
作者 | 翁嘉颀
编译 | 姗姗
出品 | 人工智能头条(公众号ID:
AI_Thinker
)
【导读】在人机交互过程中,人通过和计算机系统进行信息交换,信息可以是语音、文本、图像等一种模态或多种模态。对人来说,采用自然语言与机器进行智能对话交互是最自然的交互方式之一,但这条路充满了挑战,如何机器人更好的理解人的语言,从而更明确人的意图?如何给出用户更精准和不反感的回复?都是在人机交互对话过程中最为关注的问题。对话系统作为NLP的一个重要研究领域受到大家越来越多的关注,被应用于多个领域,有着很大的价值。
本期大本营公开课,我们邀请到了竹间智能的 CTO 翁嘉颀老师,他将通过对技术方法通俗易懂的讲解和Demo 演示相结合的方式为大家讲解本次课题,本次课题主要包含一些几个内容:
1.上下文理解技术——补全与指代消解
2.上下文理解技术——对话主题式补全
3.NLU的模块架构及如何利用NLU的基础信息
4.Live Demo 演示
5.人机交互的案例分享与研究发展趋势
6. Q & A
以下是公开课文字版整理内容
▌
前言
我从1982年开始坐在电脑前面,一直到现在。上一次做人工智能是27年前,大概1991年的时候,那个时候做人工智能的人非常可怜 ,因为做什么东西都注定做不出来,随便一个机器学习的训练、神经网络训练需要20天,调个参数再重新训练又是20天,非常非常慢。电脑棋类我除了围棋没做以外,其他都做了,本来这辈子看不到围棋下赢人,结果两年前看到了。后来做语音识别,语音识别那个年代也都是玩具,所以那个年代做人工智能的人最后四分五裂,因为根本活不下去,后来就跑去做搜索引擎、跑去做金融、跑去做其他的行业。
这次人工智能卷土重来,真的开始进入人类生活,在周边地方帮上我们的忙。今天我来分享这些人机交互的技术到底有哪些变化。

先讲“一个手环的故事”,这是一个真实的故事,我们在两年前的4月份曾经想要做这个,假设有一个用户戴着手环,“快到周末了,跟女朋友约会,给个建议吧”。背后机器人记得我的一些事情,知道我过去的约会习惯是看电影,还是去爬山,还是在家打游戏、看视频。如果要外出的话,周末的天气到底怎样,如果下大雨的话那可能不适合。

而且它知道我喜欢看什么电影、不喜欢看什么电影、我的女朋友喜欢看什么、不喜欢看什么,它甚至知道我跟哪一个女朋友出去,喜欢吃什么,不喜欢吃什么,餐厅的价位是吃2000块一顿,还是200块一顿,还是30块一顿的餐馆,然后跟女朋友认识多久了,刚认识的可能去高档一点的地方,认识6年了吃顿便饭就和了,还有约会习惯。
有了这些东西之后,机器人给我一个回应,说有《失落 的世界2》在某某电影院,这是我们习惯去的地方,看完电影,附近某家餐馆的价位和口味 是符合我们的需要。我跟它说“OK,没问题”,机器人就帮我执行这个命令,帮我买电影票、帮我订餐馆、周末时帮我打车,甚至女朋友刚认识,买一束花放在餐馆的桌上。
我们当时想象是做这个。这个牵扯到哪些技术?第一,有记忆力,你跟我讲过什么东西,我能记得。还包括人机交互,我今天跟它讲“周末是女朋友生日 ,订个好一点的吧。”它能帮我换个餐馆,能理解我的意思。
如果手环能够做到这个样子,你会觉得这个手环应该是够聪明的,这个机器人是够聪明的,能够当成 你的助手陪伴你。最后,我们并没有做出来,我们做到了一部分,但是有一部分并没有做到。
我们公司的老板叫Kenny,他之前是 微软亚洲互联网工程院副院长,负责小冰及cortana的,老板是做搜索引擎出身的,我以前也是做搜索引擎的,做了11年。左下角的曹川在微软做搜索引擎。右上角在微软做搜索引擎。右下角在谷歌做搜索引擎。目前的人工智能很多是 搜索引擎跑回来的,因为搜索引擎也是做语义理解、文本 分析,和人工智能的文本 分析有一定的相关度。
▌
人机交互的发展
一开始都是一些关键词跟模板的方式,我最常举的例子,我桌上有一个音箱,非常有名的一家公司做的,我今天跟这个音箱说“我不喜欢吃牛肉面”,音箱会抓到关键词“牛肉面”,它就跟我说“好的,为您推荐附近的餐馆”,推荐给我的第一个搞不好就是牛肉面。我如果跟它说“我刚刚吃饭吃很饱”,关键词是“吃饭”,然后它又说“好的,为您推荐附近的餐馆”,所以用关键词的方式并不是不能做,它对语义意图理解的准确率可能在七成、七成五左右,也许到八成,但有些东西它是解不了的,因为它并不是真的理解你这句话是什么意思。所以要做得好的话,必须用自然语言理解的方式,用深度学习、强化学习,模板也用得上,把这些技术混搭在一起,比较有办法理解你到底要做什么事情。
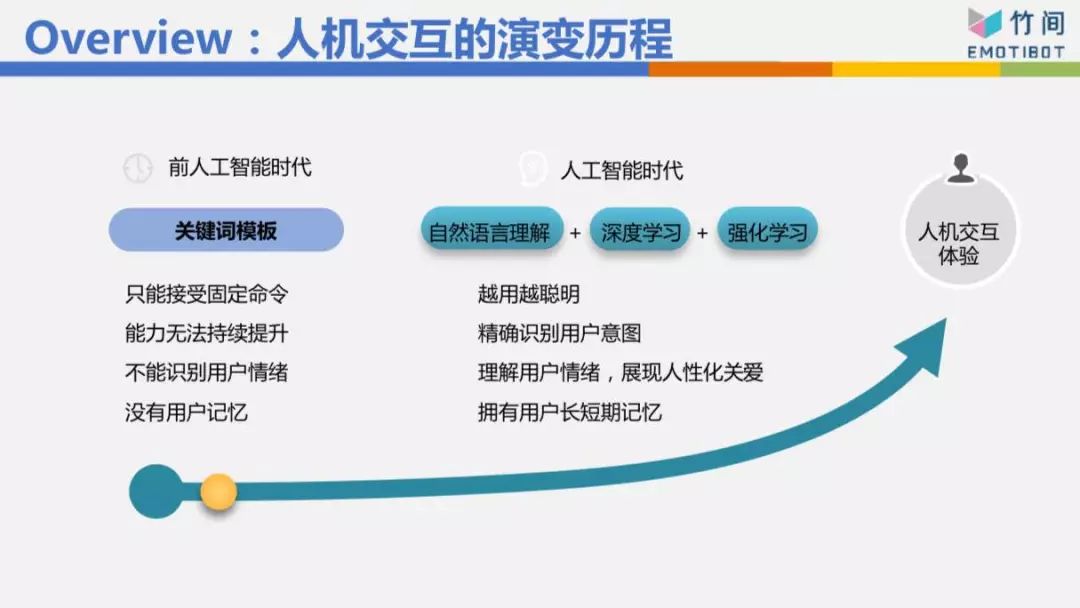
这个Chatbot的演变历程我们不细讲,但我今天要表达,在人机交互里面或者语义理解上面,我们分成三个层次。
最底层的叫自然语言理解
,举例来说,我现在想说“我肚子饿”跟“我想吃东西”这两句话的句法、句型不太一样,所以分析的结果也不太一样,这是最底层的。
第二层叫“意图的理解”
,这两句话虽然不一样,但它们的意图是一致的,“我肚子饿”跟“我想吃东西”可能代表我想知道附近有什么餐馆,或者帮我点个外卖,这是第二层。目前大家做的是第一层跟第二层。
其实还有第三层,第三层就是这一句话背后真正的意思是什么
,比如我们在八点上这个公开课,我突然当着大家的面说“我肚子饿”跟“我想吃东西”,你们心里会有什么感受?你们心理是不是会觉得我是不是不耐烦、是不是不想讲了。你的感受肯定是负面的。今天如果我对着一个女生说“我肚子饿”,女生心里怎么想?会想我是不是要约她吃饭,是不是对她有不良企图。目前大家离第三层非常遥远,要走到那一步才是我们心目中真正要的AI,要走到那一步不可避免有情绪 、情感的识别、情境的识别、场景的识别、上下文的识别。
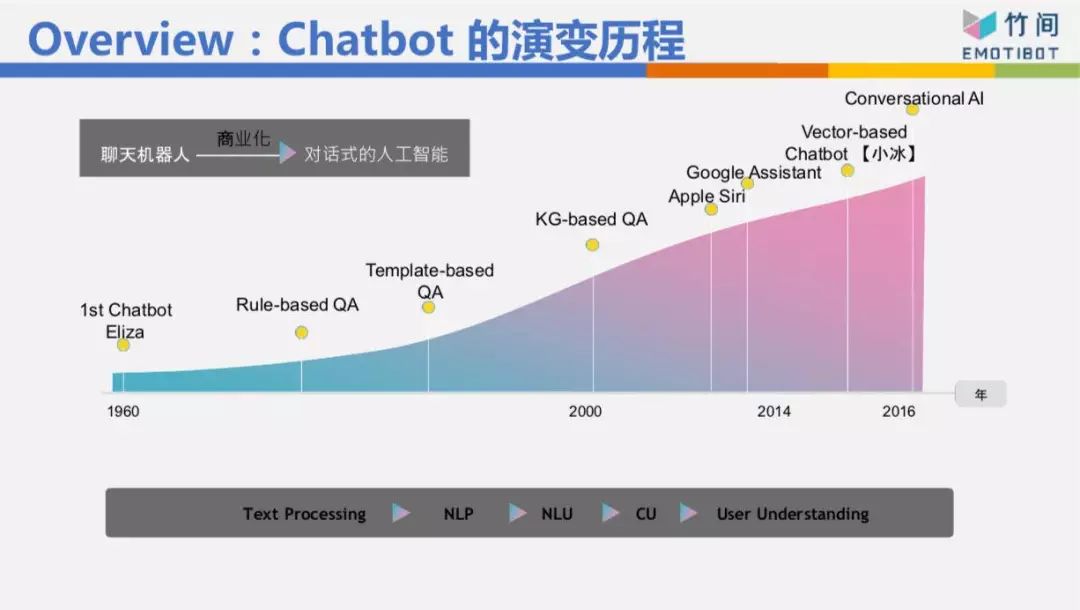
我们公司的名字叫“EMOTIBOT”,情感机器人,我们一开始创立时就试着把情绪 情感 的识别做好。我们情绪情感识别,光文字做了22种情绪 ,这非常变态 ,大部分公司做的是“正、负、中”三种,但是你看负面的情绪 ,有反感、愤怒、难过、悲伤、害怕、不喜欢、不高兴,这些情绪 都是负面的,但是它不太一样,我害怕、我悲伤、 我愤怒,机器人的反馈方式应该是不一样的。
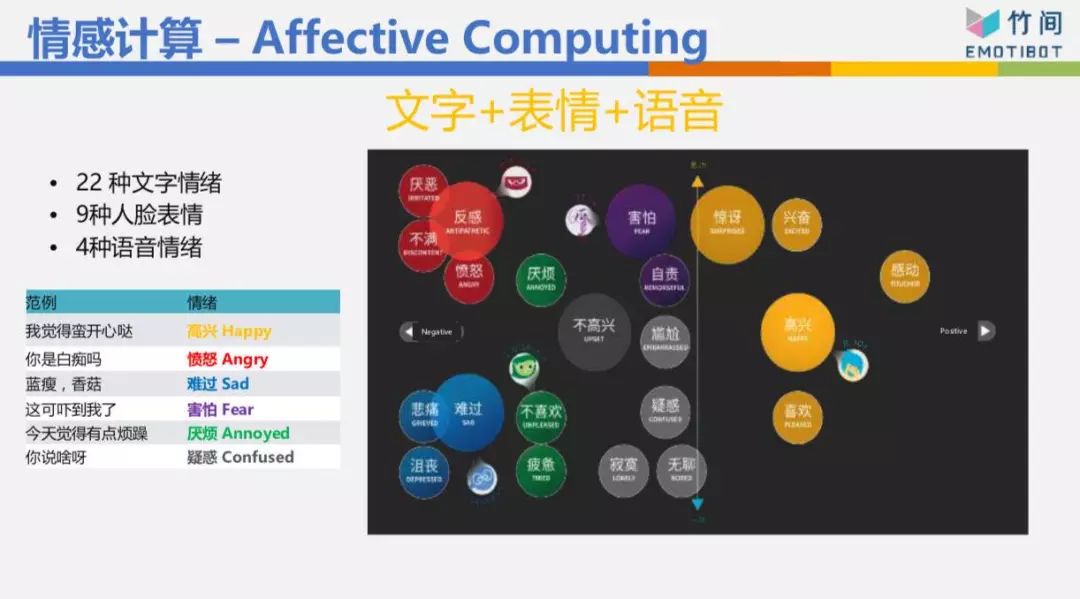
人脸表情我们做了9种,语言情绪 我们做了4种。而且我们做最多的是把这些情绪混合在一起做了多模态的情感。举个例子,像高考光结束,我今天看了一段文字:“我高考考了500分”,你看了这段文字不知道该恭喜我还是安慰我。这时要看讲话的语气,如果我的语气是说“哦,我高考考了500分。”你一听就知道我是悲伤的,所以会安慰我。所以通常语音情感 比文字情感 来得更直接。
然后人脸表情加进来,三个加在一起,又更麻烦了。我们来看一段视频,我用桌面 共享。(视频播放)“鬼知道我经历了什么”,文字上是匹配的——我已经要死了、生不如死,我的文字是愤怒的,但我的语音情绪跟脸表情是开心的,所以我的总情绪 仍然是开心的。这是把人脸表情、语音情绪 、文字情绪 混搭在一起做出来的多模态情感。

▌
上下文理解技术
接下来进入比较技术面的部分,讲话聊天时,任务型的机器人一定牵扯到上下文的理解技术。
什么叫上下文理解技术?
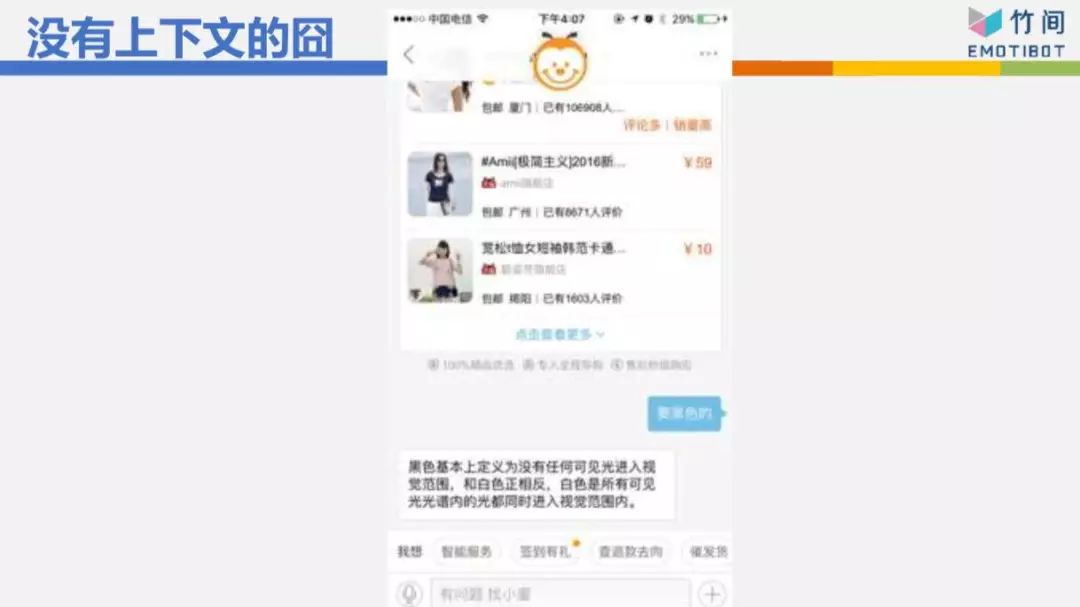
这是某个电商网站,我前面一句话跟它说“我要买T恤”,它给我3件T恤,我跟它说“要黑色的”,意思是我要黑色的那件T恤,但它完全不理解我的意思,因为没有上下文。所以它居然在跟我解释黑色的基本定义是什么,是因为不返色,所以你看不到光,所以它是黑色的。这完全不是我要的东西,所以没有上下文时,它的反应常常啼笑皆非。
我们来看看上下文怎么做,上下文有几种做法。第一种是补全与指代消解,像说“明天上海会不会下雨”,回答了“明天上海小雨”,“那后天呢”缺了主谓宾等一些东西,所以往上去找,把它补全,把“那后天呢”改成“后天上海会不会下雨”,然后机器人就有办法处理。

指代消解也是“我喜欢大张伟”,然后机器人回答说“我也喜欢他”,“他”是谁?这个代名词,我知道“他”是大张伟,所以把“我也喜欢他”改成“我也喜欢大张伟”,这样才有办法去理解。然后那个人就说“最喜欢他唱得《倍儿爽》”,那他是谁?要把它改成写“最喜欢大张伟唱的《倍儿爽》”。这两个是基本的东西,基本上每家公司都能够做得到。

然后我们看难一点的东西,
可以不可以做对话主题式补全
?这个开始有一些上下文在里面,“我喜欢大张伟”,第一句话目前的对话主题是大张伟,然后它回答说“对啊,我也喜欢他”改成“我也喜欢大张伟”,这没问题。
第二句话是“喉咙痛怎么办?”这有两种可能,因为我现在的对话主题是大张伟,所以可能是“喉咙痛怎么办”,也可能是“大张伟喉咙痛怎么办”,这时候怎么办?我到底应该选哪一个?先试第一个“喉咙痛怎么办”,居然就可以找到答案了,我知道能够找到好的答案,我就回答了“喉咙痛就多喝开水”,目前的对话主题也变成喉咙痛。
第三个是“他唱过什么歌?”这个他到底是谁?有两个对话主题,一个是喉咙痛,一个是大张伟,有可能是“喉咙痛他唱过什么歌”或者“大张伟他唱过什么歌”。因为优先,最近的对话主题是喉咙痛,所以我先看第一个,但是一找不到答案,所以我再去看第二个“大张伟唱过什么歌”,那我知道大张伟唱过歌,所以他唱过《倍儿爽》,我就可以回答,这是对话主题式补全。

另外,利用主题做上下文对话控制。像现在在世界杯,我问你“你喜欢英超哪支球队?”我的主题是“运动”底下的“足球”底下的“五大联赛”底样。的“英超”,我可以回答“我喜欢巴萨”,你问我英超,我回答西甲,这没有什么太大的毛病,虽然最底下的对话主题不太一样,但是前面是一样的。或者你问我足球,我可不可以回答篮球,“我比较喜欢看NBA”,这可能不太好,但是也不至于完全不行。如果我回答说“我喜欢吃蛋炒饭”这肯定是不对的,因为你问我的是运动体育里面的东西,我居然回答美食。

这个对话主题我可不可以根据上下文主题,去生成等一下那句回答应该是什么主题?我可以根据上下文去猜测等一下你的下一句回答应该有哪些关键词,我可以根据上下文猜出你下一句是什么句型,是肯定句还是正反问句。我有了关键词、有了句型、有了主题,我可以造句,造出一句回答,这也是上下文解法的一种。或者我什么东西都不管,我直接根据上下文用生成式的方式回你一句话。这个目前大家还在研究发展之中,目前的准确度还不是很高,但这是一个未来的发展方向。
▌
NLU的重要性
NLU我们做了12个模块,最基本的当然是分词,然后词性标注,是主词还是动词、形容词称、第二人称、第三人称,然后命名实体
,北京有什么好玩的跟上海有什么好玩的,一个是北京,一个是上海,两个不太一样。然后我如果问“你喜欢吃苹果吗?”“等一下我们去吃麦当劳好不好?”这是一个问句,而且我在问你的个人意见,所以你的回答可能是一个肯定的,可能是一个否定的,也可能反问我一个问句说“等一下几点去吃”,无论如何,你的回答不会跟我讲“早安”或“晚安”,因为我问的是“等一下我们去吃麦当劳好不好。”我们还做了一些奇怪的东西,例如语义角色的标注 ,后面可以看到一些例子。

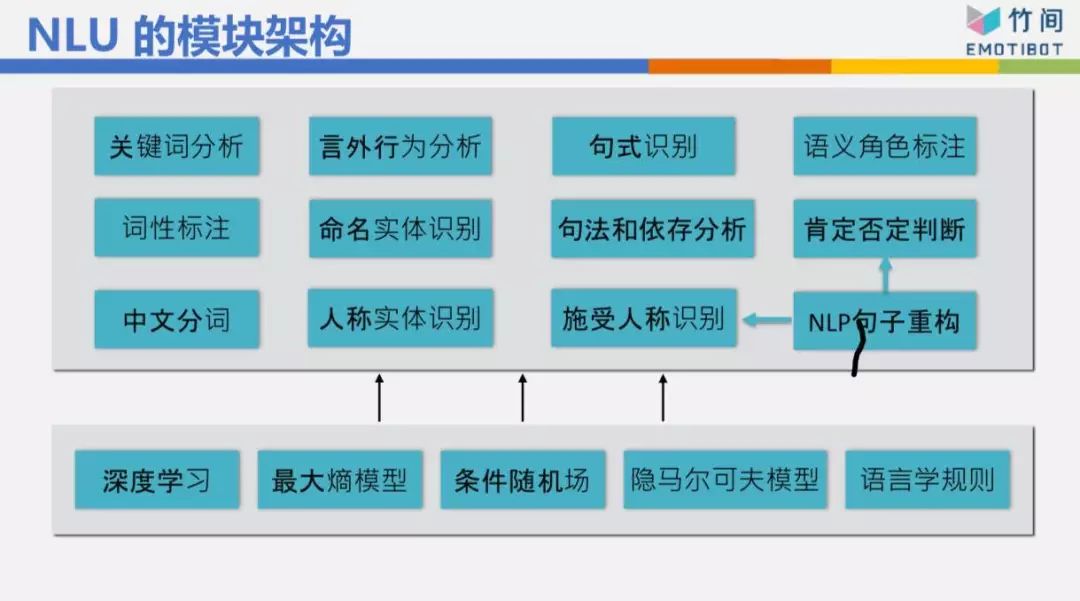
以这个句子来说,“我明天飞上海,住两天,要如家”整个句子的句法结构拆出来,核心动词是“飞、住、要”,把它分出来“我飞”、“飞上海”、“住两天”、“要如家”,有了这些核心动词,我知道我的意图不是订机票,如果只有“我明天飞上海”,我的意图可能是订机票,但是因为有后面的“住两天”跟“要如家”,所以根据这些东西判断出来我的意图是订酒店,根据这些东西算出来:明天入住,3天后离店,都市是上海,酒店名称叫如家酒店。整个东西就可以把它解析出来。
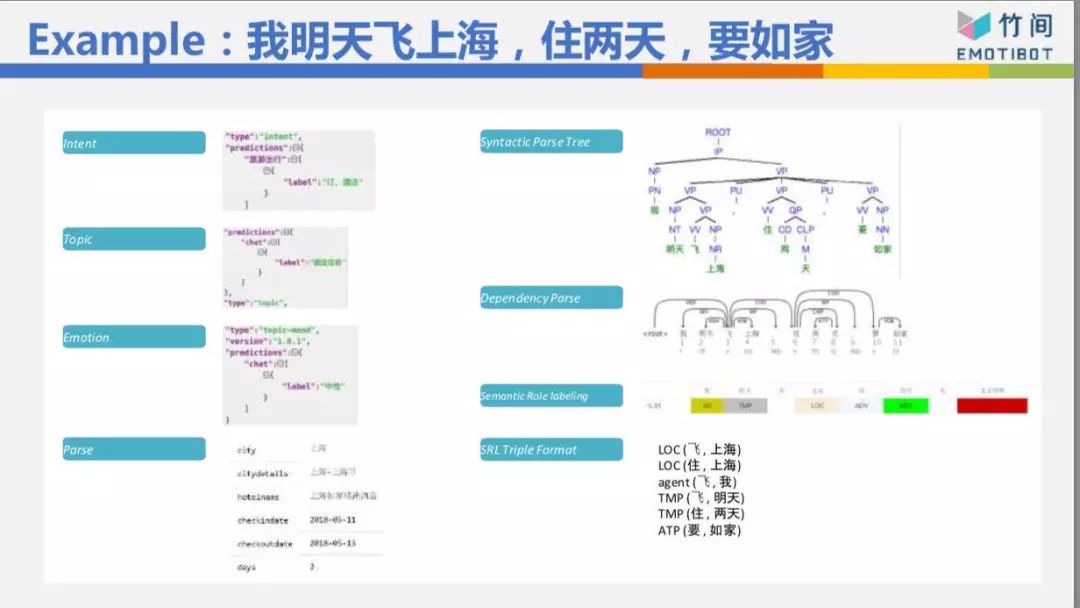
这样的解法跟深度学习黑盒子最大的差别是,这样的解法先把句子拆成一些零件,拆成一些基本的信息,我再根据这些信息,可能以深度学习的方式判断你的意图、对话主题,这样我的数据量可以小很多。如果整个大黑盒子,数据量要五十万比、一百万比、两百万比,才能够有一定的准确率。今天我做了足够的拆解,所以我的数据量三万比、五万比就够了,就可以训练出一个还不错的模型。
再介绍一下我如何利用NLU的基础信息,像“上周买衣服多少钱”这句话,我从Speach Act知道这是一个问句,是一个question-info,你不是说“上周买衣服花了好多钱”,这不是一个问句,就不需要处理。是一个问句的话,再看它是一个数量问句,还是地点的问句,还是时间的问句,“我什么时候买了这件衣服?”“我在哪里买了这件衣服?”问句不一样,后面知道查哪个数据库的哪张表。根据核心动词“花钱”跟“买衣服”,知道类别 是衣服饰品,不是吃饭、不是交通,由时间知道是“上周”,整个东西就可以帮你算出来。这等于是我一句话先经过NLU的解析,再判断你的意图和细节信息。

▌
多轮对话与机器人平台
像刚刚订酒店那个例子,如果表明“我要订酒店”,订酒店有8个信息要抽取,这时机器人要跟你交流:你要订哪里的酒店、几号入住、几号离店、酒店名称、星级、价格等等这一堆东西。今天我们的用户不会乖乖回答。“你要订哪里的酒店?”他可能乖乖跟你说“上海的”、“北京的”,它也可能跟你说“我明天飞上海,住两天,要如家”,他一句话就告诉我四个信息,所以基本用填槽的方式,有N个槽要填。然后看看这句话里面有哪些信息,把它抽取出来,填到相对应的槽,再根据哪几个槽缺失信息决定下一轮的问句该问什么问题,这样比较聪明。举例来说,“我想要买一个理财产品”,“您需要是保本还是不保本?”我只问你保本还是不保本,结果他一次回答“保本的,一年的,预期收益不低于5个点。”他一次告诉我3个 信息,而且3个信息已经够了,我就直接帮你推荐,不用再问你“你要一年、半年还是两年的?”这样的机器人看起来就很傻。

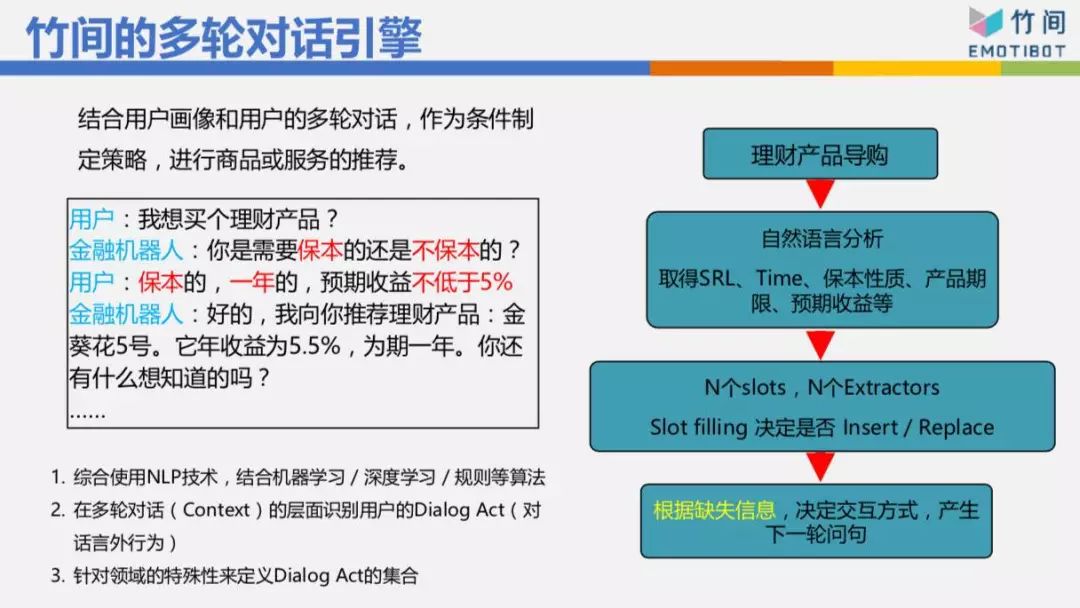
我们来看一些Live Demo的东西


第一个是对话机器人的定制,如何快速定制自己的机器
人
。
我们先切到共享桌面。在这里,假设我现在创建一个机器人,我的名字“小竹子”,然后我是什么机器人?是一个聊天 的、电商的还是金融机器人?我是一个聊天机器人好了,两个步骤创建完了。然后可以做一些设置,机器人有形象,每个人拿到机器人会说:你是男生还是女生?你晚上睡觉吗?你有没有长脚?你今年几岁?你爸爸是谁?你妈妈是谁?你住在哪里?你问“你是男生是女生”时我回答“我是女生”,可不可以修改?我修改“我是精灵”或者“我没有性别”,保存。保存以后我还没有修改,因为我没有重新建模,我们先来问问看,“你是男生,还是女生?”它还是说“我是女生”。然后“你叫什么名字?”它说“叫小竹子”。我开始问它“明天上海会不会下雨?”“那北京呢?”这上下文代表北京明天会不会下雨,“北京明天有雨”,我再问“那后天呢?”这个上下文,是北京的后天还是上海的后天?应该是北京的后天,因为离北京最近。









