【导读】
26岁的OpenAI吹哨人,在发出公开指控不到三个月,被发现死在自己的公寓中。法医认定,死因为自杀。那么,他在死前两个月发表的一篇博文中,都说了什么?
就在刚刚,消息曝出:OpenAI吹哨人,在家中离世。
曾在OpenAI工作四年,指控公司侵犯版权的Suchir Balaji,上月底在旧金山公寓中被发现死亡,年仅26岁。
旧金山警方表示,11月26日下午1时许,他们接到了一通要求查看Balaji安危的电话,但在到达后却发现他已经死亡。
这位吹哨人手中掌握的信息,原本将在针对OpenAI的诉讼中发挥关键作用。
法医办公室认定,死因为自杀。警方也表示,「并未发现任何他杀证据」。
他的X上的最后一篇帖子,正是介绍自己对于OpenAI训练ChatGPT是否违反法律的思考和分析。
他也强调,希望这不要被解读为对ChatGPT或OpenAI本身的批评。
Suchir Blaji的朋友也表示,他人十分聪明,绝不像是会自杀的人。
Suchir Balaji曾参与OpenAI参与开发ChatGPT及底层模型的过程。
今年10月发表的一篇博文中他指出,公司在使用新闻和其他网站的信息训练其AI模型时,违反了「合理使用」原则。
博文地址:https://suchir.net/fair_use.html
然而,就在公开指控OpenAI违反美国版权法三个月之后,他就离世了。
为什么11月底的事情12月中旬才爆出来,网友们也表示质疑
其实,自从2022年底公开发布ChatGPT以来,OpenAI就面临着来自作家、程序员、记者等群体的一波又一波的诉讼潮。
他们认为,OpenAI非法使用自己受版权保护的材料来训练AI模型,公司估值攀升至1500亿美元以上的果实,却自己独享。
今年10月23日,《纽约时报》发表了对Balaji的采访,他指出,OpenAI正在损害那些数据被利用的企业和创业者的利益。
「如果你认同我的观点,你就必须离开公司。这对整个互联网生态系统而言,都不是一个可持续的模式。」
Balaji在加州长大,十几岁时,他发现了一则关于DeepMind让AI自己玩Atari游戏的报道,心生向往。
高中毕业后的gap year,Balaji开始探索DeepMind背后的关键理念——神经网络数学系统。
Balaji本科就读于UC伯克利,主修计算机科学。在大学期间,他相信AI能为社会带来巨大益处,比如治愈疾病、延缓衰老。在他看来,我们可以创造某种科学家,来解决这类问题。
2020年,他和一批伯克利的毕业生们,共同前往OpenAI工作。
然而,在加入OpenAI、担任两年研究员后,他的想法开始转变。

在那里,他被分配的任务是为GPT-4收集互联网数据,这个神经网络花了几个月的时间,分析了互联网上几乎所有英语文本。
Balaji认为,这种做法违反了美国关于已发表作品的「合理使用」法律。今年10月底,他在个人网站上发布一篇文章,论证了这一观点。
目前没有任何已知因素,能够支持「ChatGPT对其训练数据的使用是合理的」。但需要说明的是,这些论点并非仅针对ChatGPT,类似的论述也适用于各个领域的众多生成式AI产品。
根据《纽约时报》律师的说法,Balaji掌握着「独特的相关文件」,在纽约时报对OpenAI的诉讼中,这些文件极为有利。
在准备取证前,纽约时报提到,至少12人(多为OpenAI的前任或现任员工)掌握着对案件有帮助的材料。
在过去一年中,OpenAI的估值已经翻了一倍,但新闻机构认为,该公司和微软抄袭和盗用了自己的文章,严重损害了它们的商业模式。
微软和OpenAI轻易地攫取了记者、新闻工作者、评论员、编辑等为地方报纸作出贡献的劳动成果——完全无视这些为地方社区提供新闻的创作者和发布者的付出,更遑论他们的法律权利。
而对于这些指控,OpenAI予以坚决否认。他们强调,大模型训练中的所有工作,都符合「合理使用」法律规定。
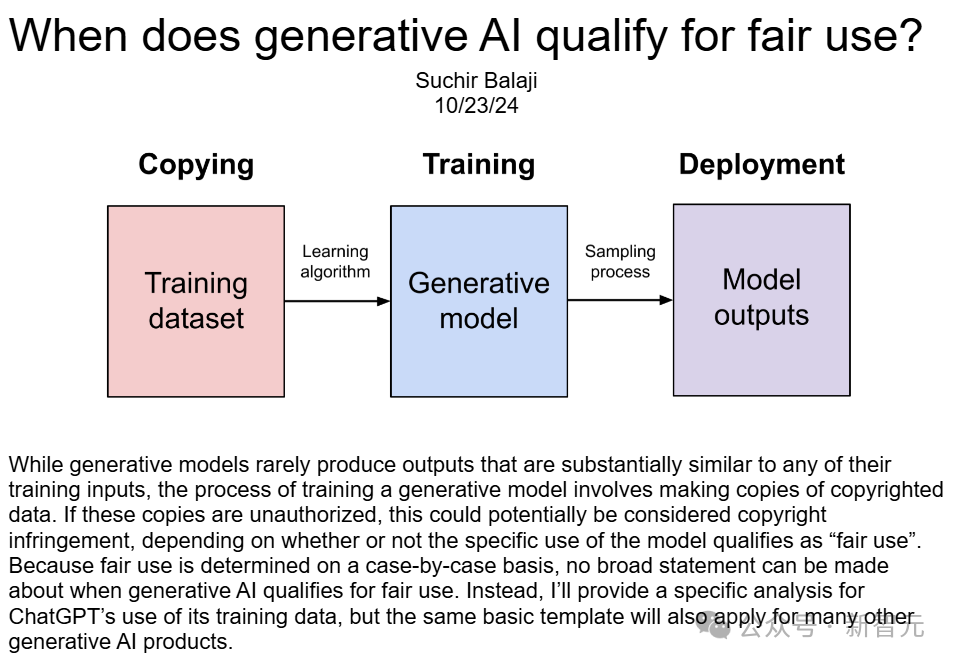
为什么OpenAI违反了「合理使用」法?Balaji在长篇博文中,列出了详尽的分析。
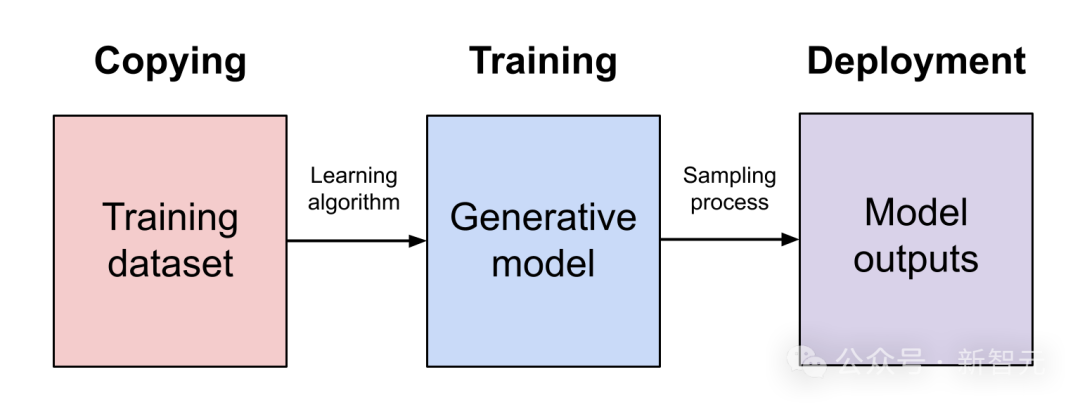
他引用了1976年《版权法》第107条中对「合理使用」的定义。
(1)使用的目的和性质,包括该使用是否具有商业性质或是否用于非营利教育目的;(2)受版权保护作品的性质;(3)所使用部分相对于整个受版权保护作品的数量和实质性;(4)该使用对受版权保护作品的潜在市场或价值的影响。
按(4)、(1)、(2)、(3)的顺序,Balaji做了详细论证。
因素(4):对受版权保护作品的潜在市场影响
由于ChatGPT训练集对市场价值的影响,会因数据来源而异,而且由于其训练集并未公开,这个问题无法直接回答。
《生成式AI对在线知识社区的影响》发现,在ChatGPT发布后,Stack Overflow的访问量下降了约12%。
此外,ChatGPT发布后每个主题的提问数量也有所下降。
提问者的平均账户年龄也在ChatGPT发布后呈上升趋势,这表明新成员要么没有加入,要么正在离开社区。
而Stack Overflow,显然不是唯一受ChatGPT影响的网站。例如,作业帮助网站Chegg在报告ChatGPT影响其增长后,股价下跌了40%。
当然,OpenAI和谷歌这样的模型开发商,也和Stack Overflow、Reddit、美联社、News Corp等签订了数据许可协议。
总之,鉴于数据许可市场的存在,在未获得类似许可协议的情况下使用受版权保护的数据进行训练也构成了市场利益损害,因为这剥夺了版权持有人的合法收入来源。
因素(1):使用目的和性质,是商业性质,还是教育目的
书评家可以在评论中引用某书的片段,虽然这可能会损害后者的市场价值,但仍被视为合理使用,这是因为,二者没有替代或竞争关系。
这种替代使用和非替代使用之间的区别,源自1841年的「Folsom诉Marsh案」,这是一个确立合理使用原则的里程碑案例。
问题来了——作为一款商业产品,ChatGPT是否与用于训练它的数据具有相似的用途?
显然,在这个过程中,ChatGPT创造了与原始内容形成直接竞争的替代品。
比如,如果想知道「为什么在浮点数运算中,0.1+0. 2=0.30000000000000004?」这种编程问题,就可以直接向ChatGPT(左)提问,而不必再去搜索Stack Overflow(右)。
因素(2):受版权保护作品的性质
这一因素,是各项标准中影响力最小的一个,因此不作详细讨论。
因素(3):使用部分相对于整体受保护作品的数量及实质性
(1)模型的训练输入包含了受版权保护数据的完整副本,因此「使用量」实际上是整个受版权保护作品。这不利于「合理使用」。
(2)模型的输出内容几乎不会直接复制受版权保护的数据,因此「使用量」可以视为接近零。这种观点支持「合理使用」。
在信息论中,最基本的计量单位是比特,代表着一个是/否的二元选择。
在一个分布中,平均信息量称为熵,同样以比特为单位(根据香农的研究,英文文本的熵值约在每个字符0.6至1.3比特之间)。
两个分布之间共享的信息量称为互信息(MI),其计算公式为:
在公式中,X和Y表示随机变量,H(X)是X的边际熵,H(X|Y)是在已知Y的情况下X的条件熵。如果将X视为原创作品,Y视为其衍生作品,那么互信息I(X;Y)就表示创作Y时借鉴了多少X中的信息。
对于因素3,重点关注的是互信息相对于原创作品信息量的比例,即相对互信息(RMI),定义如下:
此概念可用简单的视觉模型来理解:如果用红色圆圈代表原创作品中的信息,蓝色圆圈代表新作品中的信息,那么相对互信息就是两个圆圈重叠部分与红色圆圈面积的比值:
在生成式AI领域中,重点关注相对互信息(RMI),其中X表示潜在的训练数据集,Y表示模型生成的输出集合,而f则代表模型的训练过程以及从生成模型中进行采样的过程:
在实践中,计算H(Y|X)——即已训练生成模型输出的信息熵——相对容易。但要估算H(Y)——即在所有可能训练数据集上的模型输出总体信息熵——则极其困难。
至于H(X)——训练数据分布的真实信息熵——虽然计算困难但仍是可行的。










