大家好,我是思聪 · 格里尔斯,我将向您展示如何从世界上某些竞争最激烈的比赛中拿到金牌。我将面临一个月的比赛挑战,在这些比赛中缺乏正确的求生技巧,你甚至拿不到铜牌。这次,我来到了亚马逊热带雨林。
当我和我的队友们进入这片雨林的时候,这场长达三个月的比赛已经进行了两个月,想要弯道超车,后来居上,那可不是件容易的事。
我们最后在比赛结束的时候,获得了 Public Leaderboard 第一, Private Leaderboard 第六的成绩,斩获一块金牌。
这个过程中,我们设计并使用了一套简洁有效的流程,还探索出了一些略显奇怪的技巧。
使用这套流程,我们从 Public Leaderboard 一百多名起步,一路杀进金牌区,一直到比赛结束前,占据 Public Leaderboard 榜首数天,都没有遇到明显的阻力。在这篇文章里,我不仅会介绍这个流程本身,还会把我们产生这套流程的思路也分享出来,让大家看完之后,下次面对一个新问题,也知道该如何下手。
在文章的结尾,我还会讲一讲我们比赛最后一夜的疯狂与刺激,结果公布时的懵逼,冷静之后的分析,以及最后屈服于伟大的随机性的故事。
1. 初探雨林:概述(Overview)与数据(Data)

探险的第一步是要弄清楚问题的定义和数据的形式,这部分看起来会比较繁琐,但是如果想要走得远,避免落入陷阱,这一步还是比较值得花功夫的,所以请大家耐心地看一下。如果是已经参加过这个比赛的读者,可以直接跳过这个部分。
我们先看一下这个比赛的标题:
• Planet: Understanding the Amazon from Space
• Use satellite data to track the human footprint in the Amazon rainforest
翻译一下就是:
• Planet(举办比赛的组织名):从太空中理解亚马逊
• 使用卫星数据来跟踪人类在亚马逊雨林中的足迹
看来这是一个关于亚马逊雨林的卫星图像比赛,为了进一步了解问题,我们需要阅读的是比赛的 Overview 和 Data 两个部分。
1.1 描述(Description)
Overview 的 Description(描述)部分告诉了我们主办方的意图,原来是为了从卫星图片监控亚马逊雨林的各种变化,以便当地政府和组织可以更好保护亚马逊雨林。看我发现了什么,这个 Overview 的尾部附带有一个官方提供的 ipython notebook 代码的链接:
https://www.kaggle.com/robinkraft/getting-started-with-the-data-now-with-docs
这个 ipython notebook 有不少信息量,包含对数据的读取,探索,相关性分析,可以大致让我们对数据有一个基本的感觉,并且可以下载下来进一步分析,可以省上不少功夫。如果官方没有提供这样一个 notebook, Kernel 区一般也会有人发出自己的一些分析,实在没有最好也自己做一下这个步骤,因为这个可以为后面的一些决策提供信息。
1.2 数据(Data)
然后我们可以先跳过 Overview 的其他部分,去看一下 Data 部分。Data 部分一般提供数据的下载和说明,先把数据点着下载,然后仔细阅读说明。其中训练集大概有四万张图像,测试集大概有六万张图像。数据说明包括了数据的构成和标签的来源。我们可以先看一下这张图:
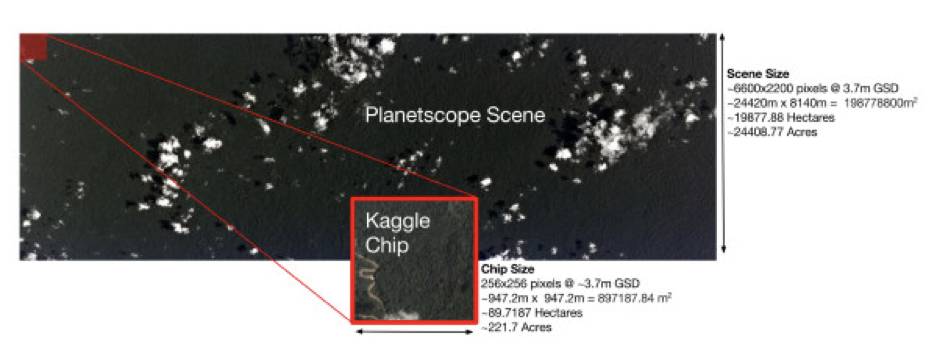
这次比赛中的每个图像样本都是 256*256 像素,并且每个像素宽约对应地面的宽度大约是 3.7m。然后每个样本都有 jpg 和 tif 两种格式,tif 好像是比正常的 RGB通道多了一个红外线通道,嗯,可能会有用。
数据的标签有 17 个类,其中 4 个天气类,7 个常见普通类,以及 6 个少见普通类。
天气类包括:Clear,Partly Couldy,Couldy,Haze。其中只要有 Couldy的就不会有其他类别(因为被云覆盖住了什么都看不到)。
常见普通类包括:Primary Rain Forest,Water (Rivers & Lakes),Habitation,Agriculture,Road,Cultivation,Bare Ground。
少见普通类包括:Slash and Burn,Selective Logging,Blooming,Conventional Mining,"Artisinal" Mining,Blow Down。
普通类描述的是丛林中出现的各种景观,包括河流、道路、耕种用地、采矿基地等等。下面是一些样本的示例图,图中用红色字体打上了类别信息:

官方还附带了这些类别的说明和相关新闻报道,其中类别的说明最好读一下,有助于对任务的理解。我们在最开始对每个类的含义和特性进行了分析,然而最后探索出来的方案并没有对不同类别进行针对性的处理。虽说如此,下次遇到一个新问题我们仍然会尝试进行分析。
理论上每幅图都拥有一个天气类外加若干个普通类,所以这是一个
Multi-Label (多标签)
的问题。其中少见普通类比较少,大概四万个样本中有的类甚至不到一百个。在最后的 Submission 中,我们要提交一个包含大概六万个样本的标签的 csv 文件,其中大约四万个用于 Public Leaderboard 的分数计算,两万个用于 Private Leaderboard 的分数计算。
官方还提到数据是众包平台上标注的,所以会包含一些错误的标签,因为其中一些图像他们组织里的专家都分不清楚,更不要说众包标注的工人了,所以我们要意识到这是一个富含噪声的数据集。最后的比赛结果也证实了这一点,因为前63名的分数都在 93.0% 到 93.3% 之间,甚至都突破不了 94%。这里的分数是指什么呢?请看下一小节。
1.3 评价指标(Evaluation)
弄清了问题的形式,接下来我们可以返回阅读 Overview 的剩下部分。Evaluation 告诉我们这次的评价指标是各个样本 F2-score 的均值,F2-score 的定义如下:
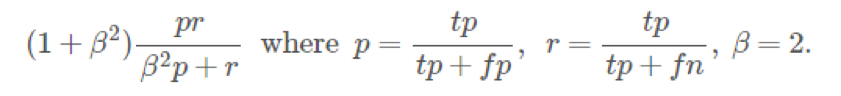
p 是精度(precision),表示我们预测出来的类出现在标签中的比例;r 是召回率(recall),表示标签中出现的类被我们预测出来的比例。F2-score 相对偏好召回率,所以在比较不确定的时候,预测多一点可能会比预测准一点来得好。
1.4 奖金(Prize)与比赛时间线(Timeline)
这次比赛的奖金第一名有 3 万美刀,第二名 2 万美刀,第三名 1 万美刀。虽然没有类似 Zillow 那个一百多万美刀那么惊人,但也是一笔不少的外快了。
比赛开始于 4 月 20 日,7 月 13 号则是参加截止日期以及合队截止日期。一般来说,即便你是和几个小伙伴一起参赛,也不要急着太早合队,因为每个队伍每天只有固定的提交次数可用,不合队的话所有人加起来可以获得数倍的提交机会,这对于初期的方案探索是非常有益的。
另外,7 月 13 日也同时是预训练模型声明截止的时间,因为图像类比赛经常会使用 ImageNet 上预训练过的模型,为了公平起见,所有人都只能使用讨论区一个置顶帖中声明过的预训练模型,如果选手所使用的预训练模型没在里面,那就要在截止时间前自觉去帖子里添加声明,否则视为作弊。
比赛最后于 UTC 时间 7 月 20 号晚上 11 点 59 分结束,对于身在国内的我们来说,这意味着最后一天要通宵陪欧洲人民冲刺到早上八点。
2. 痕迹与工具:讨论区(Discussion)和 Kernel 区
一个老练的探险队员要善于利用前人留下的信息。我们队里常说,一个能善于使用讨论区、工程能力不差并且有时间精力的人,应该有很大可能性拿到一个银牌。讨论区里包含着官方的一些申明通知,还有其他队伍的一些经验分享,Kernel 区包含了一些公开发布的代码。这些都是所有参赛队伍共享的信息,对于一个新手和后进场的队伍,从这里面获取足够信息可以取得比较好的开端。
此外,常被忽略的一个点是,其他一些已经结束的类似比赛中,也包含了大量对这个比赛有用的信息。比如这个比赛是卫星图像的多标签分类比赛,那么其他卫星图像比赛or图像or多标签分类比赛的信息都会对这个比赛有用,这些比赛的讨论区经常包含了大量优秀的解决方案,这对我们后面设计方案会有帮助。
最后要小心的是,讨论区里面的发言也不一定对,Kernel 区的代码可能也有些 bug,比如这次比赛有一些队伍因为使用了一个有 bug 的 submission 生成代码,最后都掉了八九百名,场面十分血腥。
我们从参赛的时候从讨论区获取的一些有用信息如下:
1. tif 图像数据在 RGB 通道之外包含红外通道,按理来说多使用上这个信息应该会提高效果,然而恰恰相反,讨论区的人说用了之后反而变差了,这可能是因为有些图片的红外通道跟 RGB 通道是错开的。所以到比赛结束我们也只是稍微尝试了一下去利用 tif 的红外通道,并没有在上面浪费太多时间。
2. 其他队伍有可能使用了哪些预训练模型,每个模型的大体性能如何,这给我们提供了很有用的参考,比如我们在尝试了一些比较小规模的模型(如 ResNet18、ResNet34)之后,以为这些模型已经够了,再大再复杂的模型可能会过拟合,但是从讨论区我们看到,大模型还是有明显优势的,这就促使我们敢于花大量时间去跑那些笨重的 ResNet152、DenseNet161 等预训练模型。
3. 从其他类似比赛的讨论区我们看到,高分队伍一般不会使用特别复杂的 Ensemble 方法,甚至会仅仅使用简单的 bagging 和 stacking(下面会讲),所以我们就把更多的精力花在单模型的调优。事实证明,即便到了比赛后期,还不断有一些更好的单模型新鲜出炉,使我们 Ensemble 后的效果猛地一窜,窜到了 Public Learderboard 前三乃至第一。
3. 探险开始:解决方案的规划和选择
以上准备可能会花上你一到两天的时间,但磨刀不误砍柴工,我们也差不多可以开始我们的征程了。
3.1 BCE Loss 训练 和 F2-Score 阈值调优
上面提到,这次比赛问题是 Multi-Label(多标签)分类问题,评价指标是 F2 Score,但 F2 Score 并不是可以直接优化的值,所以我们采取的方法是:
1. 每个输出接 Sigmoid 层,分别预测每个类的概率,使用 Binary Cross Entropy Loss 优化。这其实是多标签分类问题的常见套路,本质是独立地对每个类做二分类学习。虽说不同类之间可能存在相互依赖,但我们假设这些依赖可以通过共享底层参数来间接实现。
2. 在训练上述二分类任务时,由于正负样本数目不均衡,我们并不能直接拿 p = 0.5 作为二分类的阈值进行预测,而需要为每个类搜索一个合适的阈值,使得整体的 F2-Score 最大。具体来说,我们采取了讨论区放出的一个方案,贪婪地对每个类的阈值进行暴力搜索,逻辑如下:
# 假装是 Python 的伪代码
给定 17 个类的阈值构成的阈值向量,每个元素初始化为 0.2
for 第 i=0 到第 i=16 的类:
固定其他类的阈值不动
在第i个类上分别尝试 0.01, 0.02, 0.03, ... 0.99 总共 100 个候选
每个候选构成一个新的阈值向量,新的阈值向量可以在样本集上获得一个 F2
找到 100 个 F2 中最高的,取其对应的候选阈值,就作为第i个类的阈值
这样就把第 i 个位置的 0.2 改成了一个新的值,接着贪婪地处理下一个类
这肯定不是最优的方案,但却已经足够好。虽然后期我们优化了讨论区的代码使用 GPU 加速计算,并尝试了诸如随机初始值、随机优化顺序然后多次随机取最好,步长大小调优,进化计算搜索等方法,但都因为提交次数限制没来得及测试。
不过要注意的是,虽然我们以 BCE Loss 为训练目标,但实际上 BCE Loss 变低,F2-Score 却未必变高,可以想象一下,如果模型把一些本来就能被分对的样本的预测概率变得更搞,BCE Loss 是会降低,但 F2-Score 还是一样。
为什么要强调这点呢?因为有队友在探索 Ensemble 方法的时候,看着 BCE Loss 不好就放弃了;再往后另一个队友重新实现了一样的 Ensemble 方法,看的是 F2-Score,却发现效果拔群!所以说,如果只看 Loss,不看最终评价指标,很容易做出误判,错过有用的方案,这对于其他问题来说也是成立的。
另外讨论区也有人提到一种直接对 F2 Score 进行优化的方法,我们因为时间有限还没来得及进行尝试。
3.2 划分训练集和验证集
一开始将官方的训练数据(Train Data)划分训练集(Train Set)和验证集(Validation Set),或者均匀划分成 K 个部分,用于做 K 折交叉验证(K-Fold Cross Validation)。关键的是,随机划分结果要队伍内和方案间共享。不然的话,这个模型训练用的 K 折划分和那个模型训练用的K折划分不同,还怎么严格比较它们之间的优劣呢?而且这也是为后面数据分析和模型的 Ensemble(集成)做准备。
这一次我们将数据平均划分了五折(编号 0-4),使用一折作为验证集,使用其他四个折作为训练集,可以有五种组合。然后探索初期方案期间,只使用其中一种组合,例如将第 0 折作为验证集,1-4 折作为训练集。
在模型确定后,如果想用上全部数据作为训练,我们可以使用五种组合,每种组合用四折训练一个模型(对应下图中 4 个灰色大块),在剩下的一个折作为验证集预测(对应下图中 5 个蓝色小块),遍历五种组合后我们可以获得每一个折的验证集预测结果(还是对应下图中 5 个蓝色小块),因为
这些验证结果都是从没有在它们上面训练过的模型预测出来的
,我们把这个五个验证折拼在一起的结果称为 out-of-fold,包含整个训练集的验证结果(对应下图中的蓝色长块)。在 out-of-fold 上面进行阈值调优得到的 F2-Score 可以较好的代表模型的能力,可以真实地反映模型的泛化性能,多个模型的 out-of-fold 拼接在一起也可以作为第二阶段的集成学习的输入。
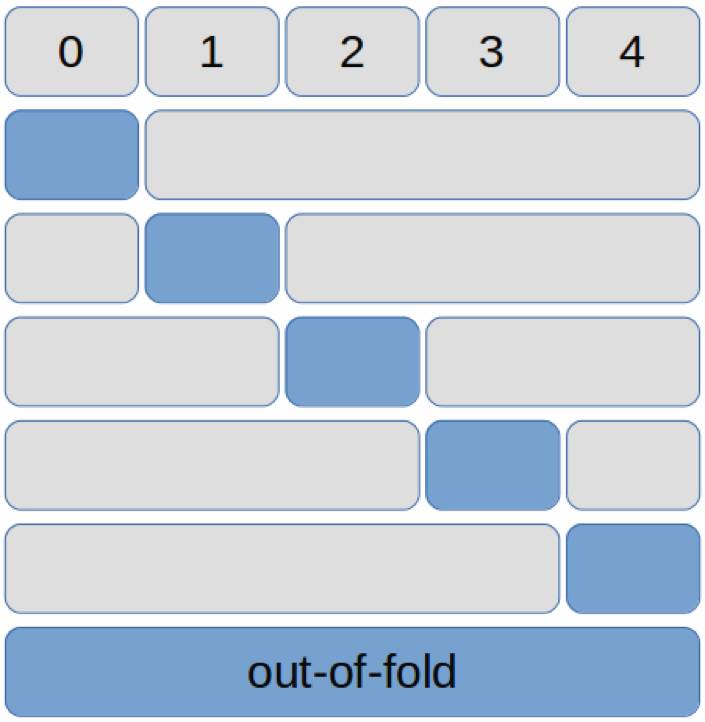
在上面的 5 种组合上做了 5 次训练,测试的时候我们就有了 5 个模型,每个模型预测一遍测试集就得到了 5 个概率矩阵,每个概率矩阵的形状都是(测试集样本数 x 17)。我们可以将 5 个概率矩阵直接求平均后做二分类预测,也可以分别做完二分类预测,再做投票,来获得最终的多类预测结果。这个结果实际上用到了所有 5 个折的训练数据,会更加准确,也更加稳定。
当然如果只是想用上所有数据的话,更简单的办法就是直接把整个训练集用这个模型跑一遍,再把训练好的模型模型对测试集作预测。不过我们没有采用这第二种方式,一来,所有训练样本都被这模型“看光了”,没有额外的验证集,难以评估其泛化性能;二来,我们认为第一种方法中,5 个模型的预测结果做了个简单的 Ensemble,会更稳定一点。
折数划得越多,训练验证所需要的计算力和时间也就越多,最好根据问题和自身计算力做一个权衡。
3.3 深度学习还是传统方法
通过调查我们可以发现,Kaggle 图像比赛现在基本被深度学习方法所统治。虽然在一些细节上传统方法还有发挥空间,但还是以 CNN(卷积神经网络)为主体。
3.4 框架选择与Model Zoo
虽然之前我主用 TensorFlow,不过 PyTorch 提供的 Model Zoo 使用起来很方便,代码比较轻量级,队内会用的人数也比较多,所以这次比赛我们最终采用了 PyTorch 作为主体框架——除了队内某个异端,他用 TensorFlow 为自己写了一个高效的 DataLoader。
PyTorch 的 Model Zoo 提供了 AlexNet,VGG, Inception v3, SqueezeNet, ResNet, DenseNet 等架构的预训练模型参数。我们还嫌这些模型不够用,就尝试了从 TensorFlow 上迁移过来的的 Inception v4 和 Inception Res v2(Tensorflow-Model-Zoo.torch | GitHub) 。可惜的是,大概由于这两个模型走的不是“正规渠道”,是“偷渡”过来的,大概哪里出了偏差,总之训练结果一塌涂地,果断放弃。在这里我们呼吁大家支持正版。
PyTorch 文档提供了不同模型在 ImageNet 上 Top-1、Top-5 的错误率,可以大概看出这些模型的能力,虽然这不一定和它们在比赛中的表现性能正相关。
在我们这次比赛中,ResNet 表现最好,DenseNet 紧随其后,这不是偶然的。它们有一个引人注目的共同点,就是从底层到高层有 Skip-Connection,其中 ResNet 采用的是两路叠加,Densenet 是多路拼接。为什么重要呢?我们认为,第一是因为 Skip-Connection 可以自适应调节模型复杂度,避免过拟合,第二是因为 17 个类所利用的图像特征层次不同,比如 Cloudy 更偏向底层纹理特征,Water 和 Road 更偏向高层语义,而 Skip-Connection 有助于让底层特征到很高层仍然保留,而不会淹没在几十层网络的变换中。
稍弱一点是 VGG 和 Inception v3,最弱的是 SqueezeNet 和 AlexNet。从 TensorFlow 上迁移过来 Inception v4 和 Inception Res v2 基本上不收敛,再次呼吁大家支持正版。
3.5 预训练或随机初始化
我们一开始在 ResNet-18 这个轻量级的模型分别尝试预训练参数(Pretrained)和随机初始化参数(From Scratch)进行训练,结果发现,随机初始化的模型的收敛速度比预训练的模型要慢上十倍左右,最终收敛结果也差上一截。有队友还试着自己设计一些网络架构,但结果也远远比不上预训练模型。
所以做完这波实验后,我们也大概确定这次的比赛,跑 Model Zoo 将是主要的手段。听起来并不像自己设计网络结构那么激动人心,但我们也可以在上面做些一些魔改,魔改之后也取得了意料之外的提升,具体见下一节。
3.6 预训练模型使用与改动
使用预训练模型的时候要注意,PyTorch 文档中说明了这些模型都是在 224x224 的图像上进行预训练,而且要求图片要经过归一化并减掉某个均值、除以某个方差,然后才输入模型。如果想要模型能最大程度的利用预训练的信息,一定要对我们输入图片也做同样的操作。
不过虽然模型的输入要求是 224x224,但一部分模型(比如 ResNet,DenseNet)的卷积层结束时会接一个 Global Average Pooling,将每个通道的 Feature Map 求平均,这样不管输入的图片尺寸多大,经过 Global Average Pooling 之后 Feature Map 的尺寸都会变成 1x1,所以理论上是可以直接使用的。
然而这里有一个坑点是,PyTorch 预训练模型卷积层最后其实使用是一个 7x7 固定大小的 Average Pooling,并不是真正的 Global AveragePooling。要想输入其他尺寸大小的图,我们应该把该层替换成 AdaptiveAvgPool,并将输出设置大小为 1,这样就能保证无论上一层 Feature Map 尺寸是多少,出来的尺寸都会是 1x1。
当然,有可能一下子缩到 1x1 太小了,损失了太多信息,所以我们也可以把 AdaptiveAvgPool 输出大小设置为 2 或 3,使得输出尺寸变成 2x2 和 3x3,这样的好处是保留下更多的信息。为了与之匹配,还需要改动后面整个全连接层的尺寸。我们后来在 Densenet 和 ResNet 上尝试这个改动,取得了不错的效果。
以上是针对 ResNet 和 DenseNet 来说的,而像 VGG 这种模型,最后 Feature Map 是直接 Flatten(拉直)然后接全连接,我们如果要利用到后面的预训练全连接层信息,我们就只能将输入图片缩放成 224x224 了。
除了更改 Pooling 输出尺寸,另一个尝试成功的魔改是关于全连接层的。ImageNet 模型最后一层是 1000 类,而我们需要的是 17 类输出,以往常见的做法是把最后一层全连接层换掉,换成一个 output size 为 17 的新全连接层,然后重新初始化它的参数。
然而,我们的两个队友却因为偷懒发现了效果更好的做法,就是直接在预训练模型的 1000 维输出后面,直接就接上一个 1000x17 的全连接层。我们猜测,它效果好的原因是额外地保留下了全连接层的预训练信息。
另外有些队友担心,这个比赛的大多数图片都可能被预训练模型识别为草地之类的 ImageNet 类别,所以可能基本上都只激活 1000 维中的少数几个,会很稀疏,这样其实应该是对训练不利的。针对这种疑虑,我们将很多比赛图片输入预训练模型后,发现它们在 1000 类上预测的概率值并不稀疏,所以应该没太大问题。不过,这种新做法也可能只对这次比赛任务有效,在其他任务上还是建议先试着把最后一层全连接换掉或是整个随机初始化,因为一般来说最后一层的可迁移性更差一点。
至于具体要怎么在全连接层中加 Batchnorm、Dropout 就看个人选择了,我们在发现这个任务上没有太显著影响,后面大部分模型都没有加。
我们在探索 Data 部分的时候可以得知,四个天气类会且只会出现一个,这很容易让我们想到将这四个类单独拿去来接一个 Softmax 层而不是 Sigmoid 层,使四个类概率和为 1,预测的时候只预测最大概率的天气类。但这样做实际效果并不好,因为我们上面提到过这次比赛的评价指标是 F2-Score,更希望有比较高的召回率而不是准确率,如果最高两个天气类非常接近,那把它们一起预测为正,虽然有一个肯定会猜错,但却可能可以取得更高的 F2-Score,总体上反而是划算的。
3.7 学习率与Batch Size
关于模型的训练,我们使用的是 Adam 作为优化器,因为它对学习率有一定程度的自适应微调,收敛速度快,而且对一些小类的更新也比较友好。我们尝试了 1e-2, 1e-3, 1e-4, 1e-5, 几个范围后,大致确定了 1e-4 是一个比较好的初始学习率,后面我们对不同的模型调整初始学习率都是对这个值乘以 2、4 倍或除以 2、4 倍,主要是随着 Batch Size 等比例变化。
我们的 Batch Size 大概是在 32 到 128 之间,取决于 GPU 是否能装得下多大。有时候我们也会将一些调低 Batch Size 到 32 做一下实验。
3.8 数据增强(Data Augmentation)
图像比赛的一个重头戏就是数据增强,我们为什么要做数据增强呢? 我们的训练模型是为了拟合原样本的分布,但如果训练集的样本数和多样性不能很好地代表实际分布,那就容易发生过拟合训练集的现象。数据增强使用人类先验,尽量在原样本分布中增加新的样本点,是缓解过拟合的一个重要方法。
需要小心的是,数据增强的样本点最好不要将原分布的变化范围扩大,比如训练集以及测试集的光照分布十分均匀,就不要做光照变化的数据增强,因为这样只会增加拟合新训练集的难度,对测试集的泛化性能提升却比较小。另外,新增加的样本点最好和原样本点有较大不同,不能随便换掉几个像素就说是一个新的样本,这种变化对大部分模型来说基本是可以忽略的。
一些常见的图像数据增强方式有:
• 亮度,饱和度,对比度的随机变化
• 随机裁剪(Random Crop)
• 随机缩放(Random Resize)
• 水平/垂直翻转(Horizontal/Vertiacal Filp)
• 旋转(Rotation)
• 加模糊(Blurring)
• 加高斯噪声(Gaussian Noise)
对于这个卫星图像识别的任务来说,最好的数据增强方法是什么呢?显然是旋转和翻转。具体来说,我们对这个数据集一张图片先进行水平翻转得到两种表示,再配合 0 度,90 度,180 度,270 度的旋转,可以获得一张图的八种表示。以人类的先验来看,新的图片与原来的图片是属于同一个分布的,标签也不应该发生任何变化,而对于一个卷积神经网络来说,它又是 8 张不同的图片。比如下图就是某张图片的八个方向,光看这些我们都没办法判断哪张图是原图,但显然它们拥有相同的标签。

其他的数据增强方法就没那么好用了,我们挑几个分析:
• 亮度,饱和度,对比度随机变化:在这个比赛的数据集中,官方已经对图片进行了比较好的预处理,亮度、饱和度、对比度的波动都比较小,所以在这些属性上进行数据增强没有什么好处。
• 随机缩放:还记得我们在 Overview 和 Data 部分看到的信息吗?这些图片中的一个像素宽大概对应 3.7 米,也不应该有太大的波动,所以随机缩放不会有立竿见影的增强效果。
• 随机裁剪:我们观察到有些图片因为边上出现了一小片云朵,被标注了 partly cloudy,如果随机裁剪有可能把这块云朵裁掉,但是 label 却仍然有 partly cloudy,这显然是在引入错误的标注样本,有百害而无一利。同样的例子也出现在别的类别上,说明随机裁剪的方法并不适合这个任务。
一旦做了这些操作,新的图片会扩大原样本的分布,所以这些数据增强也就没有翻转、旋转那么优先。在最后的方案中,我们只用了旋转和翻转。并不是说其他数据增强完全没效果,只是相比旋转和翻转,它们带来的好处没那么直接。
3.9 增强数据集与训练迭代数
按照一般的做法,数据增强的流程是一个 Epoch 一个 Epoch 地训练整个训练集,每次对输入的样本进行随机的数据增强,这也是本次比赛大多数队伍的做法。
但是我们却采取了不同的做法,显著缩小了训练一个模型需要的时间,提高了我们在初期的方案迭代速度。首先,我们注意以下两个点:
1. 采用的旋转和 90 度倍数的翻转,很容易可以遍历完所有八个情况,所以样本量刚好就是扩充八倍;反之,像光照,饱和度,对比度这些状态连续的数据增强,很难提前预计样本量扩充多少倍才合理,所以必须在训练过程中不断地随机增强。
2. 模型如果第二次、第三次见到某个已经学得很好样本,有可能会过拟合到该样本,使验证集 Loss 反增。
所以我们预先生成了八种方向的样本,把训练集扩充了八倍,再随机打乱,再这些样本都只训练一遍就停止,相当于只跑了一个 Epoch(当然这里的一个 Epoch 的时间等于原来八个 Epoch)。这样做之后就保证每个样本的 8 种方向都只被模型看过一遍,不给模型过拟合的机会,而且这样在时间上也节省了许多。如果是按正常的随机增强做法,可能你要等到很久之后才能把 8 个方向都随机到,而在此之前又会让模型多次见到同一样本的同一方向,既浪费了时间,又增加了过拟合的风险。
在扩充的增强训练集上使用 Adam 优化器进行训练,我们观察到模型在过完整个增强训练集就收敛到一个接近最优的水平,然后继续训练下去验证集就会开始收敛或反增,这也支持了我们“只扫一遍”的想法大致是正确的。不过,有队友还是不满足于只扫一遍,于是就有了下面的改进。
3.10 猛降50倍学习率,再过一遍训练集
在 Loss 收敛的时候降低学习率继续训练,是深度学习一种常见的 Trick。像我们上面那样只将训练集过一遍,会导致一些样本只在前期模型还很不稳定的时候被见过,并没有很好地被学习。所以我们也想到用降低学习率的方式,将训练集再过一遍。一开始我们尝试了常见的做法,即降低 10 倍学习率,但发现还是会很快过拟合,所以就放弃了。直到后来我们队里有人试着将学习率降低 50、100 倍,可以让模型在过第二遍训练集的时候,既有第二次机会见到以前没学好的样本,又不会因为在已经学得很好的样本上过度训练而导致过拟合,将效果又提升了一截。
后面一直到比赛结束,我们都使用了这套做法,即用初始学习率将训练集过一遍,再降低 50 倍学习率训练第二遍,总的训练时间相当于原来的 2 x 8 = 16 个 Epoch,相比之下,讨论区里面我们看到其他队伍采取传统的数据增强方法,需要跑上二三十个 Epoch。所以这套方法极大地节省了我们模型迭代和方案验证的时间。
所以有的时候不是方法不行,只是你还不够用力。
3.11 测试时数据增强(TTA / Test Time Augmentation)
上面我们提到训练时怎么使用数据增强,但是测试时数据增强(TTA)也可以对预测效果进行很大的提升。具体做法也比较简单,我们可以将一个样本的八个方向都进行预测,获得八个预测概率,接着可以将八个概率直接平均,也可以使用预测的类标签投票来获得最后结果。通过几轮测试,我们采取的是平均的方案,因为效果更好。
3.12 测试数据集的F2 Score阈值搜索
我们测试集的 F2 阈值是在 out-of-fold 的验证预测结果上搜索选取的。对于验证集我们也对每个样本预测八个方向的结果,然后把它们拼接成一个 32 万样本的验证集。我们观察到,在这个集合上搜索得到的阈值,比把八个方向预测结果平均得到 4 万样本的验证集上搜索得到的阈值有更好的泛化性能。
整体上我们观察到的现象就是,搜索阈值时使用的样本数越大,这个阈值的泛化性能很可能也就越好,对于小样本来说,这个阈值很容易过拟合。想象只有一个样本的时候,我们很容易可以找个一组阈值让 F2 Score 为 1.0。 有另一种调整阈值的方式是使得让在 out-of-fold 验证集上预测出来各个类的个数和它们的标签中个数一样。我们没有尝试这种做法,因为我们预测出来的各个类占比和标签中的占比本来就十分接近。
3.13 结果的存储、记录和分析
到这里,我大致已经介绍完我们训练一个单模型流程,在开始介绍Ensemble(模型集成)前,我还是要介绍和强调一下结果的存储、记录和分析的重要性。
结果的存储、记录和分析是新手很容易忽略的一个环节,一开始如果没注意好,到后面模型多起来的时候就容易手忙脚乱。
以下是我们这次比赛记录的数值:
• 模型超参:预训练模型类型,模型改动,输入图片大小,数据增强类型,Batch Size,学习率,迭代次数等;
• 评价结果:K 折交叉验证各个折的 Loss,各个折的均值、方差,整个 out-of-fold 的 Loss 和 F2-score,做完 TTA 的 F2-score,Public Leaderboard 的 F2-score 等。
我们希望,单模型本地 out-of-fold 的验证集上的 F2-Score,能够较好地反映 Public Leaderboarrd 的 F2-Score,这样我们无需耗费宝贵的提交机会就能对新方案的效果进行大致评估。事实上这两个 F2-Score 确实足够相关,如下面的散点图所示,虽然存在一些抖动,但整体上还是呈现一种正相关的关系。不过这里 out-of-fold 是由五折各种的验证集拼接在一起,八方向预测结果平均搜索阈值得到的 F2-Score,后期我们发现八方向预测结果拼接的搜索得到的验证 F2-Score 其实更加稳定,在 Public Leaderboard 的表现也更好。
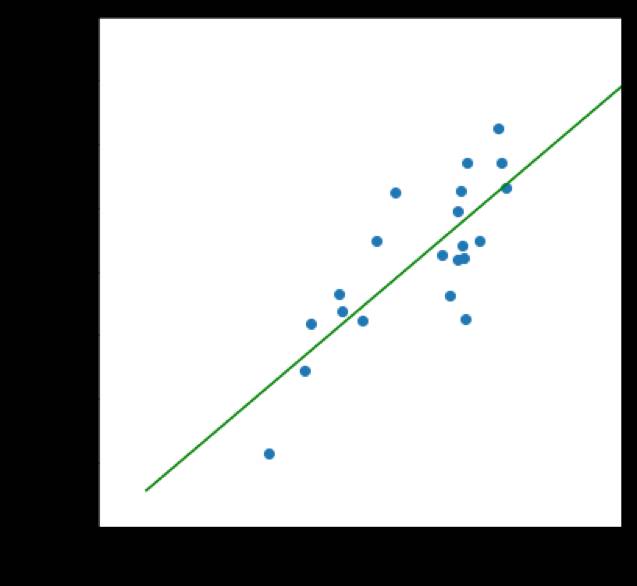
最后,我们发现验证和测试结果以及 submission 的格式的定义和文件名的管理也要注意,这一点我们队伍内一开始没有统一标准,比赛后期的合并结果和赛后的统计分析也花了一番功夫。
3.14 Ensemble:Average Bagging,Bagging Ensemble selection,Attention Stacking
我们这次比赛,使用了三种 Ensemble,关于 Ensemble 的基本套路可以参考《分分钟带你杀入 Kaggle Top 1%》中模型集成(Ensemble)部分:
1. 一开始模型比较少的时候,我们直接把不同模型的结果进行平均(Average Bagging)。
2. 到后面模型比较多的时候,我们开始使用 Bagging Ensemble Selection。
3. 最后我们使用了 Stacking,我们这次用来做的 Stacking 算法除了 Logistic Regression、Rrige Regression,我们还试着自己设计了一种我们自己称之为 Attention Stacking 的算法。
在做 Ensemble 阶段,对于每个样本我们有一个(模型数 x 17)大小的概率矩阵,我们的目标是获得一个长度 17 的概率向量。
对于三种 Ensemble,我们对它们的建模分别为:
1. Average Bagging:所有模型有相同的权重,将概率矩阵沿模型数维度进行平均。
2. Bagging Ensemble Selection:每个模型有不同的权重,在 Selection 的过程中,有的模型可能被选到多次,有的模型也可能一次也没被选到,按照被选中次数为权重,概率矩阵沿模型维度进行加权平均。
3. Stacking:每个模型的每个类都有自己的权重,比如某个模型擅长对气象类进行区分,却对正常类性能很差,那显然这个模型在气象类和正常类的权重应该不一样。
我们需要对每个类别单独学习一组函数或一组权重。
Logistic Regression、Rigde Regression 是对输入模型进行非线性的组合,为了探索其他可能性,我们也试着设计对输入模型进行线性组合的模型。
我们称之为 Attention Stacking 的模型相对比较简单,对于每个类,我们初始化一组模型数长度的向量,对这个向量进行 Softmax,我们就获得一组求和为 1 权重,这样我们对这个类别所有模型的预测概率按这组权重进行加权平均,就可以得到这个类别的预测结果。因为这种加权求和的形式和流行的 Attention 机制有点像,我们就叫它 Attention Stacking,虽然它可能有其他更正式的叫法,但我们还没时间仔细查文献,所以暂且这么称呼。
Stacking 阶段我们按照单模型阶段的五折划分进行了交叉验证,整个流程和单模型阶段有点像。不过 Stacking 阶段,按验证集的 F2-Score 进行 early stopping,在验证集上求阈值的阶段,我们有不同的两套方案:
• 方案一:out-of-fold 的做法,这个方案还是在 out-of-fold 上搜索阈值,要注意的一点是,每个折的模型的测试输入要使用第一阶段对应的折的预测结果,确保产生搜索阈值用的验证集和测试集的输入概率矩阵由相同的第一阶段模型产生。
• 方案二:非 out-of-fold 的做法,下图可以看做是一个将 Attention Stacking 每个类的权重拼在一起得到的矩阵,沿模型维度每列求和为 1。因为 Attention Stacking 的做的其实是对每个类不同模型预测结果的一种线性组合,我们可以把五折求出来的五个权重矩阵直接平均获得一个新的权重矩阵。然后用这个新的权重矩阵对所有训练数据和测试数据进行加权平均,在加权平均的训练数据上搜索阈值,应用在测试数据的加权平均结果上得到类预测。这种方案也保持了搜索阈值所用的集合与测试集预测结果产生的方式一致。
经过我们的测试中,方案二比方案一表现得更好。
到此,我们的方案也基本讲解完毕。最后,我想给大家讲讲我们比赛中的一些经历和对比赛结果的分析。
4. 学习,奋斗,结果与伟大的随机性
在上次参加 Quora Question Pairs 的过程中,我们在获得一些文本类比赛实战经验的同时,也对 Kaggle 比赛的流程和基本方法有了一定的了解,并将经验总结写成了《分分钟带你杀入Kaggle Top 1%》:
https://zhuanlan.zhihu.com/p/27424282
为了学习一些新的东西以及验证我们对 Kaggle 比赛套路的理解,我们选择了正在进行的 Planet: Understanding the Amazon from Space,这是一个图像多标签的分类任务,和 Quora Question Pairs 的文本二分类任务有很大不同。
4.1 学习与前进
在参加这个比赛前,我们队里并没有人有太多参加图像比赛的经验,关注到这个比赛的时候,三个月的比赛也只剩下一个月。一开始的十天,因为大家还有各种的项目工作没有完结,只有两三个队友零星地探索,游荡在 Public LB 一百多名。在剩下最后二十天的时候,我们陆续完成了手头的工作,腾出了时间和计算资源,全力地参加这个比赛。
我们花了一两天搜集了这个比赛和其它类似比赛的信息,从中总结出了一些基本的套路。在探索和确定出基本方案后,我们队内各自独立地去实现和探索,每个人都有自己一套代码。保持代码和结果的独立,主要是为了合队的时候能够有更多样性的结果,这往往能给 Ensemble 结果带来较大的提升。我们发现,即使在这样一套不算复杂的解决方案中,大家对各种细节的理解也有很多不同,这些不同让我们每次合队时都有不小的提升。










