近日,来自卡内基梅隆大学、日本奈良先端科学技术大学、Google DeepMind、以色列巴伊兰大学、艾伦人工智能研究所、IBM T.J. Watson 研究中心、澳大利亚墨尔本大学、约翰·霍普金斯大学、谷歌、华盛顿大学、微软和英国爱丁堡大学的研究者共同发表了一篇重磅论文《DyNet: The Dynamic Neural Network Toolkit》,正式介绍了动态神经网络工具包 DyNet;该工具包也已在 GitHub 上开源:http://github.com/clab/dynet。机器之心对这篇论文进行了摘要性的介绍,论文原文可点击文末「阅读原文」下载。

摘要:在本论文中,我们将介绍 DyNet——一个基于网络结构的动态声明(dynamic declaration of network structure)的用于实现神经网络模型的工具包。在 Theano、CNTK 和 TensorFlow 等工具包中所用的静态声明策略(static declaration strategy)中,用户需要首先定义计算图(computation graph,即计算过程的符号表示),然后样本会被传递给执行该计算的引擎并计算其导数。而在 DyNet 的动态声明策略中,计算图的构建(construction)基本上是透明的,通过执行用于计算网络输出的程序代码来隐式地构造;对于任意一个输入,用户都可以自由得使用不同的网络结构。因此,动态声明有助于实现更复杂的网络架构;特别的,DyNet 允许用户使用他们喜爱的编程语言(C ++ 或 Python)以一种他们惯用的方式来实现他们的模型。在动态声明中,有一件充满挑战的事情:由于对于每个训练样本都要重新定义符号计算图,所以其构建的开销必须要低。为了实现这一点,DyNet 使用了一个经过优化的 C ++ 后端和轻量级的图表示(graph representation)。实验表明,DyNet 的速度与静态声明工具包相当甚至比其更快,并且明显快于另一个动态声明工具包 Chainer。DyNet 根据 Apache 2.0 许可证进行了开源,可以在这里访问:http://github.com/clab/dynet
1. 引言
深度神经网络现在是机器学习开发者的工具箱中不可或缺的工具,它在图像理解 [39]、语音的识别与合成 [29,65]、游戏 [45,54]、语言建模和分析 [6, 14 ] 等领域中拥有重要的地位。首先,深度学习将应用特定的特征工程(加上理解良好的模型,这是经典的「浅度」学习的范式)替换成了应用特定的模型工程(model engineering,通常结合了输入的不太复杂的特征)。因此,深度学习范式在不断发展新的模型变体。要开发有效的模型不仅仅需要洞察力和进行分析,还需要实现一些新模型并评估其在实际任务上的表现。因此,快速的原型设计、高效轻松的维护和正确的模型代码在深度学习中至关重要。
深度学习模型以两种模式操作:在给定输入的情况下计算预测值(或者是预测上的分布),或者在监督学习训练的时候计算相关模型参数的预测误差「损失」的导数,用于使用梯度下降方法的某些变体来最小化和类似输入之间后续的误差。因为实现模型需要同时实现模型预测的代码和进行梯度计算和学习的代码,所以模型开发是一个非常困难的工程挑战。通过使用简化神经网络计算的工具,可以减少这种挑战的难度。这些工具包括 Theano [7]、TensorFlow [1]、Torch [13]、CNTK [64]、MxNet [10] 和 Chainer [62],它们提供了神经网络功能原语(例如线性代数运算、非线性变换等)、参数初始化和程序优化以及表达特定任务预测和误差的复合能力——这些预测和误差然后会被自动微分(autodiff)以获取驱动学习算法所需的梯度。最后的自动微分(autodiff)组件可以说是它们最重要的节省劳动的功能,因为如果要改变计算训练输入损失值的函数,那么其导数的计算过程也要做出相应的改变。如果工程师独立地维护这些代码路径,则它们很容易导致它们不能同步。此外,由于对复合表达式的微分的算法相对简单 [63,31],所以使用 autodiff 算法代替手写代码计算导数是个不错的选择。
简言之,由于这些工具有效地解决了一些关键的软件工程问题,它们让深度学习取得了成功。不过仍然存在一些问题:因为工程(engineering)是深度学习实践的关键组成部分,什么工程问题是现有工具无法解决的呢?它们能让程序员比较自然地实现自己的想法吗?它们是否便于调试?它们是否方便大型项目的维护?
在本论文中,我们将推荐一个基于几个流行工具包的编程模型——即将网络架构的声明和执行(我们称为静态声明)进行分离,在这其中必然会存在一些严重的软件工程风险,特别是在处理动态结构化网络架构(例如,可变长度的序列和树形结构的递归神经网络)的时候。作为一种替代方案,我们提出了一个替代的编程模型,它可在 autodiff 库中进行统一声明和执行。
作为我们推荐的编程模型的概念证明,我们通过论文《DyNet: The Dynamic Neural Network Toolkit》进行了描述。DyNet 是一个基于统一声明和执行编程模型的工具包,我们称之为动态声明(dynamic declaration)。
在单台机器环境(single-machine environment)中的一系列案例研究中,我们表明 DyNet 的执行效率与标准模型架构的静态声明工具包相当。和使用动态架构(例如,其中每个训练实例具有不同的模型架构)的模型相比,DyNet 的实现得到了显著的简化。
2. 静态声明 vs. 动态声明
在本节中,我们更具体地描述了静态声明(§2.1)和动态声明(§2.2)的两种范式。
3.范式编码
3.1 编码范式概述
从用户的角度来看,使用 DyNet 编写程序的目的是创建对应于需要被执行的计算的表达式(Expression)。这首先从基本的表达式开始,基本表达式通常是常量输入值或模型参数(Parameters)。然后,通过进行运算(Operation)从其他表达式进一步构建复合表达式,并且运算链(chain of operations)隐含地为所需的计算定义一个计算图(ComputationGraph)。该计算图表示了符号计算,并且计算的结果是被动的:仅当用户显式地请求它时(在该点触发「前向(forward)」计算)才执行计算。评估标量(即损失值)的表达式也可以用于触发「后向」计算,其以参数为依据来计算计算的梯度。参数和梯度被保存在模型(Model)对象中,训练器(Trainer)用于根据梯度和更新规则来更新参数。
我们下面将简要地介绍这些每种组件:
Parameter 和 LookupParameter:Parameter 是表示诸如权重矩阵和偏置向量之类的实数向量、矩阵或张量。LookupParameters 是我们想要查找的参数向量集,例如词嵌入(word embeddings)。换句话说,如果我们有一个词汇集 V,我们想要查找其嵌入(embeddings),那么就有一个 LookupParameters 对象定义一个 | V | ×d 矩阵,其作为一个嵌入矩阵与 0,...,| V | -1 到 d 维向量的项形成映射。Parameters 和 LookupParameters 被存储在模型中,并可以跨越训练样本(即跨不同的 ComputationGraph 样本)进行保存。
模型(Model):模型是 Parameters 和 LookupParameters 的集合。用户通过从模型中请求 Parameters 来获取它们。然后模型会跟踪这些参数(及其梯度)。模型可以保存到磁盘中也可以通过磁盘加载,也可以被下面要讲到的 Trainer 对象使用。
训练器(Trainer):训练器实现在线更新规则,比如简单随机梯度下降、AdaGrad [16] 或 Adam [34]。Trainer 有指向 Model 对象的指针,所以同时也有其中的参数,并且还可以根据更新规则的需要保存关于参数的其他信息。
表达式(Expression):在 DyNet 项目中,表达式是主要的可以被操作的数据类型。单个表达式代表了一个计算图中的一个子计算。举个例子,一个表示矩阵或者向量的参数对象可以被加进计算图里,这就产生了一个表达式 W 或者 b。同样,一个 LookupParameters 对象 E 可以通过查找操作来查询一个专门的嵌入向量(它也是被加在计算图里的),这就产生了一个表达式 E[i]。这些表达式可以被组合成更大的表达式,例如 concatenate(E[3], E[4]) 或者 softmax(tanh(W ∗ concatenate(E[3], E[4]) +b))。这里的 softmax、tanh、∗、+、concatenate 都是运算,下面详细介绍。
运算(Operations):运算不是对象,而是在表达式以及返回表达式上运行的函数,它用来在后台构建计算图。DyNet 为很多基本的算术原语(加、乘、点积、softmax、...)和常用的损失函数、激活函数等等都定义了相应的运算。当情况适宜时,运算可以通过运算符重载来定义,这使得图的构建能尽可能地直观和自然。
构造器类(Builder Classes):Builder Classes 定义了创建各种「标准化」的网络组件(比如循环神经网络、树结构网络和大词汇量 softmax)的接口。这些都工作在表达式和运算之上,并且提供了各种易用的库。Builder Classes 为各种标准算法提供了高效便捷的实现。不过,从代码层次的意义上来说,它并不是「核心」DyNet 库的一部分,因为 Builder Classes 是更高层次的,它实现在 DyNet 最核心的自动微分功能之上。Builder Classes 将会在后续的§5 中深入讨论。
计算图(ComputationGraph):表达式相当于一种隐含的计算图对象的一部分,该计算图定义了需要进行的计算是什么。DyNet 目前假定在任意一个时刻只有一个计算图存在。尽管计算图是 DyNet 内部工作的核心,但从使用者的角度来看,唯一需要负责做的是为每个训练样本创建一个新的计算图。
用 DyNet 中实现并训练一个模型的整体流程可描述如下:
(a) 创建一个新的计算图(ComputationGraph),并且建立一个表达式(Expression)来填充该计算图,该表达式用来表示针对这个样本想要进行的计算。
(b) 通过调用最终表达式的 value() 或者 npvalue() 函数,计算整个图前向计算的结果。
(c) 如果训练的话,计算损失函数的表达式,并使用它的 backward() 函数来进行反向传播。
(d) 使用训练器对模型的参数进行更新。
与像 Theano 和 TensorFlow 这样的静态声明库对比可以发现,创建一个图的步骤落在每一个样本的循环里。这有利于使用户为每个实例(instance)灵活地创建新的图结构,并使用他们掌握的编程语言中的流控句法(flow control syntax,比如迭代(iteration))来做这些。当然,它也增加了对图结构速度的要求,即它要足够快,不能变成负担,我们会在§4 中进一步阐述。
3.2 高层面的示例
为了在更高层次说明 DyNet 的编码范式,我们用 Python 演示了一个 DyNet 程序的例子,如图 1 所示。这个程序显示了为一个简单分类器进行最大似然训练的过程,这个分类器为每个需要它预测的类计算一个向量分数,然后返回这个得分最高的类 ID 以及这个最高分。我们假定每个训练样本是一个(输入和输出)对,其中输入是一个二词索引的元组,输出是一个指示正确类的数。

图 1:一个使用 DyNet 的 Python API 进行训练和测试的例子。
在头两行,我们导入(import)适当的库。在第 3 行,我们初始化 DyNet 模型,并为相关参数分配内存空间,但是不初始化它们。在第 4—6 行,我们向模型里添加我们的参数,这个过程会因为使用的模型不同而不一样。这里我们增加一个 20 × 100 的权重矩阵、一个 20 维的偏置向量和一个查找表(嵌入表)——该查找表的词汇量大小为 20000 项映射到 50 维向量。在第 7 行,我们初始化了一个训练器(在这个例子中是一个简单的随机梯度降(SGD)训练器),这个训练器被用来更新模型参数。在第 8 行中,我们对数据进行多次训练和测试。
从第 9 行开始,我们对训练数据进行迭代。第 10 行,清除当前计算图的内容,开始一个空的计算图,为后续的计算做准备。第 11-13 行,我们创建一个图,这个图会为每个训练实例计算一个分数向量(这个过程会因为模型的不同而不同)。这里我们首先访问模型中的权重矩阵和偏置向量参数(W_p 和 b_p),并把它们加到图中,也就是这个代码例子中用到的表达式中(W 和 b_p)。然后我们根据输入的 id 来查找两个向量,拼接它们,然后做一个线性变换和 softmax,这样就创建了和计算相对应的表达式。接下来,我们在第 14 行创建一个与损失有关的表达式——对正确记分结果做一次 softmax 后的负对数似然估计。在第 15 行,我们计算前向图的结果,在第 16 行,我们计算后向的,并累计模型变量中参数的梯度。在第 17 行,我们根据 SGD 的更新规则更新这些参数,并清掉之前的累计梯度。
接下来,从第 18 和 19 行开始,我们遍历测试数据并测量准确度。在第 20-23 行,我们又一次清除计算图以及定义计算测试数据分数的表达式,方式和我们在训练数据中做的一样。在第 24 行,我们开始计算并把结果数据放到一个 NumPy 的数组里。在第 25 和 26 行,我们检查是否正确的数据是最高分的那个,如果是的话就把它算作是一个正确的结果。最后第 27 行,我们把本次迭代的测试准确度 print 出来。
3.3 动态图构建(Dynamic Graph Construction)的两个示例

图 2:树结构递归神经网络(tree-structured recursive neural network)的一个例子
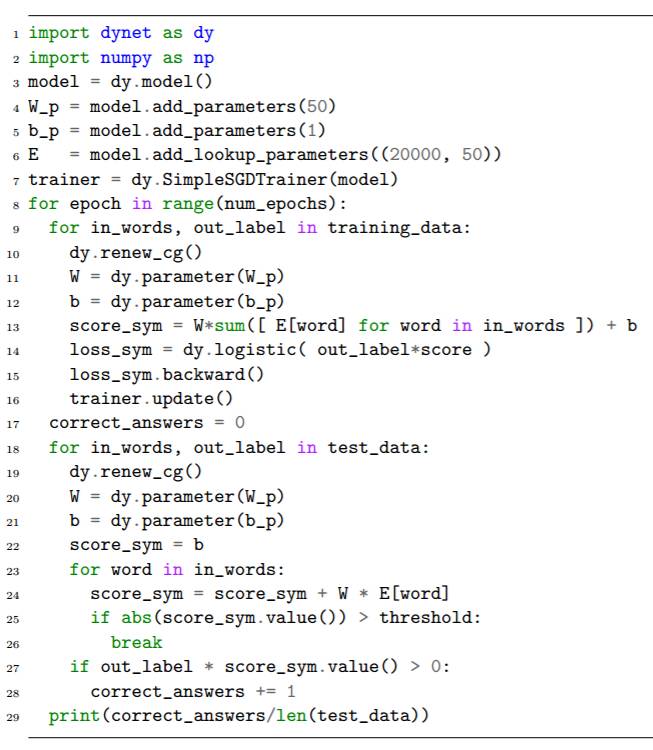
图 3:动态流控制的一个示例。
4 后台工作
如上一节所述,将 DyNet 与其它神经网络工具包相区别的一个主要特性是,它能够为每个训练样本或 minibatch 有效地创建新的计算图(Computation Graphs)。为了保持计算效率,DyNet 使用了细致的内存管理策略来存储前向传播和反向传播的计算过程中的值(§4.2),因此大部分时间都会用在实际的计算上(§4.3)
4.1 计算图(Computation Graphs)
图 4:公式 g(x, j) = tanh(W1∗x+b)+tanh(W2∗ej+b) 的计算图的例子,以及相应的代码。
4.2 高效的图构建
4.3 执行计算
5 更高级的抽象结构
如第 3 节所述,DyNet 实现了在张量(tensors)上表示基本(子)可微函数的运算。这和 Theano 和 TensorFlow 库中提供的运算是相似的。除了这些基本运算外,使用可被视为由基本运算组成的更复杂的结构也是很常见的。常见的例子有循环神经网络(RNN)、树结构神经网络(tree-structured networks)和更复杂的计算 softmax 概率分布的方法。在其它库中,这些更高级别的结构或是通过本地提供,亦或是通过第三方库(如 Keras)提供。在 DyNet 中,循环神经网络的本地支持、树结构神经网络和更复杂的 softmax 函数都是通过 Builder 提供的;具体细节会在接下来的章节描述,图 5 中也有所总结。
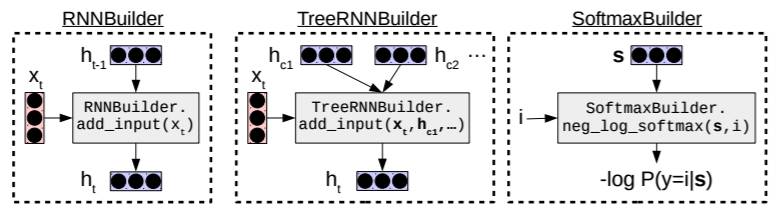
图 5:DyNet Builders 实现的更高级结构的示例,以及它们的规范使用
5.1 循环神经网络的 Builders
5.2 树结构神经网络的 Builders
5.3 Large-Vocabulary Softmax Builders

图 6:各种 RNN 接口
6 效率工具
DyNet 包含许多可以提高计算效率的功能,包括稀疏更新(sparse updates)、minibatching 和跨 CPU 的多处理(multi-processing across CPUs)。
7 实证比较
在本节中,我们将使用 C++ 接口和 Python 接口将 DyNet 和其他三个流行库(Theano [7]、TensorFlow [1] 和 Chainer [62])进行对比。我们选择这些库是因为 Theano 和 TensorFlow 可以说是目前最受欢迎的深度学习库,而 Chainer 的 define-by-run 哲学和 DyNet 相似。
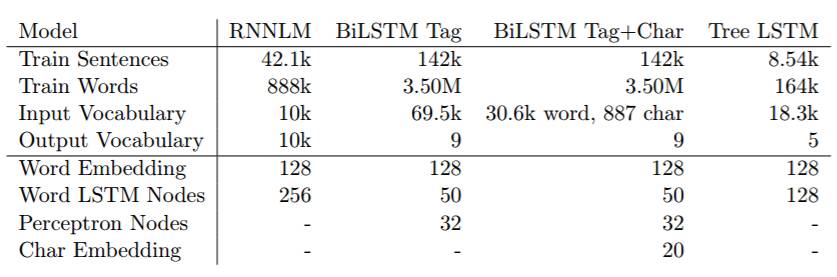
表 1:各个任务的数据和默认设置。
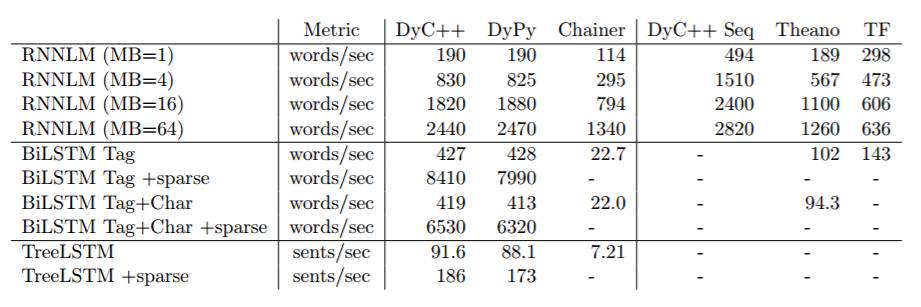
表 2:每个工具箱在 CPU 上的处理速度。速度是以 RNNLM 与 Tagger 处理的词/秒和 TreeLSTM 处理的句/秒进行衡量的。带 +sparse 的行表示 LookupParameters 的稀疏更新(sparse updates),这是 DyNet 中的默认行为,但与其他工具包的执行密集更新(dense updates)的实现不可对比。
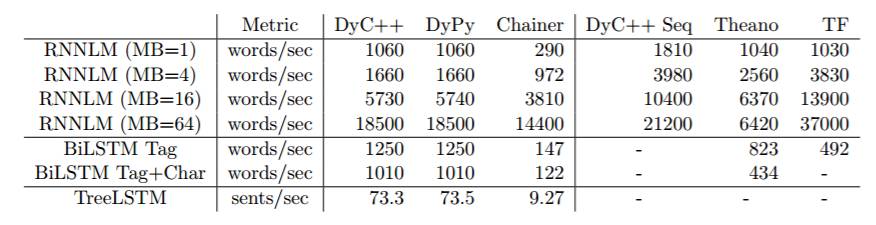
表 3:每个工具箱在 GPU 上的处理速度。速度是以 RNNLM 与 Tagger 处理的词/秒和 TreeLSTM 处理的句/秒进行衡量的。
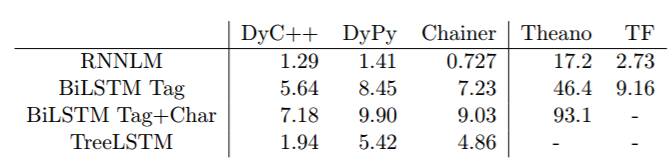
表 4:从程序启动到为每个工具包处理第一个实例的时间(秒)。
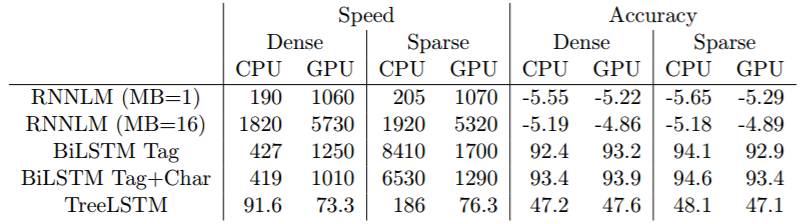
表 5:密集或稀疏更新(dense or sparse updates)10 分钟后的处理速度和准确度。

表 6:每个工具包的实现的非注释字符数。
8 使用案例
DyNet 已经投入使用,并已被用于各种各样的项目,主要涉及自然语言处理。DyNet 本身包含一些从最小到中等复杂度的示例(在 examples/ 目录下)。我们还列出了一些全面的研究项目,可以让有兴趣的读者找到匹配他们感兴趣的应用程序的参考样例。
句法分析(Syntactic Parsing):分析是目前使用 DyNet 的最突出的场景,DyNet 是许多方法的开发背后的库,例如 stack LSTMs [17](https://github.com/clab/lstm-parser)、用于依赖性解析的双向 LSTM 特征提取器(https://github.com/elikip/bist-parser)、循环神经网络语法 [18](https://github.com/clab/rnng),和 LSTM 层次树 [35](https://github.com/elikip/htparser)。
机器翻译(Machine Translation):DyNet 帮助创造了包括注意偏差(biases in attention)[12](https://github.com/trevorcohn/mantis)和基于字符的 27 种翻译方法 [42] 等方法。它还为许多机器翻译工具包提供支持,如 Lamtram(https://github.com/neubig/lamtram)和 nmtkit(https:// github.com/odashi/nmtkit)。
语言建模(Language Modeling):DyNet 已被用于混合神经/n 元语言模型(hybrid neural/n-gram language models)的开发 [47](https://github.com/neubig/modlm)和生成语法语言模型 [18](https://github.com/clab/rnng)。
标注(Tagging):DyNet 用于命名实体识别方法的开发 [47](https://github.com/clab/stack-lstm-ner)、POS 标注、语义角色标签 [60](https://github.com/clab/joint-lstm-parser)、标点符号预测 [5](https://github.com/miguelballesteros/LSTM-punctuation)和序列处理的多任务学习 [37,56] 以及创建新的架构,如段循环神经网络(segmental recurrent neural networks)[38](https://github.com/clab/dynet/tree/ master/examples/cpp/segrnn-sup)。
形态(Morphology):DyNet 已被用于形态变化生成 [21, 2](https://github.com/mfaruqui/morph-trans https://github.com/roeeaharoni/morphological-reinflection)。
杂项:DyNet 已被用于开发专门的用于检测协调结构的神经网络 [22];半监督的介词意义消歧 [23]; 和用于识别词汇语义关系 [53,52](https://github.com/vered1986/HypeNET)。
总结、致谢和参考文献(略)
©本文为机器之心编译,
转载请联系本公众号获得授权
。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]





