来源: arXiv
作者:文强
【新智元导读】我们能够制作出一个统一的深度学习模型,让这个模型解决多个领域的许多不同问题吗?谷歌研究人员提出了一个多模式适用的架构 MultiModel,用单一的一个深度学习模型,学会文本、图像和翻译这些不同领域的 8 种不同任务,朝“一个模型解决所有问题”迈出了重要一步。

我们能够制作出一个能解决多领域不同问题的统一深度学习模型吗?
在深度学习研究领域,多任务适用模型(multi-task model)是一个由来已久的课题。
此前已经有研究表明,多模式适用学习(multi-modal learning)能够在非监督学习中,提升习得的表征,还能够被当做先验知识解决不相关的任务。
但是,还没有人提出能够在同一时间解决多个任务的多模式适用模型(competitive multi-task multi-modal model)。
今天,谷歌研究人员用他们上传到 arXiv 网站的论文《用一个模型学会所有问题》(One Model to Learn Them All),朝解决这一任务迈出了积极的一步。
他们提出了一个多模型适用的架构 MultiModel,用单一的一个深度学习模型,学会各个不同领域的多种不同任务。
实验结果,谷歌研究人员提出的模型在所有上述任务中都取得了良好的结果——虽然具体到一项任务,结果并不是当前最佳的。
MultiModel:1 个模型同时解决 8 个不同领域的问题
具体说,谷歌研究员同时在以下 8 个任务上训练 MultiModel:
(1)WSJ 语料库
(2)ImageNet 数据集
(3)COCO 图说生成数据集
(4)WSJ 语义解析数据集
(5)WMT 英-德翻译语料库
(6)与(5)相反:德-英翻译语料库
(7)WMT 英-法翻译语料库
(8)与(7)相反:德-法翻译语料库
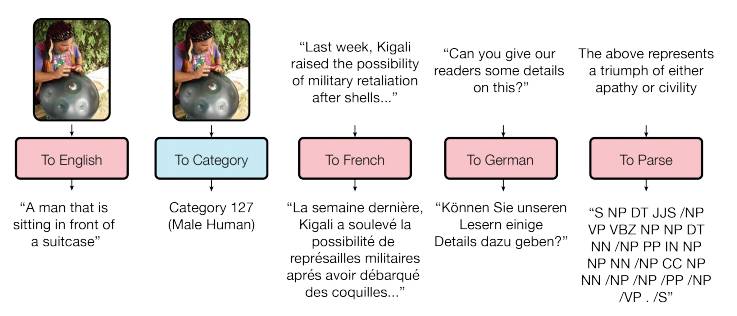
图1:MulitModel 能够完成不同领域不同任务。其中,红色表示语言相关的任务,蓝色表示分类相关的任务。
图1 展示了从模型直接解码得到的一些结果。从上图可见,MultiModel 能够生成述说、为图像分类、完成从法语到德语的翻译,并且构建语义分析树。

表1 展示了模型在联合训练 8 个不同任务和分别单独训练时取得的不同结果。可见,联合训练的结果相比单独会稍微低一些。
Modality Net:多模式适用模型的关键中间量
尽管 MultiModel 只是完成“统一模型”的第一步,谷歌研究人员表示,他们从这项工作中得出了两大关键:
要使用不同类型的输入数据训练模型,需要一些子网络,这些子网络能将输入转化到联合表征空间上。这些子网络被称为 “模式网”(modality net),因为它们分别对应具体的模式(比如图像、语音、文本),并决定了外部领域和统一表征之间的转变(transformation)。
论文作者设计让 modality net 拥有以下特征:①计算效率最高(computationally minimal),②促进 heavy 特征提取,③确保主要的计算都发生在模型中与领域无关的地方。
由于模型是自回归的,modality net 需要先转变为输入进入统一的表征空间,之后再转变为输出。因此,作者表示,在设计上有两个关键的地方:
MultiModel 由多个部分构成,比如不同的卷积层、注意力机制和混合专家层。每个部分此前都没有在其他任务上训练过。例如,卷积层此前没有处理过文本或语音任务;混合专家层也没有处理过图像或语言相关的任务。
作者发现,每个单独的模块对于相应的任务而言都十分重要,比如注意力机制在解决与翻译相关的任务时,远比在处理图像任务中重要。
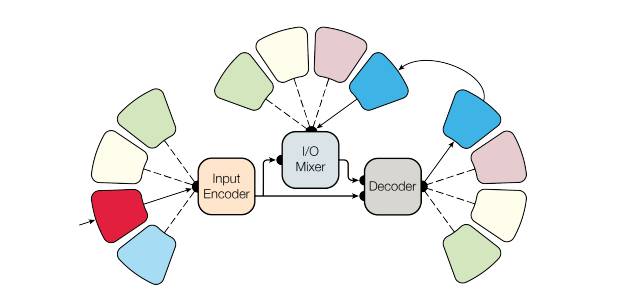
MultiModel 架构:MultiModel 架构由几个 modality net、1 个编码器,1 个 I/O mixer,以及 1 个自回归解码器构成。其中,编码器和解码器都包含有卷积层、注意力机制和稀疏门控混合专家层这 3 种计算单元(block),因此能够解决不同领域的多种问题。
但是,这个模块的存在并不会损害整体的性能,比如存在注意力机制,并不会降低整个架构处理图像任务的性能。
实际上,在实验中,注意力机制和混合专家层都稍微提升了 MultiModel 在处理 ImageNet 数据集的性能——按理说,图像任务并不怎么用到注意力机制和混合专家层(见下)。


摘要
深度学习在语音识别、图像分类、翻译等多个领域取得了丰硕的成果。但是,对于每个问题,研发出一个能很好地解决问题的深度模型,需要对架构进行研究和长时间的调整。我们提出了一个单一的模型,在跨多个领域的许多问题上取得了良好的结果。需要指出,这单一的一个模型在 ImageNet、多语种翻译任务、图说生成(COCO 数据集)、语音识别语料库和英语语义解析任务上,同时进行训练。我们的模型架构来自多个域,包含卷积层、注意力机制和稀疏门控层。这些计算单元(block)中,每一个对于训练任务的一小部分而言都至关重要。有趣的是,即使某个单元对某个任务而言并非必要,我们观察到添加这个单元并不会影响整体性能,在大多数情况下,还能提高完成各项任务的性能。我们还表明,具有较少数据的任务主要受益于与其他任务的联合训练,而大规模任务的性能只会稍微降低。
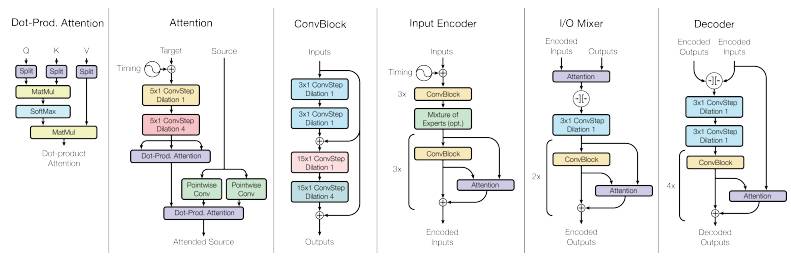
MultiModel 的架构示意图
论文地址:https://arxiv.org/pdf/1706.05137.pdf











