来源:量子位
什么?
Kimi底层推理架构刚刚宣布:开!源!了!
你没听错,就是那个承载了Kimi线上
80%以上
流量的架构。
大约几小时前,月之暗面Kimi联合清华大学等机构,开源了大模型推理架构
Mooncake
。
根据官方介绍,本次开源将采用
分阶段的方式
:
逐步开源高性能KVCache多级缓存Mooncake Store的实现,同时针对各类推理引擎和底层存储/传输资源进行兼容。
其中
传输引擎Transfer Engine
现在已经在GitHub全球开源。
可以看到,Mooncake一经开源,已在GitHub狂揽1.2k star。
其最终开源目标是,为大模型时代打造一种新型高性能内存语义存储的标准接口,并提供参考实现方案。
月之暗面Kimi工程副总裁许欣然表示:
通过与清华大学MADSys实验室紧密合作,我们
共同打造了分离式大模型推理架构Mooncake,实现推理资源的极致优化
。
Mooncake不仅提升了Kimi的用户体验,降低了成本,还为处理长文本和高并发需求提供了有效的解决方案。
我们相信,通过与产学研机构开源合作,可以推动整个行业向更高效的推理平台方向发展。
实际上,这个项目早在今年6月就已启动,当时已受到业内广泛关注——

大模型推理架构Mooncake
今年6月,月之暗面和清华大学MADSys实验室联合发布了Kimi底层的
Mooncake推理系统设计方案
。
在这篇名为《Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving》的论文中,作者详细介绍了Mooncake这种系统架构。
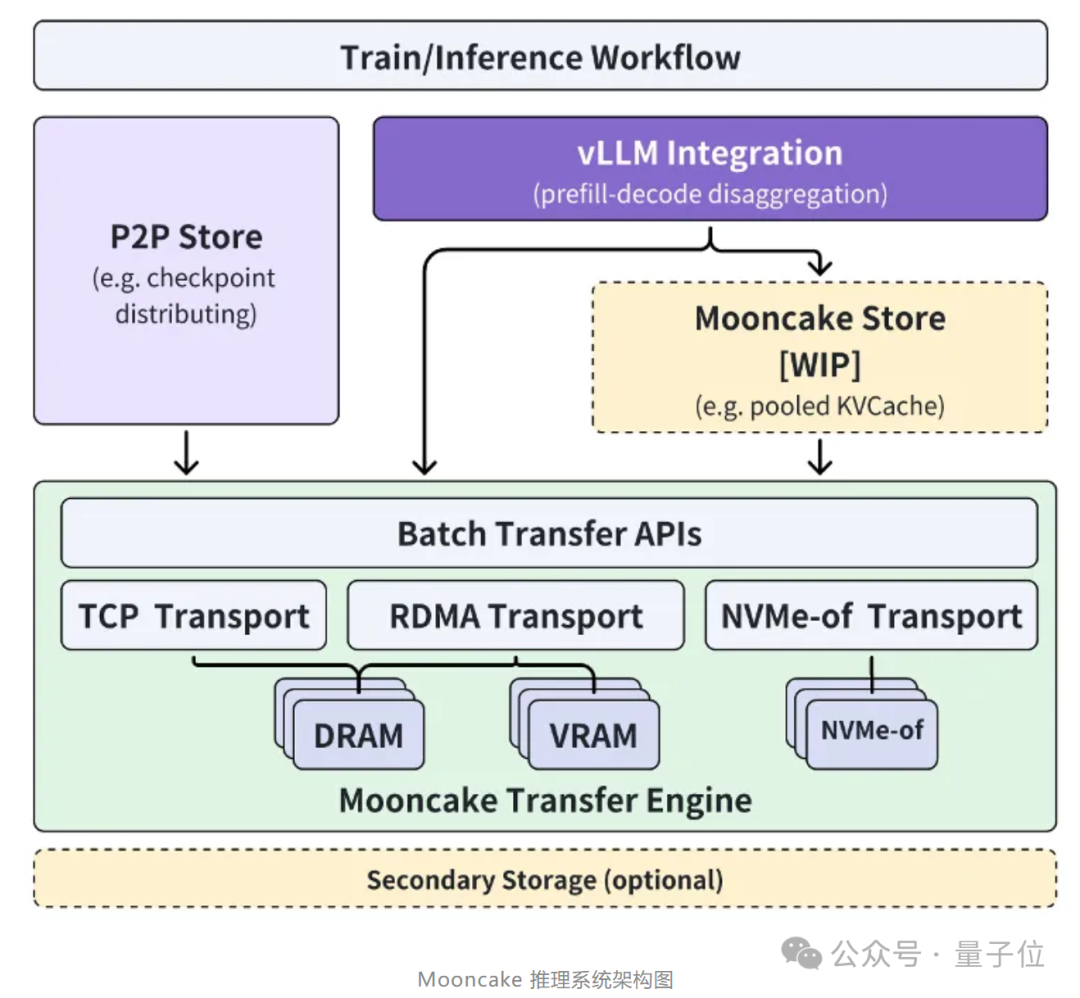
该系统基于以KVCache为中心的PD分离和以存换算架构,大幅度提升了推理吞吐。

具体而言,Mooncake采用以KVCache为中心的解耦架构,将预填充集群与解码集群分离,并充分利用GPU集群中未充分利用的CPU、DRAM和SSD资源,实现KVCache的解耦缓存。
其核心在于
以KVCache为中心
的调度程序:
在最大化整体有效吞吐量和满足与延迟相关的服务级别目标 (SLO) 要求之间取得平衡




