宋梦超
新蜂数字金融

联邦学习,提供了一种破解数据安全和数据孤岛问题的可行性方向:
1、通过引入RSA和hash加密算法保证了多方交互过程中的数据安全;
2、同态加密技术保证了传输过程中加密数据的可计算性;
3、对梯度进行掩码处理保证了真实梯度信息仅对己方可见;
4、并行建模机制保证了模型的无损和可解释性;
5、引入区块链技术以鼓励更多的公司主动加入联邦。
数据安全性升级,数据孤岛亦突显

得益于数据规范化和统一化治理的大力推进,各大银行等金融机构数据分析能力在近几年获得了突飞猛进的提高,数据在传统金融风控、营销等领域的作用渐渐得到广泛认可。
但若以更进一步的B端赋能、C端突围和G端连接为目标,仅依赖机构自身数据进行相关金融创新的方式已渐露疲态。
其本质原因在于数据孤岛使得机构难以对客户进行全方面的描绘,为此各大金融机构已经开始纷纷进行外部数据合作的相关建设。
与此同时,随着人工智能技术的发展和广泛应用,数据隐私保护也开始越来越多地被关注。
2017年实施的《中华人民共和国网络安全法》和《中华人民共和国民法总则》指出网络运营者不得泄露、篡改、毁坏其收集的个人信息,并且与第三方进行数据交易时需确保拟定的合同明确约定拟交易数据的范围和数据保护义务。
2018年5月有着史上最严个人信息保护法规之称的数据隐私保护的法案《通用数据保护条例》(General Data Protection Regulation, GDPR)正式出台,其明确了对数据隐私保护的多项规定。
联合建模虽流行,瓶颈问题已显现

前几年金融机构往往通过将购买的外部数据加载至己方数据库中完成联合建模(下图一),模型构建成功后则采用数据接口的方式对所需外部数据进行调用。
但一方面随着近期数据管控和数据隐私相关法规的不断出台,这种方式已经逐步不被相关法规所认可;另一方面,由于数据和自身业务的捆绑程度日期加深,大型企业直接提供数据的可能性也越来越低。
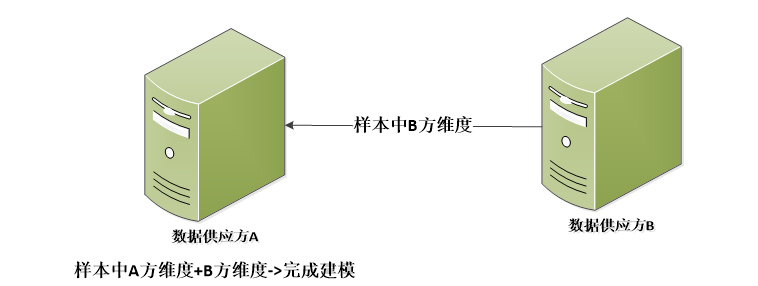
图1:直接融合联合建模
为减少建模过程中交互的客户信息,主-从模型的方式已经成为了当今联合建模的一种主流形式(下图2)。
在此模式中,主模型方(如银行)提供部分客户的身份证/手机号以及好坏客户标志位给从模型方(如政府)以协助其完成从模型的构建,之后从模型方会返回样本输出给主模型方以结合己方多维数据完成最终模型的构建。
由于仅提供了好坏标签信息并且客户ID在匹配过程中会采用md5等hash加密的方式进行匹配,该方式在一定程度提高了对于数据的保护程度,但该方式问题有:
1、从合作范围的角度考虑,主-从模型的作用范围有限
。从模型方需要额外激励才会完成协作,如政府在希望其数据能为地方企业带来银行的额外授信以加速经济发展;小型数据服务厂商希望自己积累的数据能通过融入银行的模型体系以保证其企业生存,而对于大型商业机构之间的合作,该模式动力明显不足。
2、从数据安全的角度考虑,仅采用hash算法进行加密的数据在泄露至外部后,存在被破解的可能性。
这是由于目前几乎所有常用的密码的一次md5、二次md5甚至3次md5的结果都被计算出来存到一个彩虹表里,因此若加密前的数据存在于彩虹表中,其毫无保密性可言。
3、从模型效果的角度考虑,该模型是一个有损模型。
由于从模型的分数是由外部多个指标共同构成,之后在主模型的构建过程中从模型分数是作为一个指标使用的,因此该模型必定是一个有损模型,即效果必定稍差于直接使用银行多维数据+政府多维数据构建的模型。
4、从模型解释性角度考虑,无法解释从模型中不同指标对应的分值。
由于从模型结果作为主模型的一项指标入模,因此在主模型评分卡中,仅可解释从模型不同水平结果对应的分值,而无法解释从模型中不同指标对应的分值。
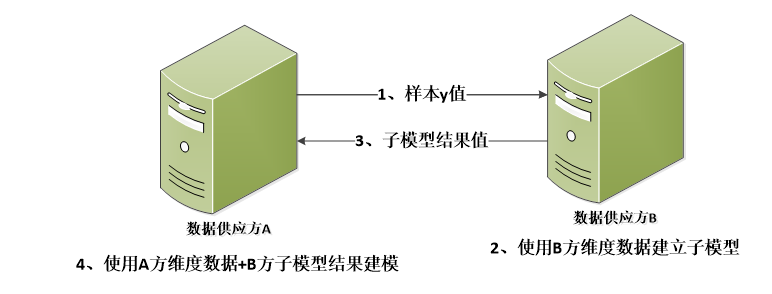
图2:主-从模型联合建模
显然主-从模型的联合建模方式瓶颈已经清晰可见,两个公司之间简单的交换数据在越来越多的法规中已经被明令禁止。
从数据本质的角度来说,用户才是原始数据的拥有者,在用户没有授权的情况下,公司之间是不能交换数据的;另外,数据建模使用的目的在用户认可前也不可以改变。
所以过去的许多数据交换的尝试,例如数据交易所,也需要巨大的改变才能合规。与此同时,数据的巨大价值已经被各大商业公司清晰认知,两个公司甚至公司部门都会在数据交换的过程中变得愈发谨慎。
联邦学习优势多,助力
于
联合建模

为解决此问题,谷歌在2016年提出了联邦学习的概念。
联邦学习的初衷在于解决安卓手机终端用户在本地更新模型的问题,其设计目标是
在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习
。
其中,联邦学习可使用的机器学习算法不局限于神经网络,还包括随机森林等重要算法,
联邦学习有望成为下一代人工智能协同算法和协作网络的基础,其对于金融机构的联合建模方式有着极强的借鉴意义
。
目前针对不同的数据集,联邦学习主要分为横向联邦学习、纵向联邦学习与联邦迁移学习三大类:
1、横向联邦学习
:在两个数据的拥有者中,用户特征有较高重叠,而其客户重叠较少。
此时我们可以取出双方特征相同而用户不完全相同的数据进行训练;这种方式的一种典型应用场景是两家地区银行进行联合建模,因为此时仅基于单一方的数据可能存在客户样本过少的问题。
因此,
横向联邦学习主要解决的是样本不足的问题
。
2、纵向联邦学习
:该模式适用于数据源之间用户重叠较多而特征重叠较少的情况,该情况往往适用于大型机构之家的数据合作,如大型商业银行和地方政府或大型互联网企业。由于双方客群均包含大部分客群,因此用户交集很大。
一方面,银行以交易、资产类数据为主,政府保有交通水电煤等日常生活类数据,互联网企业则更多的涵盖消费、社交、出行类数据,因此两两之间的用户特征交集很小。这在银行还未积累到足够数据维度的新/次新客群中使用该建模方式效果最为显著。
另一方面,对于小企业类用户来讲,银行要想通过对于企业各生命周期的精准描绘进行相关金融产品创新,也需要政府等外部数据源的多维数据进行补充。
对于大中型企业风险从萌芽期-发展期-应急期-暴露期的发展过程中,仅基于银行内部数据构建的风险预警模型可能在应急期才能有相关反应,想要将风险预警的时点提早至发展期乃至萌芽期也需要更多的外部数据作为补充。
因此,
纵向学习主要用于解决维度缺陷导致的模型精度问题
。
3、联邦迁移学习
:在两个数据集的用户与用户特征重叠都较少的情况下,我们不对数据进行切分,而可以
利用迁移学习来克服数据或标签不足的情况
。这种方法叫做联邦迁移学习。
比如有两个不同机构,一家是位于中国的银行,另一家是位于美国的电商。由于受到 地域限制,这两家机构的用户群体交集很小。同时,由于机构类型的不同,二者的数据特征也只有小部分重合。
在这种情况下,要想进行有效的联邦学习,就必须引入迁移学习来解决单边数据规模小和标签样本少的问题,从而提升模型的效果。
知其然与所以然,以知其利器所在

在讨论了联邦学习的定义与分类之后,我们以纵向联邦学习为例深入介绍一下联邦学习系统的构架,从而理解其工作的流程与细节。
联邦学习与当前主流的主-从模型的建模方式区别主要在于:
(1)将主-从建模方式替换为并行建模方式,以解决模型有损和模型解释性不足问题。
(2)引入RSA和hash加密算法保证多方交互过程中的数据安全问题;
(3)引入同态加密技术以保证传输过程中加密数据的可计算性;
(4)对梯度结果进行掩码处理以保证了真实梯度信息仅对己方可见;
(5)引入区块链技术以激励更多的企业加入联邦以提升总体的模型效果。
首先,我们研究第一个问题,如何在不把数据源的数据加载至同一个数据库的方式下完成并行建模?笔者将基于简单的多元线性回归模型来展示。
首先定义模型表达式:

接下来我们使用最小二乘并加入岭回归(L2正则)作为最终的损失函数:

我们使用梯度下降法进行迭代求解,为此求得:
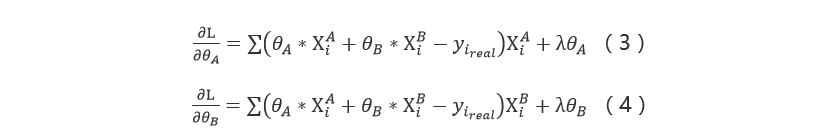
参数更新:
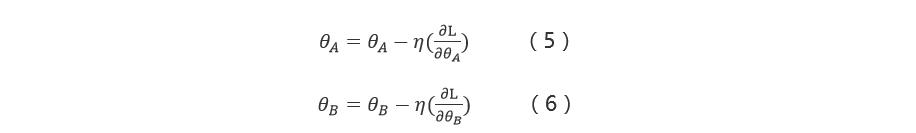

并行联合建模方式如下图3所示:
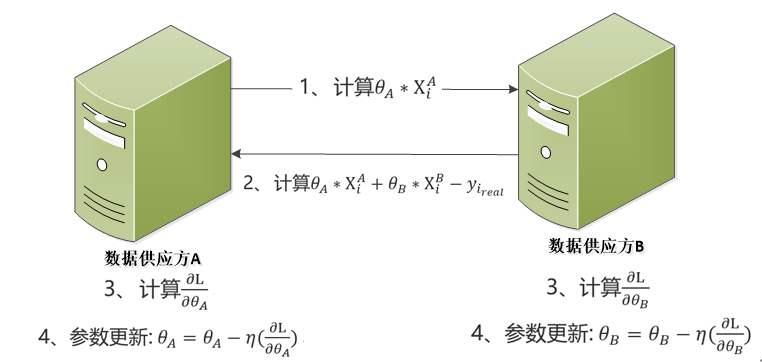
图3:并行联合建模
在以上联合建模方式的基础上,联邦学习通过引入RSA加密算法分别保证了A、B交互数据部分的互相保密,同态加密技术则可以保证加密数据的可计算性。
另一方面,联邦学习使用RSA+hash的加密碰撞机制替换了传统的hash加密后直接进行的样本交集确认过程,这种方式提升了数据的安全性。
最后,联邦学习会引入区块链技术将A、B以及更多方在模型优化过程中的贡献以及在未来模型使用中的贡献量化出来,从而激励更多的数据拥有方主动加入联邦。
我们引入C方,且使用【】代表对于数据进行C的公钥加密;基于同态加密技术,并记

基于上述分析,具体建模流程如下图4所示:
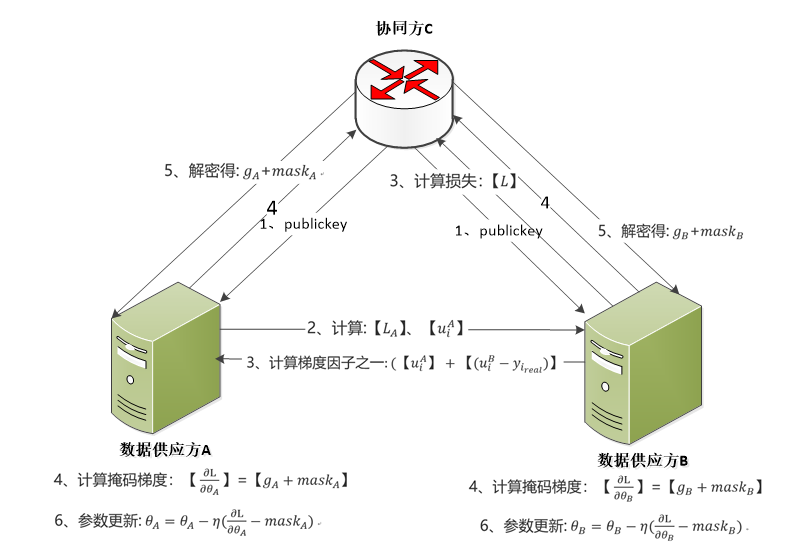
图4:
联邦学习建模
上述模型中由于使用了C的公钥【】,A和B仅可在每一步骤中学习梯度中含己方变量的信息,无法获得任何对方的任何有效信息。另一方面,由于A、B在将梯度使用公钥加密传输给C前进行了掩码操作,C解密后获得的也仅仅是A、B的掩码梯度,因此C并不知道A、B的真实梯度信息。
联邦学习的模式确保了每个A、B方仅掌握了自己方相关的模型信息,之后即可采用如下图5方式完成模型的调用:
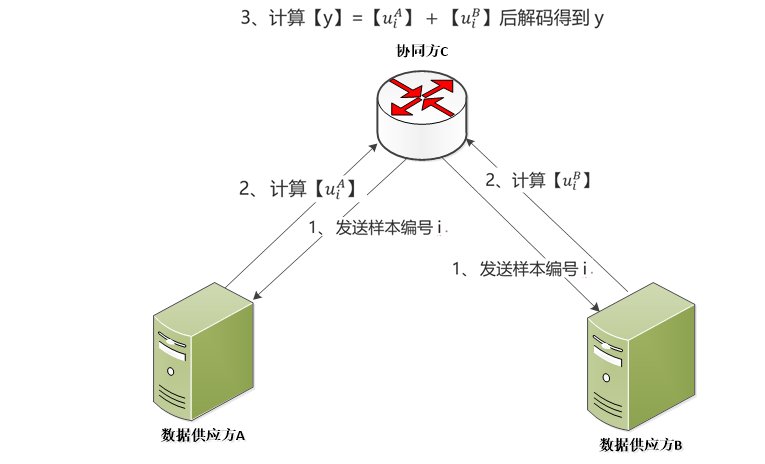
图5 :联邦学习模型调用









