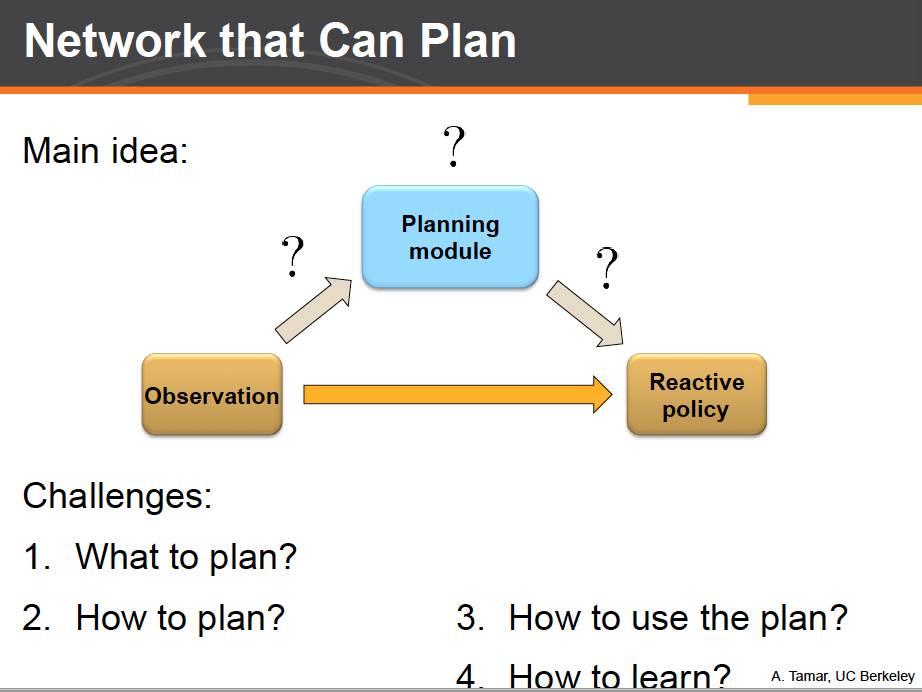
下面来看我们的工作。那么该如何设计一个可以规划的网络呢?我们从反应式网络出发,并在传统的反应式网络结构之上,额外增加一个规划模块,并利用规划模块提供的额外信息来做更好的决策。
那么现在就有了如下几个问题:规划什么?怎么个规划?如何利用规划模块的信息?如何端对端的来学习网络参数?我们依次来解答这些问题。
价值迭代规划
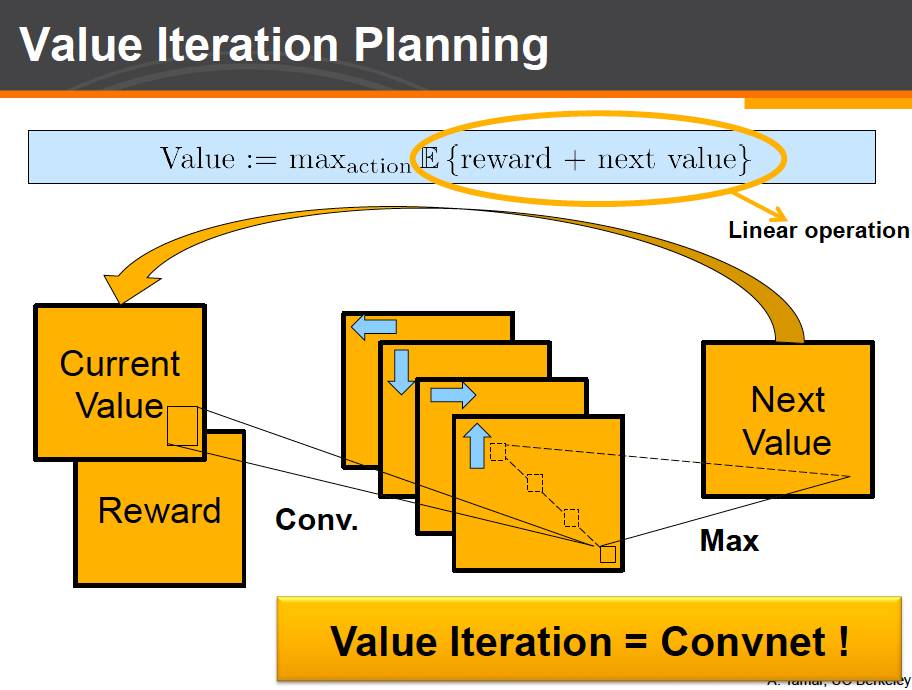
首先,一个经典的规划算法叫 value iteration。值迭代算法。这个算法会对每一个状态计算一个值函数。这个值函数代表了从当前状态出发,进行最佳长期规划后所能得到的期望收益。
那么,我们该如何计算值函数呢?
Value iteration 算法反复利用上面面这个式子迭代来计算每个状态的值直至收敛。我们具体来看这个式子。考虑一个状态的 value 值的迭代计算。在这个式子里:我们首先枚举决策,一个决策对应一个目标状态的概率分布,我们计算出当前的回报和可以到达状态的当前 value 值的期望的和。然后选出最佳决策对应的计算结果作为该状态的当前 value 值。具体迷宫问题而言,每一个状态就是一个格子,而一个决策就是一个对于周围8个相邻格子的一个概率分布。对于每一个决策,我们将这个概率分布与相邻格子的值相乘求和后得到当前决策的计算结果。然后我们对于所有的决策取出最大值最为当前状态的计算结果。
每一个决策,可以对应于卷积神经网络中的一个通道(channel)。不同的通道有不同的计算结果。最后一步求最大值的操作则对应于卷积神经网络中的最大池化层(max pooling)。这一层计算我们对于相同位置不同通道的结果取最大值。
卷积加池化的组合就完全对应了 value iteration 算法中的一次 value iteration 迭代。如果要进行多次 value iteration 计算也很容易。我们可以和一般的神经网络一样,将上述计算反复堆叠形成深度较深的网络。
于是,我们成功地将一个经典的规划算法和经典的卷积神经网络建立了联系。我们可以将一个规划算法,在神经网络中表达成卷积神经网络的形式。
价值迭代网络
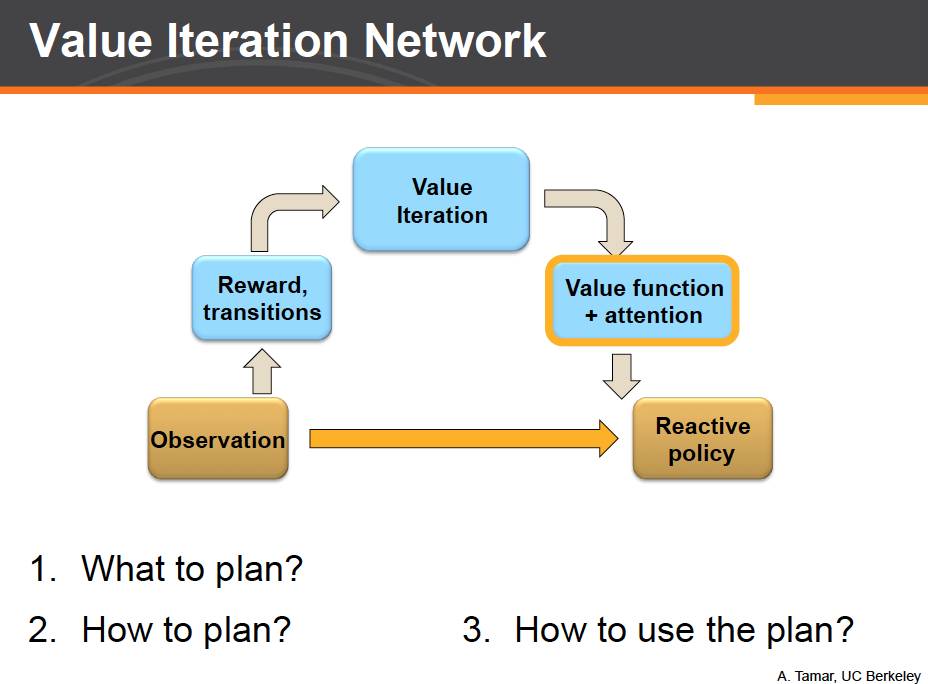
现在我们可以将规划算法 value iteration 作为一个模块嵌入到之前我们提及的网络结构中。我们称之为 value iteration network,简称 VIN。
回到之前的四个问题。对于第一个问题,我们知道,value iteration 算法的计算依赖于每个状态可以得到回报,和状态之间的转移。而这些我们都可以利用一些现有的神经网络结构从输入图像中进行直接提取。
对于第二个问题,我们已经知道 value iteration 算法可以表示成卷积神经网络的形式进行计算。
对于第三个问题:我们知道 value iteration 模块已经包含了我们所需要的长远规划信息。我们只需要用另一个神经网络将这些规划结果作为额外的信息传递给反应式网络最后输出层即可。此外我们还注意到,做决策时我们往往只需要规划模块中一小部分状态的 value 值即可。所以这里我们还可以利用上注意力机制 attention 来更好的做出决策。

最后,对于第四个问题,注意到 value iteration network 中的每一个部分从形式上都是传统神经网络中的某个常见模块。因此我们可以用 backpropogation 对于整个网络进行端对端的训练!而由于有个 value iteration 模块,整个网络也就有了学习规划和进行长期规划的能力。
实验结果
实验
我们的实验中,我们考虑两个主要问题:1. 我们的网络到底能不能学会规划?2. 这样的网络能不能更好的泛化?
迷宫问题
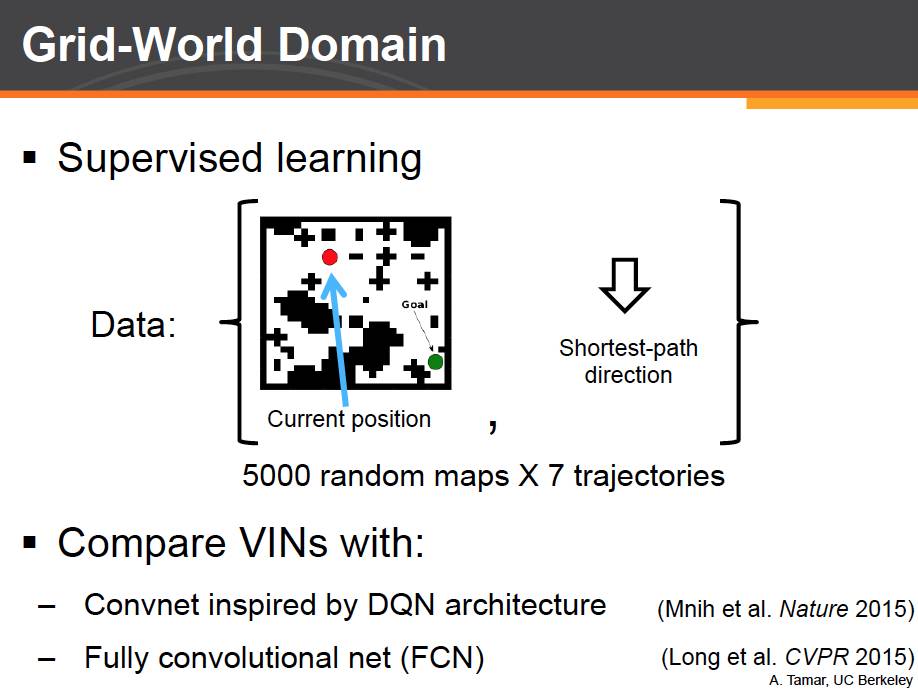
我们先从迷宫问题着手。我们生成了 5000 个随机地图,不同的起始终点位置以及他们之间的最短路径。我们在训练中使用监督学习。神经网络需要在给定地图和终点,以及机器人当前的位置,做出正确的决策。我们将我们的 vin 网络和其他当前最好的反应式网络进行对比。
由于是监督学习。我们直接比较网络在最短路径上每一个位置做出的决策是否正确。从这张图上我们可以看到,从预测正确率上来看,似乎所有的网络的在测试集上的预测正确率都差不多。
但注意到,在这个任务中我们并不关心单独某个正确率。我们关心的是整个任务的成功率!也就是机器人是否能够从起点开始做出连续的正确决策并到达终点。这里我们可以发现,反应式网络由于缺乏长远规划的能力,随着地图大小的增加,其成功率大幅下降,而 VIN 则始终保持着不错的成功率。这是因为,这些反应式网络通过学习记住了训练集中的某些特定场景,而随着地图增大,测试集中大量出现训练集中没有出现的场景,这就导致了这些网络的失败,而 vin 则真正学会了如何进行重新规划。
这是一个 vin 在测试集上的输出。绿色为最短路,红色为 vin 的输出结果。注意到虽然没有跟从最短路,但 vin 依然做出了有效的决策,避开了所有障碍并达到了终点。
感知 & 控制

对于 vin 最重要的一点是,由于 vin 仅仅是一个特定形式的神经网络,他可以作为一个部分轻松的和其他神经网络结构组合。比如,我们这里将 VIN 应用到了真实的超高分辨率的图线应用中。这个图片是火星地表的一副俯拍图。任务的目标是让火星机器人在火星地表上绕开危险的沟壑,并前进到指定位置。我们只需要在 vin 中增加一些图像处理层,就可以直接将 vin 应用到这个任务中了。图中蓝色是最短路,紫色路线就是 vin 的输出,利用 vin 提供的路线通过 nasa 的数据计算,机器人可以成功的到达目的地。
在另一个实验中,我们考虑联系空间的控制问题。在这个任务中,我们需要通过施加额外的力来控制一个有质量的小钢球绕开障碍物到达目的地。注意到 vin 处理的都是离散的状态,而这里状态都是连续的。因此我们将输入图片离散化成一些低分辨率的图片并输入 vin 中,并向之前迷宫问题一样进行规划。最后反应式网络的输出层则合并了连续的输入低层次信息以及 vin 网络提供的更高层次离散信息进行综合决策。
我们利用传统的强化学习算法进行训练,并将 VIN 和反应式卷积神经网络进行对比。同样,在测试集中,我们将采用与训练集完全不同的障碍物和起点终点组合。这里我们展示了在测试集中,小钢球最终距离目标位置的距离的分布。蓝色是 vin 的结果。我们可以发现,相比卷积神经网络,vin 的输出结果非常的精准。
注意到这是一个单独的固定的神经网络的输出结果。这个网络读入图片的信息和小钢球的位置,并输出对小钢球的作用力。这些测试集中的环境都是在训练是没有出现过的。Vin 并不是一直成功,但是显然 vin 展示了一种很合理的移动策略。
更多实例
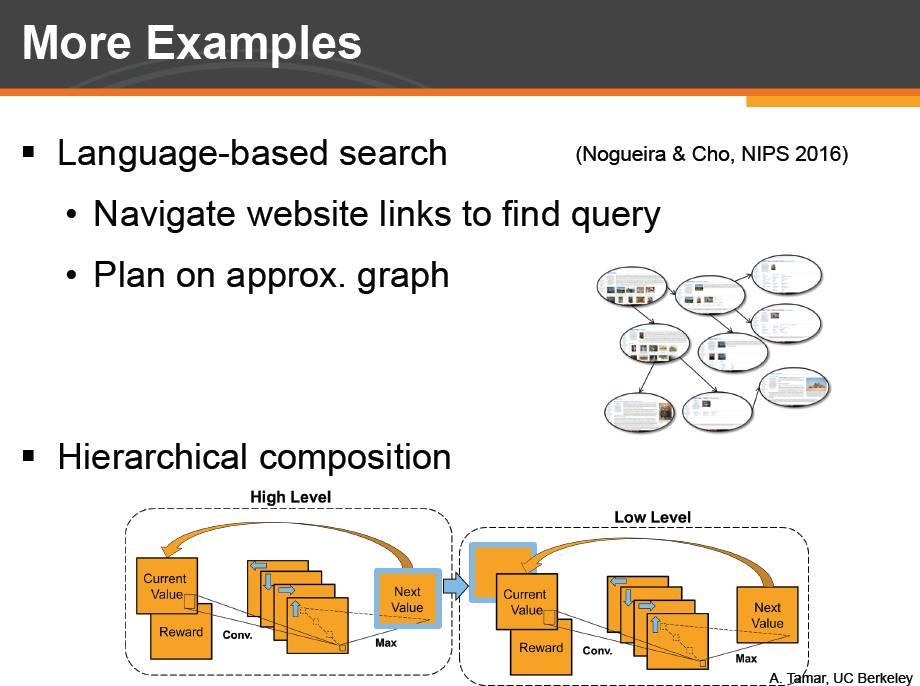
除此之外,我们还将 VIN 应用到了一个完全不同的领域,自然语言处理。这个任务,WebNav,是给定一个问题,并将用户随机放到一个维基百科页面上。问题的答案会处在另一个随机选定的维基百科页面上。用户需要通过点击网页链接在而找到问题答案所在的页面。在 WebNav 的原本论文中提出了一个基于反应式网络的方案。我们在维基百科中选出了 3% 的页面组成了一个近似图并在近似图上进行规划。我们将 vin 的输出作为额外信息作为反应式网络的输入。我们发现利用 vin 的额外信息,原文提出的反应式网络也有了更好的泛化能力。
最后,我们也可以堆叠组合多层的 value iteration 模块,来对问题进行不同层次的具体规划。
总结
最后总结一些我们的工作。最重要的一点就是:通过学习规划计算,learning to plan,我们可以使得网络有着更好的泛化能力。基于一个,可求导的规划算法 value iteration,我们提出了新的有能力学习规划计算的网络结构,vin。Vin 作为一个额外模块,可以轻松的与不同的其他网络结合来解决不同的问题。最后,vin 的灵活性和可用性怎样呢?这取决于我们希望对强化学习的模型本身进行多强的干预。
Model-Free RL 几乎不对任务本身有任何的先验假设,而 model-based RL 或者 inverse RL 则需要对任务进行精确的近似。Vin 可以认为是一个介于两者中间的方法。保留了 model-free RL 的灵活性,有着比较好的泛化能力,却也不像 model-based RL 那样需要对任务有着很强的先验知识。当然还有很多的相关的工作,这里不多作介绍。
未来的工作

未来我们希望能够采用更多的不同的规划算法,也希望能够将更多的更加复杂的结构加入的神经网络中,来解决更加复杂的问题。
更多有关GMIS 2017大会的内容,请点击「阅读原文」查看机器之心官网 GMIS 专题↓↓↓