来源
:
实习僧
作者:实习僧的何梁
真正完全搞清楚Python的编码问题
我想大家经常被Python的编码问题搞的晕头转向,下面我一头来自实习僧的牛,为您详细解析这个天坑:
请看图:
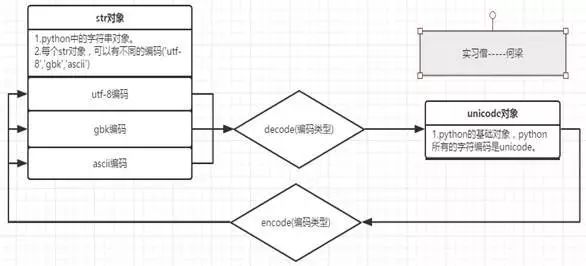
1、python中一切皆对象,字符对象分为两种,一种是unicode对象,一种是str对象。
2、python中字符是unicode为基础的,所以平时我们的字符串,也就是str在python内存中其实是以unicode编码存储的。
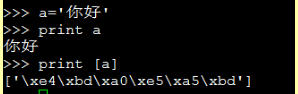
3、所以我们平时print一个字符串的时候,看到的是中文,但是如果你把这个字符串放在list里(就是外面加上[ ]),再print,就能看到原生的编码了。因为前面说了,在python内存存储中都是以unicode存储的,所以放在List里面,打印就能看见原生的存储模式。
4、str是字符串对象,但是可以有很多不同的编码,utf-8,gbk,ascii,都是编码。
5、不同编码的str对象,互相不能直接转换,也就是说utf-8编码的不能直接转换成gbk的。
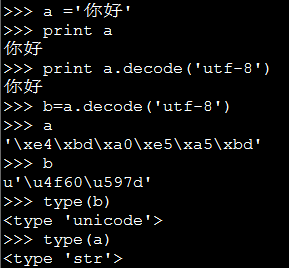
6、但是不同编码的str对象都可以解码成unicode对象,因为一切数据在Python都是以unicode存储的,str.decode(编码类型)
7、unicode对象也可以编码成任意一种编码的str对象。 unicode.encode('编码类型')
8、所以不同编码的str对象可以先解码(decode)成unicode 再编码(encode)成其他编码的str对象。
9、utf-8包含国际上所有字符的编码,GBK主要包含全部中文字符,所以说我们大家爱用utf-8,因为全。
10、所以说utf-8中有一些字符,gbk没有,所以有一些Utf-8解码后再编码成gbk后会报错,因为gbk没有那种字符。
11、有一些str中可能混着有gbk,utf-8等好几种编码,所以有时候decode的时候会报错,因为你按照gbk解码,可能里面又包含了一种不识别的utf-8码得到。
12、以上两条,有没有只编码或者解码对的啊,错误的字符就跳过?
13、有,decode('utf-8','ignore'),encode('utf-8','ignore') 加一个'ignore'参数 就会忽略错误。





