今天继续上次的话题,来认识下今天的主题——
类人化标注:多样性和独特性图像标注。
该主要提出了一种全新的自动图像标注的生成式模型,名为
多样性和独特性图像标注
(
D2IA
)。受到人类标注集成的启发,
D2IA
将产生语义相关,独特且多样性的标签。
利用生成对抗网络(GAN)来训练
D2IA
,在两个基准数据集上开展了充分的实验,包括定量和定性的对比,以及人类主观测试。实验结果说明,相对于目前最先进的自动图像标注方法,其提出的方法可以产生更加多样和独特的标签。
首先来看看多种方法的比较:
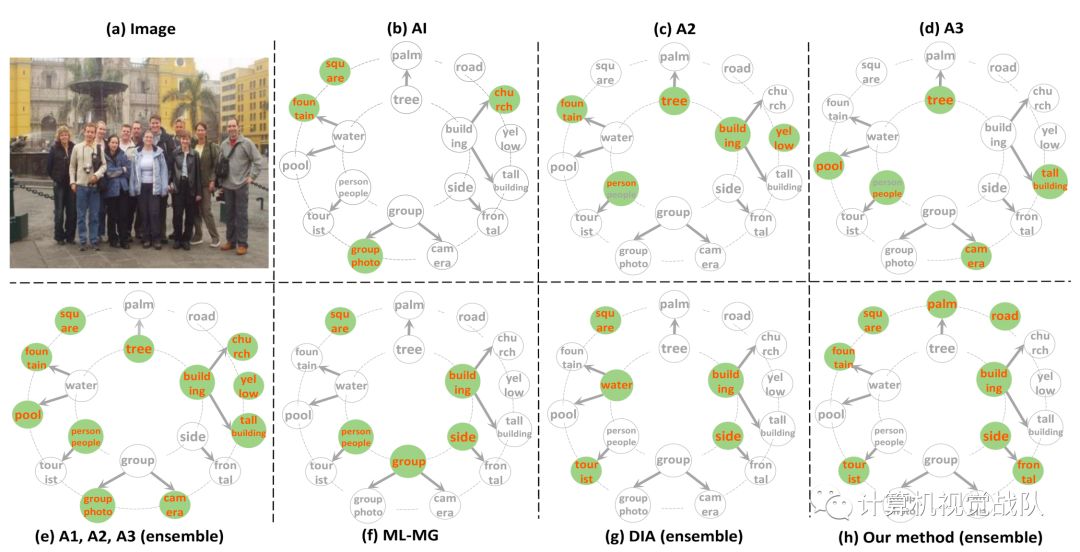
图1
注意,单个人工标注倾向于使用语义上不同的标记(参见图1(b)-(d),并且标记之间的语义冗余低于标注算法MLMG生成的标记之间的语义冗余(参见图1(f)。
最近研究了如何提高生成标记的语义区分性,该方法利用一个行列式点过程(DPP)模型来生成语义冗余较少的标记。在示例图像上运行此算法的标注结果如图1(g)所示。然而,与人类标注相比,这样的结果仍然缺乏一个方面见图1(e))。人类标注的集体注释也往往是多种多样的,包括更多的图像语义元素的标记。
于是,提出了一种新的图像标注模型,即多样化和清晰的图像标注(
D2IA
),其目的是通过学习多个人工标注者生成的标记模型来提高图像标记的多样性和独特性。这种差异性使得同一子集中的标记之间的语义冗余程度较小,而多样性则鼓励不同的标记子集覆盖不同的图像内容的不同方面或不同的语义层次
特别地,该生成模型首先将图像特征向量和随机噪声向量的级联映射为相对于所有候选标记的后验概率,然后将其合并到一个确定性点过程(DPP)模型中,通过顺序抽样生成一个不同的标记子集。利用同一幅图像的多个随机噪声向量,对多个不同的标记子集进行采样。
主要框架如下图2所示:
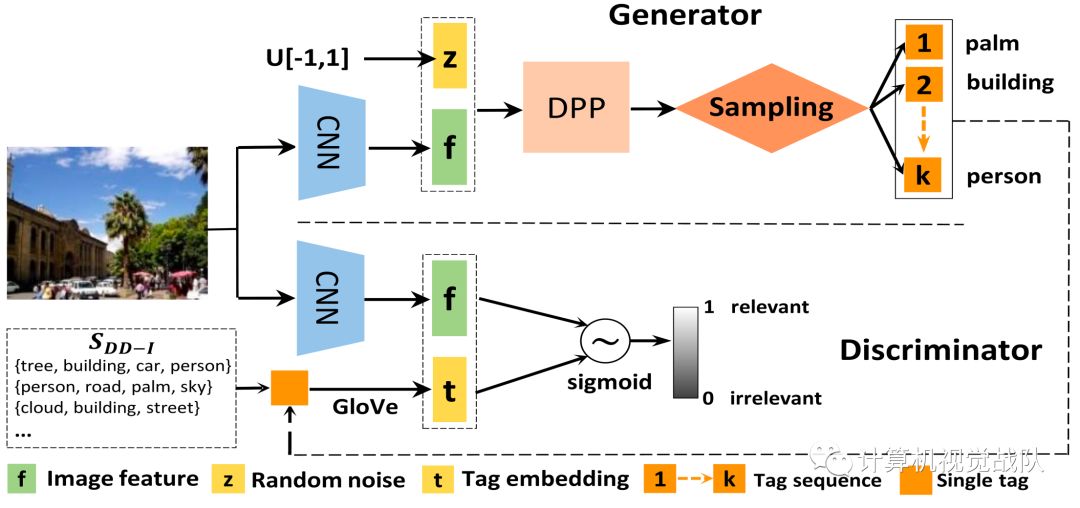
图2 D2IA-GAN模型
D2IA-GAN
模型的一个特点是它的发生器包含一个采样步骤,它不容易直接使用基于梯度的优化方法进行优化。在强化学习算法的启发下,提出了一种基于策略梯度(PG)算法的方法,用可微策略函数(神经网络)对离散采样进行建模,并设计奖励以鼓励生成的标记子集尽可能接近图像内容。将策略梯度算法应用于
D2IA-GAN
的训练中,可以有效地获得基于图像的标签生成模型。
这项工作的主要贡献其实有四个方面:
-
(1) 提出了一种新的图像标注方法,即不同的图像注解器(
D2IA
),为图像创建相关的、清晰的、多样的标注,与不同的人类标注者为同一图像提供的标记更相似;
-
(2) 将该问题转化为学习一个基于图像内容的标签概率生成模型,该模型利用
DPP
模型来保证显著性,并进行随机扰动以改善生成标签的多样性;
-
(3) 生成模型采用了我们称之为
D2IA-GAN
的专门设计的GAN模型进行逆训练;
-
(4) 在
D2IA-GAN
的训练中,采用策略梯度算法对生成模型中的离散采样过程进行处理。
最后,对
ESP游戏
和
IAPRTC-12
图像注释数据集进行了实验评估,并对生成的标签的质量进行了基于人工注释器的主要研究。评价结果表明,
D2IA-GAN
产生的标注集与先进方法产生的标注集相比,更加多样化和清晰。
加权语义路径基于所有候选标签的语义层次和同义词构造加权语义路径。为了构造加权语义路径,将每个标签视为节点,同义词合并为一个节点。然后,从语义层次中的每个叶节点开始,连接它的直接父节点并重复这个连接过程,直到根节点实现。
在这个过程中访问的所有标签形成叶标签的加权语义路径。在语义路径中每个标签的权重与节点层成反比(层数从叶节点处的0开始)和每个节点的后代数。因此,具有更多指定信息的标签的权重将更大。具体如图3所示:

给定图像I及其真实语义路径spi,如果没有从同一语义路径中采样标记,则标记子集是不同的。图3显示了一个不同标记子集的示例。
使用一个条件行列式点过程(DPP)模型来测量标记子集T的概率,它是从给定的图像I的特征X的真实集T导出的。

D2IA-GAN模型
给定一个图像I,目标是生成一个包含多个与图像内容相关的不同标记子集的不同标记集,以及这些不同子集的一个集合标记子集,这些标记子集可以提供对I的全面描述。这些标记是从以图像为条件的生成模型中采样的,使用一个条件GAN(CGAN)来训练它。
注:生成和判别模型如果有兴趣,可以在文中详细解读。
主要讲解下条件GAN!
给定Dη,通过以下方法学习gθ:

然后,将[−1,1]中的一个实例化z表示为如下形式:

激励函数R(I,Tg-i)鼓励i的内容和标签Tg保持一致,定义为:

与Full PG目标函数相比,在之前公式中,用即时激励
R(I,Tg-i)
代替了return,用分解的似然代替了策略概率:

在训练过程中产生Tg时,多次重复采样过程以获得不同的子集。然后,由于每个训练图像的ground-truth值集SDD−i都可用,则可以计算每个生成子集的语义F1−sp评分,并且使用最大的
F1−sp
得分来更新参数。这个过程鼓励模型生成与评估度量更一致的标记子集。
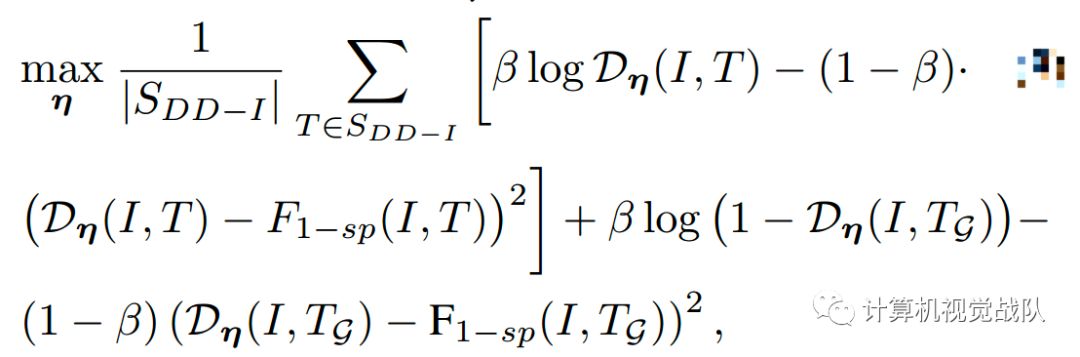
然后,可以计算该公式关于η的梯度,并使用随机梯度上升算法和反向传播来更新η。
实验










