在几年前的文章《
Policy Engine 的前世今生
》里,我谈到了自己探索如何生成高效的表达式求值的工具的整个过程。我先是使用 JISON(javascript 的 Flex/Bison)做了一个解析器(parser),后来又用 Elixir 自己的宏编程进行了优化,让单个表达式的验证从 200+ us 提升到 20+ us。最近无意间看到了 Guido van Rossum 大神的文章 [1],讲他探索 PEG 解析器的历程(Python 3.9 已经实现了新的 PEG parser [2])。于是,这个周末,我花了一个晚上,尝试了用 Rust 下的 PEG 解析器 — pest 重新实现了 policy 表达式解析器部分,为了更好地对比 pest 和 Rust 下的另外一个神器 nom 的效果,我也同时实现了 nom 下的 policy 表达式解析器。
本文讲讲我在使用这两个工具过程中的心得。如果大家对解析器还知之甚少,可以看我之前的文章《
如何愉快地写个小parser
》,以及 A Guide to Parsing: Algorithms and Terminology [3],它是对各种 parser 的一个非常棒的总结。
PEG, CFG 和 Parser Combinator
在正式开始之前,先简单讲讲几个概念(我知道你们不太会看参考文献滴)。
PEG - Parsing Expression Grammar,是一种分析性形式文法,在 2004 年推出。它的语法和 CFG - Context Free Grammar 很类似。我们之前用的 BNF 工具(比如 Flex/Bison)用于撰写解析 CFG。PEG 和 CFG 的主要区别是:PEG 会在语法歧义发生时总选择第一个匹配项,而 CFG 则是未定义的。所以,PEG 总会只生成一棵满足规则的语法树,而 CFG 有可能产生多棵,需要开发者手动消歧。
比如下面的例子[4]:
定义:
if_statement := "if" "(" expr ")" statement "else" statement | "if" "(" expr ")" statement;
输入:if (x1) if (x2) y1 else y2
这个输入可以有两种解释:
if_statement(x1, if_statement(x2, y1, y2)) if_statement(x1, if_statement(x2, y1), y2)
PEG 只会选择第一种,而 CFG 会产生解析冲突(开发者需要消除歧义)。
PEG/CFG 对应的工具都属于 Parser Generator 的范畴。因为一般手写解析器是一件非常枯燥且容易出错的行为,所以会有符合 PEG/CFG 的比较抽象的语言产生,专门用于描述语法,而用这种语言写出来的代码最后会被编译成解析器代码,所以叫 Parser Generator。
Parser Combinator 是和 Parser Generator 平行的概念。如果我们把解析器看成一幢大楼的话,用 Parser Generator 我们每次都几乎从零开始构建这个大楼,大楼和大楼之间相似的部分(如门窗)无法复用;而 用 Parser Combinator 就像搭乐高积木 — 我们不断构建小的,可复用的,可测试的组件,然后用这些组件来构建大楼。当我们要构建新的大楼时,之前创建的组件可以拿来使用,非常方便。
Parser Combinator 最早出现于 Haskell 社区的 Parsec,因为它的思路实在是太优美,太符合软件工程的思想了,于是后来 Parsec 在各个语言遍地开花,比如我之前介绍过的 Elixir 下的 nimble_parsec,以及今天我们要涉及的 nom。
多说两句 Parser Combinator。在 Parsec 问世之前,写应用软件的方法论比写解析器先进了整整一代。应用软件强调的代码的可测试,可组装,可复用,可重构等要素在解析器中的代码中很难应用,所有的解析器都是撰写起来不简单,维护起来非常困难,读复杂的没有文档的解析器就跟读天叔一样,添加功能或者修改 bug 更是要了老命,往往很小一个改动都会伤筋动骨。Parsec 的出现弥合了这个差距:开发者可以一个部分一个部分地实现解析器,每个部分可以单独测试,最后将其组装起来即可。这样大大提升了开发和维护的效率。
使用 pest 实现解析器
我们以下面的表达式为例:
country in ["US", "CA"] and ( (date > 01/01/2021 and date <= 02/01/2021) or (date > 03/01/2021 and date <= 05/01/2021))
使用 pest,这个语法大概 20 行就可以描述:
WHITESPACE = _{ " " | "\t" | "\r" | "\n" }
policy = _{ SOI ~ expr ~ (logic_op ~ expr)* ~ EOI }
expr = _{ sub_expr | sub_expr_group }
logic_op = { "and" | "or" }
sub_expr_group = { ... }
sub_expr = { name ~ op ~ value }
name = @{ "platform" | "country" | "date" | ... }
op = @{ "==" | ">=" | ... }
array = { "[" ~ value ~ ("," ~ value)* ~ "]" }
value = _{ date | ("\"" ~ string ~ "\"") | array }
string = @{ ASCII_ALPHA* }
date = ${ md ~ "/" ~ md ~ "/" ~ year }
md = { ASCII_DIGIT{1,2} }year = { ASCII_DIGIT{4} }
代码并不难懂。
我采用了自顶向下的方式来描述这个语法。首先,我让所有的空格自动解析,自动忽略。
然后是顶层的逻辑:policy 从输入开始(Start Of Input),读取一个表达式(expr),后接 任意多的逻辑运算符( logic op)和表达式(expr),最后输入结束(End Of Input)。
那么表达式长什么样?表达式是不带括号的子表达式(sub_expr)或者带括号的子表达式(sub_expr_group),二选一。
那么不带括号的子表达式长什么样?变量名(name)+ 操作符(op)+ 值(value)。
剩下的我就不一一赘述了,很好理解。
我们可以看到,pest 声明的语法结构和 Bison 很像。为了方便解析和生成合适的语法树,pest 提供了一些方法可以控制哪些内容在语法树中生成:
写好的规则存成文件(比如 expr.pest)后,可以在 Rust 代码里这么引用:
#[derive(Parser)]
#[grammar = "expr.pest"]pub struct ExprParser;
然后,就可以生成语法树了:
let result = ExprParser::parse(Rule::policy, "date > 1/1/2021").unwrap();
生成的语法树如下:
[ Pair { rule: sub_expr, span: Span { str: "date > 1/1/2021", start: 0, end: 15, }, inner: [ Pair { rule: name, span: Span { str: "date", start: 0, end: 4, }, inner: [], }, Pair { rule: op, span: Span { str: ">", start: 5, end: 6, }, inner: [], }, Pair { rule: date, span: Span { str: "1/1/2021", start: 7, end: 15, }, inner: [ Pair { rule: md, span: Span { str: "1", start: 7, end: 8, }, inner: [], }, Pair { rule: md, span: Span { str: "1", start: 9, end: 10, }, inner: [], }, Pair { rule: year, span: Span { str: "2021", start: 11, end: 15, }, inner: [], }, ], }, ], }, Pair { rule: EOI, span: Span { str: "", start: 15, end: 15, }, inner: [], },]
pest 提供了一系列的工具来遍历和处理语法树,比如我们要处理 sub_expr:
fn eval_sub_expr(mut rules: Pairs, context: &Context) -> bool { let name = rules.next().unwrap().as_str(); let op = rules.next().unwrap().as_str(); let value = rules.next().unwrap(); match value.as_rule() { Rule::string => ..., Rule::date => ..., Rule::array => ... }}
有关 pest 的更多说明,见 pest.rs。
使用 nom 来实现解析器
在使用 nom 之前,我有初级的 nimble_parsec 的使用经验,做过 csv / json 等实验性的解析器。
因为都是 parser combinator,nom(我用的是 version 6.x)的使用体验和 nimble_parsec 几乎一致,比较容易上手。这里需要吐槽一下的是,nom 的文档实在是太缺乏了,网上搜到的几乎都过时了(因为 nom 5 做过一次大的重写,几乎抛弃了之前的使用宏来构造 parsec 的方式),就连 nom 自己 github 里的文档都是过时的,唯一有效的文档是 doc.rs/nom 以及源码。我写 nom 的过程主要在 docs.rs/nom 里边搜索边写的。如果你没有 parsec 的经验,建议先看看比较通用的 parser combinator 的介绍,比如[5]。
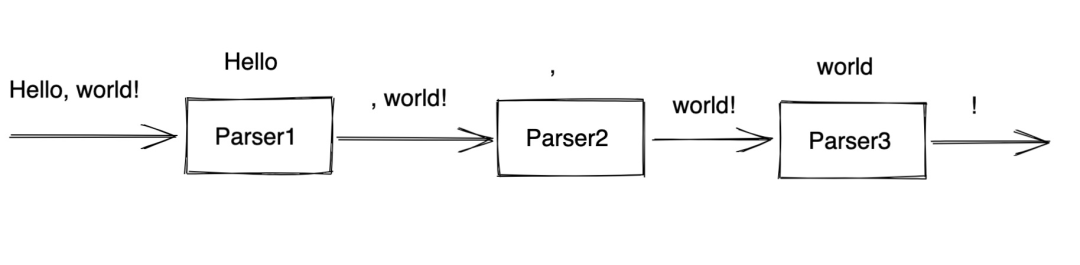
前文说过,用 parser combinator 的感觉就像搭积木,比如要解析
Hello, world!
,可以写三个小 parser,然后将其组合起来。如下图:
比如我要解析表达式里的
and
和
or
这样的逻辑表达式:
fn logic_op(input: &str) -> IResult { delimited(multispace0, alt((tag("and"), tag("or"))), multispace0)(input)}
这段代码的
delimited
combinator 是说前后的空格忽略,只取中间的内容。然后
alt
是从一组 combinators 里选择任意一种满足的情况。这里我们尝试匹配
and
或者
or
,用
tag
combinator 来描述。当
logic_op
运行完之后,它会
吃掉
输入从头开始的任何空白字符,以及随后的 and/or,以及之后的任意空白字符,然后返回 input 剩下的部分,以及匹配到的 and/or。
我们再看数组的匹配,比如这样一个数组
["hello", "world"]
。我们先用
delimited
忽略前后的语法单元
[]
,然后把所有的内容捕获到一个按逗号分隔的列表中。这是
separated_list1(tag(","), string)
所表达的。在 nom 里,一个 combinator 结尾 0 或者 1 代表它匹配 0 到多次,还是 1 到多次。
separated_ist1
里的第二个参数
string
是一个 combinator,用于匹配输入中的带引号的字符串。注意这里为了简化起见,我并没有处理 string escape:
fn array(input: &str) -> IResult { let (input, r) = delimited(tag("["), separated_list1(tag(","), string), tag("]"))(input)?; Ok((input, ExprValue::Array(r)))}
fn string(input: &str) -> IResult { delimited( preceded(multispace0, tag("\"")), alpha0, terminated(tag("\""), multispace0), )(input)}
可以看到 nom(或者任何 parser combinator)和 pest(或者任何 parser generator)撰写代码的思路类似,只不多 nom 用一个个函数来表达语法,而 pest 用 DSL 来描述语法。
pest 和 nom 的性能对比
在 pest 官网上,作者非常谦虚地附上了和 nom / serde 在解析 JSON 上的性能对比。可以看到 nom 比较接近 serde(rust 里 serde-json 的性能是顶级的存在 [6]),而 pest 还差得很远:










