关注
HarmonyOS技术社区
,回复
【鸿蒙】
送10个
小米小爱音箱mini
(明日开奖,赶快参与)
,还可以
免费下载
鸿蒙
入门资料
!
👇
扫码
立刻关注
👇

专注开源技术,共建鸿蒙生态
如今,越来越多的企业在业务场景是使用 Elasticsearch(下文统一称为 ES) 存储自己的非结构化数据。
图片来自 Pexels
例如电商业务实现商品站内搜索,数据指标分析,日志分析等,ES 作为传统关系型数据库的补充,提供了关系型数据库不具备的一些能力。
ES 最先进入大众视野的是其能够实现全文搜索的能力,也是由于基于 Lucene 的实现,内部有一种倒排索引的数据结构。
本文作者将介绍 ES 的分布式架构,以及 ES 的存储索引机制,本文不会详细介绍 ES 的 API,会从整体架构层面进行分析。
要讲明白什么是倒排索引,首先我们先梳理下什么索引,比如一本书,书的目录页,有章节,章节名称,我们想看哪个章节,我们通过目录页,查到对应章节和页码,就能定位到具体的章节内容。
通过目录页的章节名称查到章节的页码,进而看到章节内容,这个过程就是一个索引的过程,那么什么是倒排索引呢?
比如查询《java 编程思想》这本书的文章,翻开书本可以看到目录页,记录这个章节名字和章节地址页码。
通过查询章节名字“继承”可以定位到“继承”这篇章节的具体地址,查看到文章的内容,我们可以看到文章内容中包含很多“对象”这个词。
那么如果我们要在这本书中查询所有包含有“对象”这个词的文章,那该怎么办呢?
按照现在的索引方式无疑大海捞针,假设我们有一个“对象”--→文章的映射关系,不就可以了吗?类似这样的反向建立映射关系的就叫倒排索引。
如图 1 所示,将文章进行分词后得到关键词,在根据关键词建立倒排索引,关键词构建成一个词典,词典中存放着一个个词条(关键词),每个关键词都有一个列表与其对应。
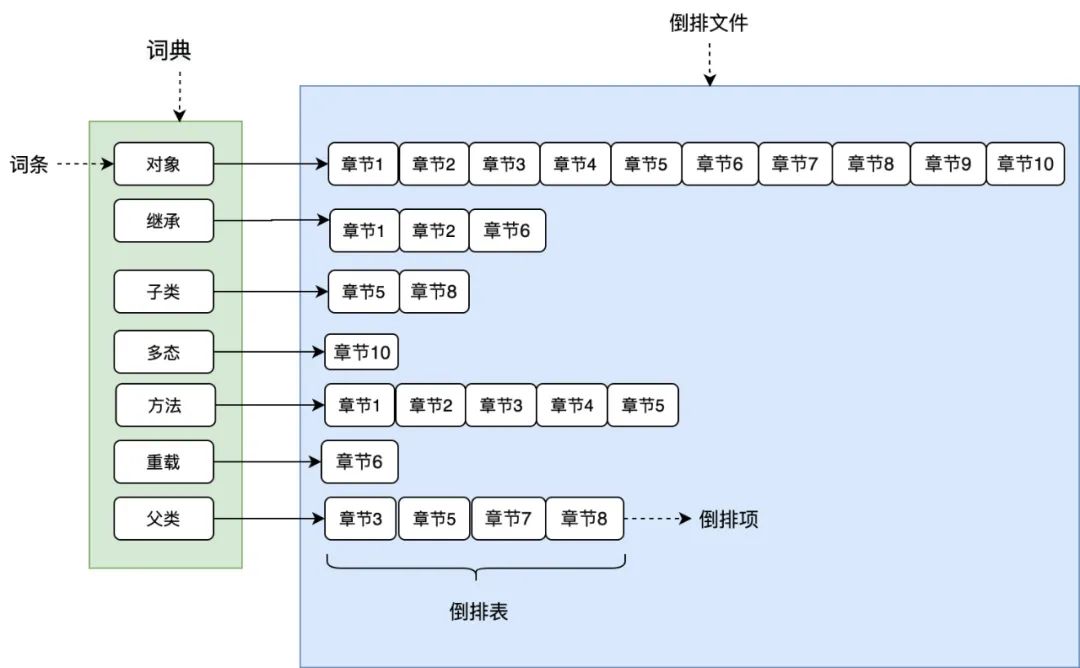
这个列表就是倒排表,存放的是章节文档编号和词频等信息,倒排列表中的每个元素就是一个倒排项。
最后可以看到,整个倒排索引就像一本新华字典,所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件。
词典和倒排文件是 Lucene 的两种基本数据结构,但是存储方式不同,词典在内存中存储,倒排文件在磁盘上。
本文不会去介绍分词,tf-idf,BM25,向量空间相似度等构建倒排索引和查询倒排索引所用到的技术,读者只需要对倒排索引有个基本的认识即可。
一个 ES 集群可以有多个节点构成,一个节点就是一个 ES 服务实例,通过配置集群名称 cluster.name 加入集群。
那么节点是如何通过配置相同的集群名称加入集群的呢?要搞明白这个问题,我们必须先搞清楚 ES 集群中节点的角色。
ES 中节点有角色的区分的,通过配置文件 conf/elasticsearch.yml 中配置以下配置进行角色的设定。
node.master: true/false
node.data: true/false
集群中单个节点既可以是候选主节点也可以是数据节点,通过上面的配置可以进行两两组合形成四大分类:
-
仅为候选主节点
-
既是候选主节点也是数据节点
-
仅为数据节点
-
既不是候选主节点也不是数据节点
候选主节点:
只有是候选主节点才可以参与选举投票,也只有候选主节点可以被选举为主节点。
主节点:
负责索引的添加、删除,跟踪哪些节点是群集的一部分,对分片进行分配、收集集群中各节点的状态等,稳定的主节点对集群的健康是非常重要。
数据节点:
负责对数据的增、删、改、查、聚合等操作,数据的查询和存储都是由数据节点负责,对机器的 CPU,IO 以及内存的要求比较高,一般选择高配置的机器作为数据节点。
此外还有一种节点角色叫做协调节点,其本身不是通过设置来分配的,用户的请求可以随机发往任何一个节点,并由该节点负责分发请求、收集结果等操作,而不需要主节点转发。
这种节点可称之为协调节点,集群中的任何节点都可以充当协调节点的角色。每个节点之间都会保持联系。
前文说到通过设置一个集群名称,节点就可以加入集群,那么 ES 是如何做到这一点的呢?
这里就要讲一讲 ES 特殊的发现机制 ZenDiscovery。
ZenDiscovery 是 ES 的内置发现机制,提供单播和多播两种发现方式,主要职责是集群中节点的发现以及选举 Master 节点。
多播也叫组播,指一个节点可以向多台机器发送请求。生产环境中 ES 不建议使用这种方式,对于一个大规模的集群,组播会产生大量不必要的通信。
单播,当一个节点加入一个现有集群,或者组建一个新的集群时,请求发送到一台机器。
当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系 Master 节点,并加入集群。
只有在同一台机器上运行的节点才会自动组成集群。ES 默认被配置为使用单播发现,单播列表不需要包含集群中的所有节点,它只是需要足够的节点,当一个新节点联系上其中一个并且通信就可以了。
如果你使用 Master 候选节点作为单播列表,你只要列出三个就可以了。
这个配置在 elasticsearch.yml 文件中:
discovery.zen.ping.unicast.hosts: ["host1", "host2:port"]
集群信息收集阶段采用了 Gossip 协议,上面配置的就相当于一个 seed nodes,Gossip 协议这里就不多做赘述了。
ES 官方建议 unicast.hosts 配置为所有的候选主节点,ZenDiscovery 会每隔 ping_interval(配置项)ping 一次。
每次超时时间是 discovery.zen.ping_timeout(配置项),3 次(ping_retries 配置项)ping 失败则认为节点宕机,宕机的情况下会触发 failover,会进行分片重分配、复制等操作。
如果宕机的节点不是 Master,则 Master 会更新集群的元信息,Master 节点将最新的集群元信息发布出去,给其他节点。
其他节点回复 Ack,Master 节点收到 discovery.zen.minimum_master_nodes 的值 -1 个候选主节点的回复,则发送 Apply 消息给其他节点,集群状态更新完毕。
如果宕机的节点是 Master,则其他的候选主节点开始 Master 节点的选举流程。
①选主
Master 的选主过程中要确保只有一个 master,ES 通过一个参数 quorum 的代表多数派阈值,保证选举出的 master 被至少 quorum 个的候选主节点认可,以此来保证只有一个 master。
选主的发起由候选主节点发起,当前候选主节点发现自己不是 master 节点,并且通过 ping 其他节点发现无法联系到主节点。
并且包括自己在内已经有超过 minimum_master_nodes 个节点无法联系到主节点,那么这个时候则发起选主。
选主的时候按照集群节点的参数
排序。stateVersion 从大到小排序,以便选出集群元信息较新的节点作为 Master,id 从小到大排序,避免在 stateVersion 相同时发生分票无法选出 Master。
排序后第一个节点即为 Master 节点。当一个候选主节点发起一次选举时,它会按照上述排序策略选出一个它认为的 Master。
提到分布式系统选主,不可避免的会提到脑裂这样一个现象,什么是脑裂呢?如果集群中选举出多个 Master 节点,使得数据更新时出现不一致,这种现象称之为脑裂。
简而言之集群中不同的节点对于 Master 的选择出现了分歧,出现了多个 Master 竞争。
一般而言脑裂问题可能有以下几个原因造成:
-
网络问题:
集群间的网络延迟导致一些节点访问不到 Master,认为 Master 挂掉了,而 master 其实并没有宕机,而选举出了新的 Master,并对 Master 上的分片和副本标红,分配新的主分片。
-
节点负载:
主节点的角色既为 Master 又为 Data,访问量较大时可能会导致 ES 停止响应(假死状态)造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
-
内存回收:
主节点的角色既为 Master 又为 Data,当 Data 节点上的 ES 进程占用的内存较大,引发 JVM 的大规模内存回收,造成 ES 进程失去响应。





